 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTumorFlow: Physics-Guided Longitudinal MRI Synthesis of Glioblastoma Growth
Mar 05, 2026Glioblastoma exhibits diverse, infiltrative, and patient-specific growth patterns that are only partially visible on routine MRI, making it difficult to reliably assess true tumor extent and personalize treatment planning and follow-up. We present a biophysically-conditioned generative framework that synthesizes biologically realistic 3D brain MRI volumes from estimated, spatially continuous tumor-concentration fields. Our approach combines a generative model with tumor-infiltration maps that can be propagated through time using a biophysical growth model, enabling fine-grained control over tumor shape and growth while preserving patient anatomy. This enables us to synthesize consistent tumor growth trajectories directly in the space of real patients, providing interpretable, controllable estimation of tumor infiltration and progression beyond what is explicitly observed in imaging. We evaluate the framework on longitudinal glioblastoma cases and demonstrate that it can generate temporally coherent sequences with realistic changes in tumor appearance and surrounding tissue response. These results suggest that integrating mechanistic tumor growth priors with modern generative modeling can provide a practical tool for patient-specific progression visualization and for generating controlled synthetic data to support downstream neuro-oncology workflows. In longitudinal extrapolation, we achieve a consistent 75% Dice overlap with the biophysical model while maintaining a constant PSNR of 25 in the surrounding tissue. Our code is available at: https://github.com/valentin-biller/lgm.git
R2I-rPPG: A Robust Region of Interest Selection Method for Remote Photoplethysmography to Extract Heart Rate
Oct 21, 2024



The COVID-19 pandemic has underscored the need for low-cost, scalable approaches to measuring contactless vital signs, either during initial triage at a healthcare facility or virtual telemedicine visits. Remote photoplethysmography (rPPG) can accurately estimate heart rate (HR) when applied to close-up videos of healthy volunteers in well-lit laboratory settings. However, results from such highly optimized laboratory studies may not be readily translated to healthcare settings. One significant barrier to the practical application of rPPG in health care is the accurate localization of the region of interest (ROI). Clinical or telemedicine visits may involve sub-optimal lighting, movement artifacts, variable camera angle, and subject distance. This paper presents an rPPG ROI selection method based on 3D facial landmarks and patient head yaw angle. We then demonstrate the robustness of this ROI selection method when coupled to the Plane-Orthogonal-to-Skin (POS) rPPG method when applied to videos of patients presenting to an Emergency Department for respiratory complaints. Our results demonstrate the effectiveness of our proposed approach in improving the accuracy and robustness of rPPG in a challenging clinical environment.
Parallel Backpropagation for Inverse of a Convolution with Application to Normalizing Flows
Oct 18, 2024
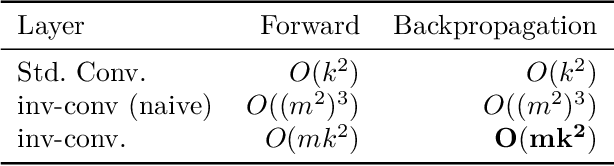
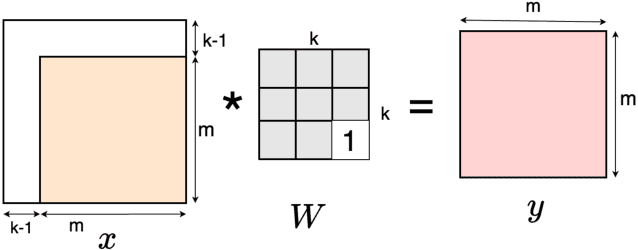
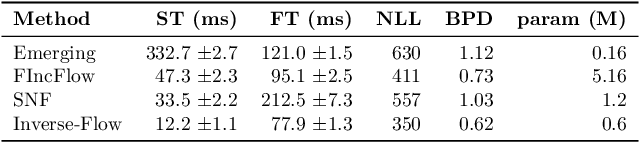
Inverse of an invertible convolution is an important operation that comes up in Normalizing Flows, Image Deblurring, etc. The naive algorithm for backpropagation of this operation using Gaussian elimination has running time $O(n^3)$ where $n$ is the number of pixels in the image. We give a fast parallel backpropagation algorithm with running time $O(\sqrt{n})$ for a square image and provide a GPU implementation of the same. Inverse Convolutions are usually used in Normalizing Flows in the sampling pass, making them slow. We propose to use Inverse Convolutions in the forward (image to latent vector) pass of the Normalizing flow. Since the sampling pass is the inverse of the forward pass, it will use convolutions only, resulting in efficient sampling times. We use our parallel backpropagation algorithm for optimizing the inverse convolution layer resulting in fast training times also. We implement this approach in various Normalizing Flow backbones, resulting in our Inverse-Flow models. We benchmark Inverse-Flow on standard datasets and show significantly improved sampling times with similar bits per dimension compared to previous models.
ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions
Sep 09, 2024
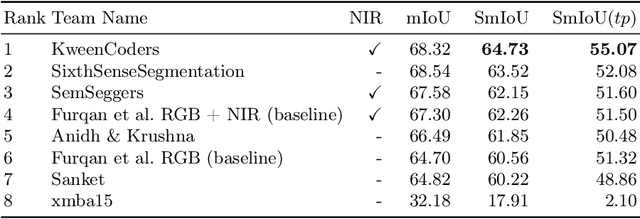
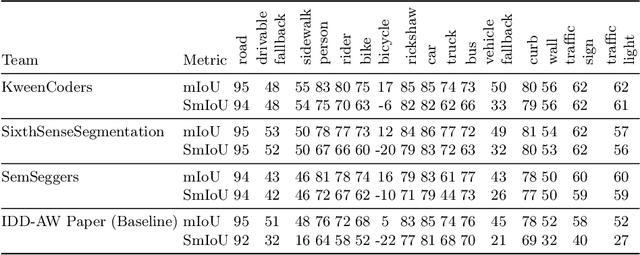
The ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions served as a rigorous platform to evaluate and benchmark state-of-the-art semantic segmentation models under challenging conditions for autonomous driving. Over several months, participants were provided with the IDD-AW dataset, consisting of 5000 high-quality RGB-NIR image pairs, each annotated at the pixel level and captured under adverse weather conditions such as rain, fog, low light, and snow. A key aspect of the competition was the use and improvement of the Safe mean Intersection over Union (Safe mIoU) metric, designed to penalize unsafe incorrect predictions that could be overlooked by traditional mIoU. This innovative metric emphasized the importance of safety in developing autonomous driving systems. The competition showed significant advancements in the field, with participants demonstrating models that excelled in semantic segmentation and prioritized safety and robustness in unstructured and adverse conditions. The results of the competition set new benchmarks in the domain, highlighting the critical role of safety in deploying autonomous vehicles in real-world scenarios. The contributions from this competition are expected to drive further innovation in autonomous driving technology, addressing the critical challenges of operating in diverse and unpredictable environments.
Remote sensing framework for geological mapping via stacked autoencoders and clustering
Apr 02, 2024



