 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Distributed Object-Centric Properties in Self-Supervised Transformers
Mar 27, 2026Self-supervised Vision Transformers (ViTs) like DINO show an emergent ability to discover objects, typically observed in [CLS] token attention maps of the final layer. However, these maps often contain spurious activations resulting in poor localization of objects. This is because the [CLS] token, trained on an image-level objective, summarizes the entire image instead of focusing on objects. This aggregation dilutes the object-centric information existing in the local, patch-level interactions. We analyze this by computing inter-patch similarity using patch-level attention components (query, key, and value) across all layers. We find that: (1) Object-centric properties are encoded in the similarity maps derived from all three components ($q, k, v$), unlike prior work that uses only key features or the [CLS] token. (2) This object-centric information is distributed across the network, not just confined to the final layer. Based on these insights, we introduce Object-DINO, a training-free method that extracts this distributed object-centric information. Object-DINO clusters attention heads across all layers based on the similarities of their patches and automatically identifies the object-centric cluster corresponding to all objects. We demonstrate Object-DINO's effectiveness on two applications: enhancing unsupervised object discovery (+3.6 to +12.4 CorLoc gains) and mitigating object hallucination in Multimodal Large Language Models by providing visual grounding. Our results demonstrate that using this distributed object-centric information improves downstream tasks without additional training.
Rethinking Prompting Strategies for Multi-Label Recognition with Partial Annotations
Sep 12, 2024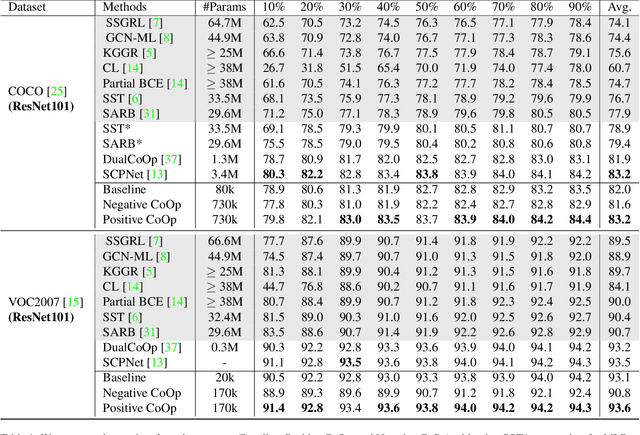
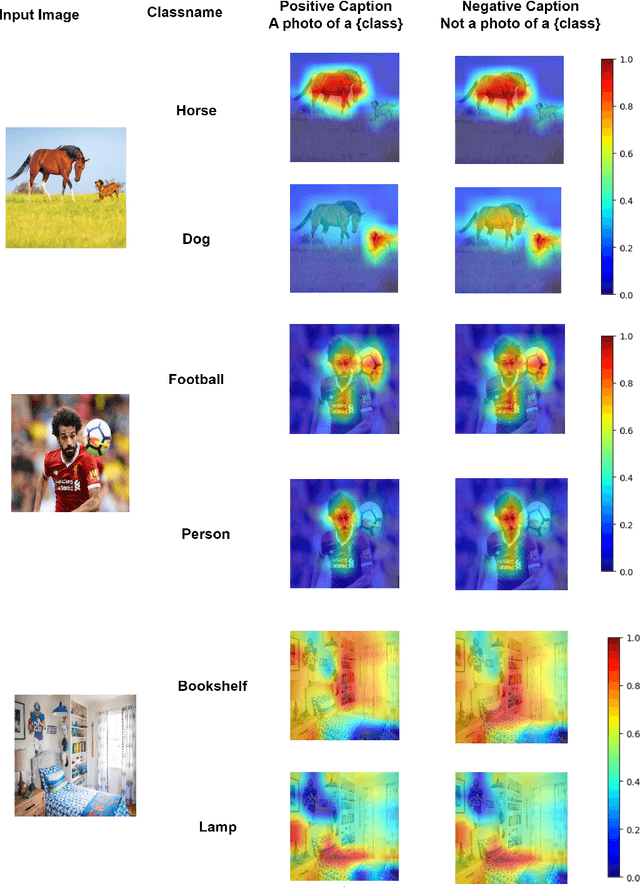
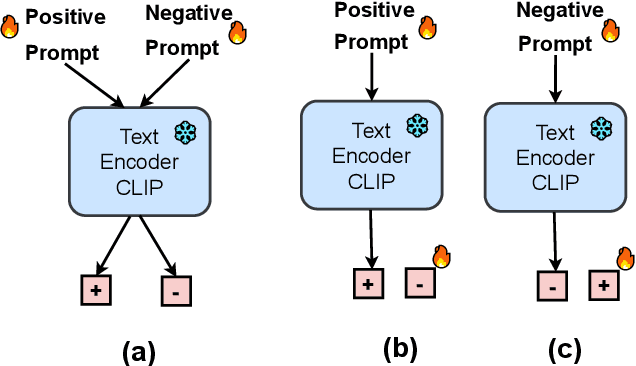
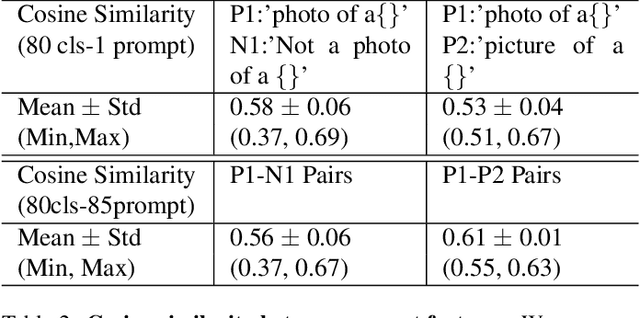
Vision-language models (VLMs) like CLIP have been adapted for Multi-Label Recognition (MLR) with partial annotations by leveraging prompt-learning, where positive and negative prompts are learned for each class to associate their embeddings with class presence or absence in the shared vision-text feature space. While this approach improves MLR performance by relying on VLM priors, we hypothesize that learning negative prompts may be suboptimal, as the datasets used to train VLMs lack image-caption pairs explicitly focusing on class absence. To analyze the impact of positive and