 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality Shapes Gender Bias in Persona-Conditioned LLM Narratives Across English and Hindi: An Empirical Investigation
Apr 26, 2026Large Language Models (LLMs) are increasingly deployed in persona-driven applications such as education, customer service, and social platforms, where models are prompted to adopt specific personas when interacting with users. While persona conditioning can improve user experience and engagement, it also raises concerns about how personality cues may interact with gender biases and stereotypes. In this work, we present a controlled study of persona-conditioned story generation in English and Hindi, where each story portrays a working professional in India producing context-specific artifacts (e.g., lesson plans, reports, letters) under systematically varied persona gender, occupational role, and personality traits from the HEXACO and Dark Triad frameworks. Across 23,400 generated stories from six state-of-the-art LLMs, we find that personality traits are significantly associated with both the magnitude and direction of gender bias. In particular, Dark Triad personality traits are consistently associated with higher gender-stereotypical representations compared to socially desirable HEXACO traits, though these associations vary across models and languages. Our findings demonstrate that gender bias in LLMs is not static but context-dependent. This suggests that persona-conditioned systems used in real-world applications may introduce uneven representational harms, reinforcing gender stereotypes in generated educational, professional, or social content.
SEPSIS: I Can Catch Your Lies -- A New Paradigm for Deception Detection
Dec 01, 2023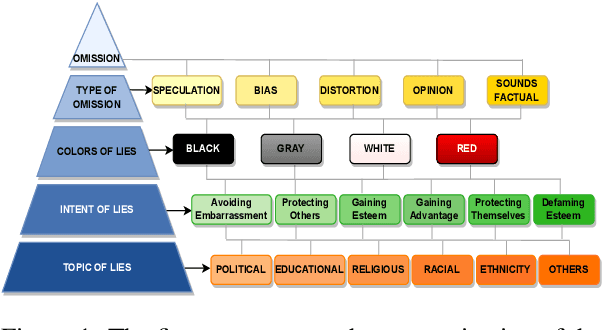


Deception is the intentional practice of twisting information. It is a nuanced societal practice deeply intertwined with human societal evolution, characterized by a multitude of facets. This research explores the problem of deception through the lens of psychology, employing a framework that categorizes deception into three forms: lies of omission, lies of commission, and lies of influence. The primary focus of this study is specifically on investigating only lies of omission. We propose a novel framework for deception detection leveraging NLP techniques. We curated an annotated dataset of 876,784 samples by amalgamating a popular large-scale fake news dataset and scraped news headlines from the Twitter handle of Times of India, a well-known Indian news media house. Each sample has been labeled with four layers, namely: (i) the type of omission (speculation, bias, distortion, sounds factual, and opinion), (ii) colors of lies(black, white, etc), and (iii) the intention of such lies (to influence, etc) (iv) topic of lies (political, educational, religious, etc). We present a novel multi-task learning pipeline that leverages the dataless merging of fine-tuned language models to address the deception detection task mentioned earlier. Our proposed model achieved an F1 score of 0.87, demonstrating strong performance across all layers including the type, color, intent, and topic aspects of deceptive content. Finally, our research explores the relationship between lies of omission and propaganda techniques. To accomplish this, we conducted an in-depth analysis, uncovering compelling findings. For instance, our analysis revealed a significant correlation between loaded language and opinion, shedding light on their interconnectedness. To encourage further research in this field, we will be making the models and dataset available with the MIT License, making it favorable for open-source research.
Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think -- Introducing AI Detectability Index
Oct 24, 2023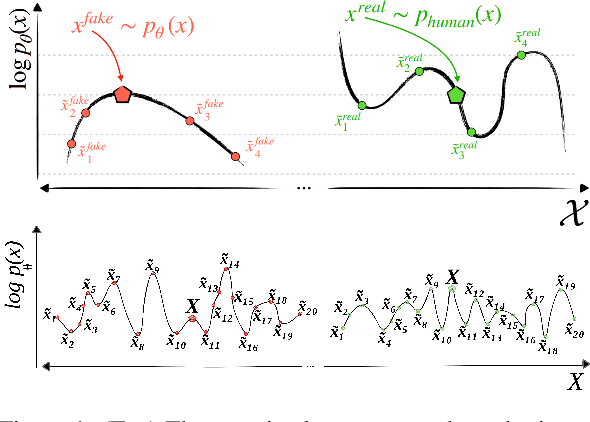