Supervised learning methods for geological mapping via remote sensing face limitations due to the scarcity of accurately labelled training data. In contrast, unsupervised learning methods, such as dimensionality reduction and clustering have the ability to uncover patterns and structures in remote sensing data without relying on predefined labels. Dimensionality reduction methods have the potential to play a crucial role in improving the accuracy of geological maps. Although conventional dimensionality reduction methods may struggle with nonlinear data, unsupervised deep learning models such as autoencoders have the ability to model nonlinear relationship in data. Stacked autoencoders feature multiple interconnected layers to capture hierarchical data representations that can be useful for remote sensing data. In this study, we present an unsupervised machine learning framework for processing remote sensing data by utilizing stacked autoencoders for dimensionality reduction and k-means clustering for mapping geological units. We use the Landsat-8, ASTER, and Sentinel-2 datasets of the Mutawintji region in Western New South Wales, Australia to evaluate the framework for geological mapping. We also provide a comparison of stacked autoencoders with principal component analysis and canonical autoencoders. Our results reveal that the framework produces accurate and interpretable geological maps, efficiently discriminating rock units. We find that the stacked autoencoders provide better accuracy when compared to the counterparts. We also find that the generated maps align with prior geological knowledge of the study area while providing novel insights into geological structures.
Adaptation of the super resolution SOTA for Art Restoration in camera capture images
Sep 28, 2023