negative prompt learning on MLR, we introduce PositiveCoOp and NegativeCoOp, where only one prompt is learned with VLM guidance while the other is replaced by an embedding vector learned directly in the shared feature space without relying on the text encoder. Through empirical analysis, we observe that negative prompts degrade MLR performance, and learning only positive prompts, combined with learned negative embeddings (PositiveCoOp), outperforms dual prompt learning approaches. Moreover, we quantify the performance benefits that prompt-learning offers over a simple vision-features-only baseline, observing that the baseline displays strong performance comparable to dual prompt learning approach (DualCoOp), when the proportion of missing labels is low, while requiring half the training compute and 16 times fewer parameters
S3O: A Dual-Phase Approach for Reconstructing Dynamic Shape and Skeleton of Articulated Objects from Single Monocular Video
May 21, 2024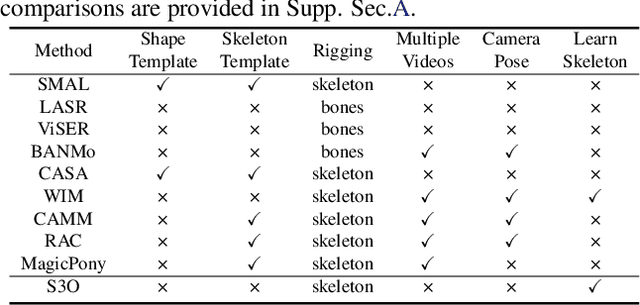


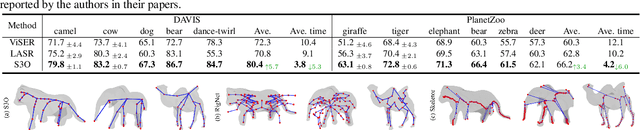
Reconstructing dynamic articulated objects from a singular monocular video is challenging, requiring joint estimation of shape, motion, and camera parameters from limited views. Current methods typically demand extensive computational resources and training time, and require additional human annotations such as predefined parametric models, camera poses, and key points, limiting their generalizability. We propose Synergistic Shape and Skeleton Optimization (S3O), a novel two-phase method that forgoes these prerequisites and efficiently learns parametric models including visible shapes and underlying skeletons. Conventional strategies typically learn all parameters simultaneously, leading to interdependencies where a single incorrect prediction can result in significant errors. In contrast, S3O adopts a phased approach: it first focuses on learning coarse parametric models, then progresses to motion learning and detail addition. This method substantially lowers computational complexity and enhances robustness in reconstruction from limited viewpoints, all without requiring additional annotations. To address the current inadequacies in 3D reconstruction from monocular video benchmarks, we collected the PlanetZoo dataset. Our experimental evaluations on standard benchmarks and the PlanetZoo dataset affirm that S3O provides more accurate 3D reconstruction, and plausible skeletons, and reduces the training time by approximately 60% compared to the state-of-the-art, thus advancing the state of the art in dynamic object reconstruction.