With the rise of prolific ChatGPT, the risk and consequences of AI-generated text has increased alarmingly. To address the inevitable question of ownership attribution for AI-generated artifacts, the US Copyright Office released a statement stating that 'If a work's traditional elements of authorship were produced by a machine, the work lacks human authorship and the Office will not register it'. Furthermore, both the US and the EU governments have recently drafted their initial proposals regarding the regulatory framework for AI. Given this cynosural spotlight on generative AI, AI-generated text detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by emergence of techniques to bypass detection. This paper introduces the Counter Turing Test (CT^2), a benchmark consisting of techniques aiming to offer a comprehensive evaluation of the robustness of existing AGTD techniques. Our empirical findings unequivocally highlight the fragility of the proposed AGTD methods under scrutiny. Amidst the extensive deliberations on policy-making for regulating AI development, it is of utmost importance to assess the detectability of content generated by LLMs. Thus, to establish a quantifiable spectrum facilitating the evaluation and ranking of LLMs according to their detectability levels, we propose the AI Detectability Index (ADI). We conduct a thorough examination of 15 contemporary LLMs, empirically demonstrating that larger LLMs tend to have a higher ADI, indicating they are less detectable compared to smaller LLMs. We firmly believe that ADI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making.
FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering
May 07, 2023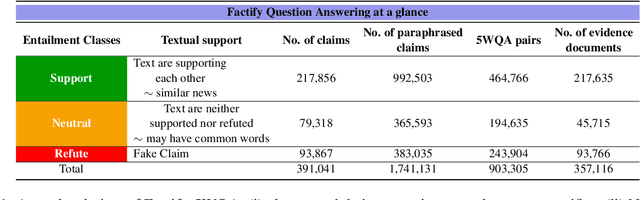
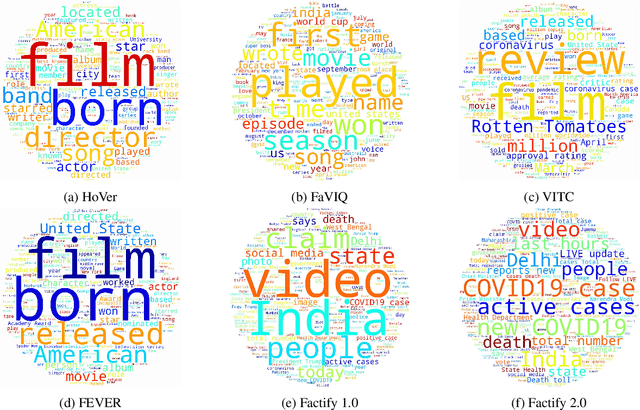

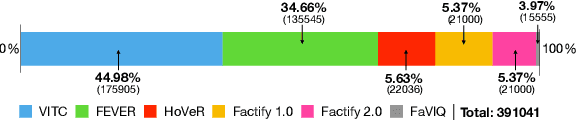
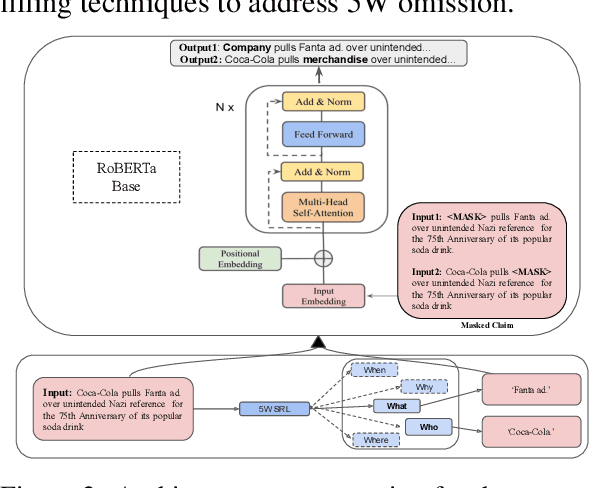
Automatic fact verification has received significant attention recently. Contemporary automatic fact-checking systems focus on estimating truthfulness using numerical scores which are not human-interpretable. A human fact-checker generally follows several logical steps to verify a verisimilitude claim and conclude whether it is truthful or a mere masquerade. Popular fact-checking websites follow a common structure for fact categorization such as half true, half false, false, pants on fire, etc. Therefore, it is necessary to have an aspect-based (which part is true and which part is false) explainable system that can assist human fact-checkers in asking relevant questions related to a fact, which can then be validated separately to reach a final verdict. In this paper, we propose a 5W framework (who, what, when, where, and why) for question-answer-based fact explainability. To that end, we have gathered a semi-automatically generated dataset called FACTIFY-5WQA, which consists of 395, 019 facts along with relevant 5W QAs underscoring our major contribution to this paper. A semantic role labeling system has been utilized to locate 5Ws, which generates QA pairs for claims using a masked language model. Finally, we report a baseline QA system to automatically locate those answers from evidence documents, which can be served as the baseline for future research in this field. Lastly, we propose a robust fact verification system that takes paraphrased claims and automatically validates them. The dataset and the baseline model are available at https://github.com/ankuranii/acl-5W-QA.