Preserving cultural heritage is of paramount importance. In the domain of art restoration, developing a computer vision model capable of effectively restoring deteriorated images of art pieces was difficult, but now we have a good computer vision state-of-art. Traditional restoration methods are often time-consuming and require extensive expertise. The aim of this work is to design an automated solution based on computer vision models that can enhance and reconstruct degraded artworks, improving their visual quality while preserving their original characteristics and artifacts. The model should handle a diverse range of deterioration types, including but not limited to noise, blur, scratches, fading, and other common forms of degradation. We adapt the current state-of-art for the image super-resolution based on the Diffusion Model (DM) and fine-tune it for Image art restoration. Our results show that instead of fine-tunning multiple different models for different kinds of degradation, fine-tuning one super-resolution. We train it on multiple datasets to make it robust. code link: https://github.com/Naagar/art_restoration_DM
FInC Flow: Fast and Invertible $k \times k$ Convolutions for Normalizing Flows
Jan 23, 2023Invertible convolutions have been an essential element for building expressive normalizing flow-based generative models since their introduction in Glow. Several attempts have been made to design invertible $k \times k$ convolutions that are efficient in training and sampling passes. Though these attempts have improved the expressivity and sampling efficiency, they severely lagged behind Glow which used only $1 \times 1$ convolutions in terms of sampling time. Also, many of the approaches mask a large number of parameters of the underlying convolution, resulting in lower expressivity on a fixed run-time budget. We propose a $k \times k$ convolutional layer and Deep Normalizing Flow architecture which i.) has a fast parallel inversion algorithm with running time O$(n k^2)$ ($n$ is height and width of the input image and k is kernel size), ii.) masks the minimal amount of learnable parameters in a layer. iii.) gives better forward pass and sampling times comparable to other $k \times k$ convolution-based models on real-world benchmarks. We provide an implementation of the proposed parallel algorithm for sampling using our invertible convolutions on GPUs. Benchmarks on CIFAR-10, ImageNet, and CelebA datasets show comparable performance to previous works regarding bits per dimension while significantly improving the sampling time.
* accepted: VISAPP'23
Automated Seed Quality Testing System using GAN & Active Learning
Oct 02, 2021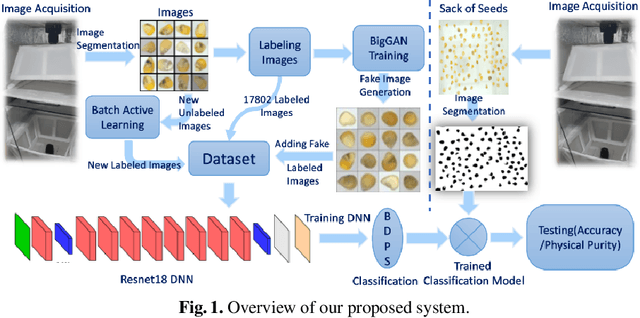
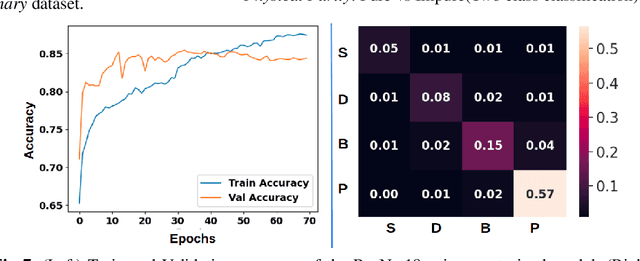


Quality assessment of agricultural produce is a crucial step in minimizing food stock wastage. However, this is currently done manually and often requires expert supervision, especially in smaller seeds like corn. We propose a novel computer vision-based system for automating this process. We build a novel seed image acquisition setup, which captures both the top and bottom views. Dataset collection for this problem has challenges of data annotation costs/time and class imbalance. We address these challenges by i.) using a Conditional Generative Adversarial Network (CGAN) to generate real-looking images for the classes with lesser images and ii.) annotate a large dataset with minimal expert human intervention by using a Batch Active Learning (BAL) based annotation tool. We benchmark different image classification models on the dataset obtained. We are able to get accuracies of up to 91.6% for testing the physical purity of seed samples.
CInC Flow: Characterizable Invertible 3x3 Convolution
Jul 03, 2021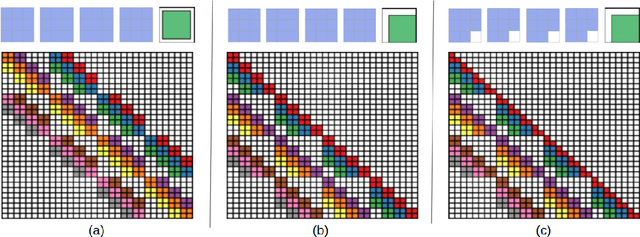

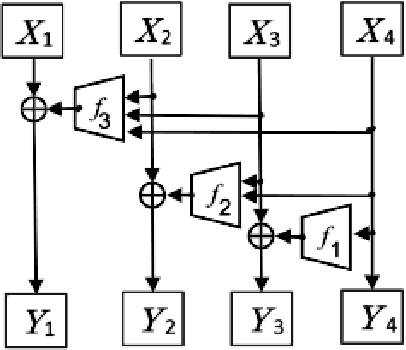
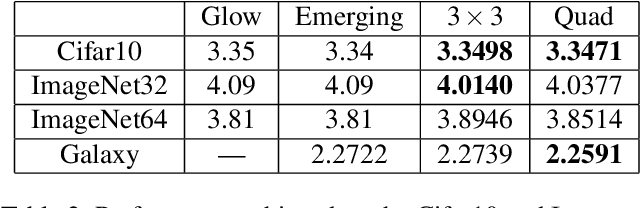
Normalizing flows are an essential alternative to GANs for generative modelling, which can be optimized directly on the maximum likelihood of the dataset. They also allow computation of the exact latent vector corresponding to an image since they are composed of invertible transformations. However, the requirement of invertibility of the transformation prevents standard and expressive neural network models such as CNNs from being directly used. Emergent convolutions were proposed to construct an invertible 3$\times$3 CNN layer using a pair of masked CNN layers, making them inefficient. We study conditions such that 3$\times$3 CNNs are invertible, allowing them to construct expressive normalizing flows. We derive necessary and sufficient conditions on a padded CNN for it to be invertible. Our conditions for invertibility are simple, can easily be maintained during the training process. Since we require only a single CNN layer for every effective invertible CNN layer, our approach is more efficient than emerging convolutions. We also proposed a coupling method, Quad-coupling. We benchmark our approach and show similar performance results to emergent convolutions while improving the model's efficiency.