Improving Multi-label Recognition using Class Co-Occurrence Probabilities
Apr 24, 2024



Multi-label Recognition (MLR) involves the identification of multiple objects within an image. To address the additional complexity of this problem, recent works have leveraged information from vision-language models (VLMs) trained on large text-images datasets for the task. These methods learn an independent classifier for each object (class), overlooking correlations in their occurrences. Such co-occurrences can be captured from the training data as conditional probabilities between a pair of classes. We propose a framework to extend the independent classifiers by incorporating the co-occurrence information for object pairs to improve the performance of independent classifiers. We use a Graph Convolutional Network (GCN) to enforce the conditional probabilities between classes, by refining the initial estimates derived from image and text sources obtained using VLMs. We validate our method on four MLR datasets, where our approach outperforms all state-of-the-art methods.
Learning Implicit Representation for Reconstructing Articulated Objects
Jan 16, 2024



3D Reconstruction of moving articulated objects without additional information about object structure is a challenging problem. Current methods overcome such challenges by employing category-specific skeletal models. Consequently, they do not generalize well to articulated objects in the wild. We treat an articulated object as an unknown, semi-rigid skeletal structure surrounded by nonrigid material (e.g., skin). Our method simultaneously estimates the visible (explicit) representation (3D shapes, colors, camera parameters) and the implicit skeletal representation, from motion cues in the object video without 3D supervision. Our implicit representation consists of four parts. (1) Skeleton, which specifies how semi-rigid parts are connected. (2) \textcolor{black}{Skinning Weights}, which associates each surface vertex with semi-rigid parts with probability. (3) Rigidity Coefficients, specifying the articulation of the local surface. (4) Time-Varying Transformations, which specify the skeletal motion and surface deformation parameters. We introduce an algorithm that uses physical constraints as regularization terms and iteratively estimates both implicit and explicit representations. Our method is category-agnostic, thus eliminating the need for category-specific skeletons, we show that our method outperforms state-of-the-art across standard video datasets.
Feature Compression for Rate Constrained Object Detection on the Edge
Apr 15, 2022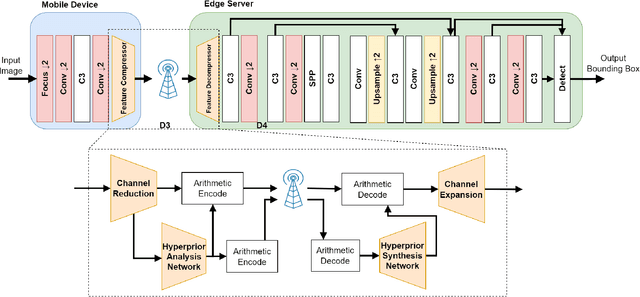

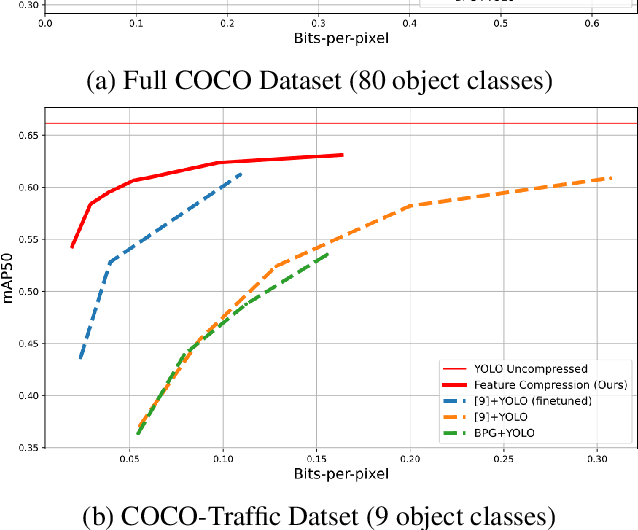
Recent advances in computer vision has led to a growth of interest in deploying visual analytics model on mobile devices. However, most mobile devices have limited computing power, which prohibits them from running large scale visual analytics neural networks. An emerging approach to solve this problem is to offload the computation of these neural networks to computing resources at an edge server. Efficient computation offloading requires optimizing the trade-off between multiple objectives including compressed data rate, analytics performance, and computation speed. In this work, we consider a "split computation" system to offload a part of the computation of the YOLO object detection model. We propose a learnable feature compression approach to compress the intermediate YOLO features with light-weight computation. We train the feature compression and decompression module together with the YOLO model to optimize the object detection accuracy under a rate constraint. Compared to baseline methods that apply either standard image compression or learned image compression at the mobile and perform image decompression and YOLO at the edge, the proposed system achieves higher detection accuracy at the low to medium rate range. Furthermore, the proposed system requires substantially lower computation time on the mobile device with CPU only.