 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: A Reasoning-Guided Attribution Framework for Explainable Visual Data Analysis
Aug 23, 2025Data visualizations like charts are fundamental tools for quantitative analysis and decision-making across fields, requiring accurate interpretation and mathematical reasoning. The emergence of Multimodal Large Language Models (MLLMs) offers promising capabilities for automated visual data analysis, such as processing charts, answering questions, and generating summaries. However, they provide no visibility into which parts of the visual data informed their conclusions; this black-box nature poses significant challenges to real-world trust and adoption. In this paper, we take the first major step towards evaluating and enhancing the capabilities of MLLMs to attribute their reasoning process by highlighting the specific regions in charts and graphs that justify model answers. To this end, we contribute RADAR, a semi-automatic approach to obtain a benchmark dataset comprising 17,819 diverse samples with charts, questions, reasoning steps, and attribution annotations. We also introduce a method that provides attribution for chart-based mathematical reasoning. Experimental results demonstrate that our reasoning-guided approach improves attribution accuracy by 15% compared to baseline methods, and enhanced attribution capabilities translate to stronger answer generation, achieving an average BERTScore of $\sim$ 0.90, indicating high alignment with ground truth responses. This advancement represents a significant step toward more interpretable and trustworthy chart analysis systems, enabling users to verify and understand model decisions through reasoning and attribution.
Overview of Factify5WQA: Fact Verification through 5W Question-Answering
Oct 05, 2024



Researchers have found that fake news spreads much times faster than real news. This is a major problem, especially in today's world where social media is the key source of news for many among the younger population. Fact verification, thus, becomes an important task and many media sites contribute to the cause. Manual fact verification is a tedious task, given the volume of fake news online. The Factify5WQA shared task aims to increase research towards automated fake news detection by providing a dataset with an aspect-based question answering based fact verification method. Each claim and its supporting document is associated with 5W questions that help compare the two information sources. The objective performance measure in the task is done by comparing answers using BLEU score to measure the accuracy of the answers, followed by an accuracy measure of the classification. The task had submissions using custom training setup and pre-trained language-models among others. The best performing team posted an accuracy of 69.56%, which is a near 35% improvement over the baseline.
Counter Turing Test ($CT^2$): Investigating AI-Generated Text Detection for Hindi -- Ranking LLMs based on Hindi AI Detectability Index ($ADI_{hi}$)
Jul 22, 2024



The widespread adoption of large language models (LLMs) and awareness around multilingual LLMs have raised concerns regarding the potential risks and repercussions linked to the misapplication of AI-generated text, necessitating increased vigilance. While these models are primarily trained for English, their extensive training on vast datasets covering almost the entire web, equips them with capabilities to perform well in numerous other languages. AI-Generated Text Detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by the emergence of techniques to bypass detection. In this paper, we report our investigation on AGTD for an indic language Hindi. Our major contributions are in four folds: i) examined 26 LLMs to evaluate their proficiency in generating Hindi text, ii) introducing the AI-generated news article in Hindi ($AG_{hi}$) dataset, iii) evaluated the effectiveness of five recently proposed AGTD techniques: ConDA, J-Guard, RADAR, RAIDAR and Intrinsic Dimension Estimation for detecting AI-generated Hindi text, iv) proposed Hindi AI Detectability Index ($ADI_{hi}$) which shows a spectrum to understand the evolving landscape of eloquence of AI-generated text in Hindi. We will make the codes and datasets available to encourage further research.
Visual Hallucination: Definition, Quantification, and Prescriptive Remediations
Mar 31, 2024The troubling rise of hallucination presents perhaps the most significant impediment to the advancement of responsible AI. In recent times, considerable research has focused on detecting and mitigating hallucination in Large Language Models (LLMs). However, it's worth noting that hallucination is also quite prevalent in Vision-Language models (VLMs). In this paper, we offer a fine-grained discourse on profiling VLM hallucination based on two tasks: i) image captioning, and ii) Visual Question Answering (VQA). We delineate eight fine-grained orientations of visual hallucination: i) Contextual Guessing, ii) Identity Incongruity, iii) Geographical Erratum, iv) Visual Illusion, v) Gender Anomaly, vi) VLM as Classifier, vii) Wrong Reading, and viii) Numeric Discrepancy. We curate Visual HallucInation eLiciTation (VHILT), a publicly available dataset comprising 2,000 samples generated using eight VLMs across two tasks of captioning and VQA along with human annotations for the categories as mentioned earlier.
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
Jan 08, 2024As Large Language Models (LLMs) continue to advance in their ability to write human-like text, a key challenge remains around their tendency to hallucinate generating content that appears factual but is ungrounded. This issue of hallucination is arguably the biggest hindrance to safely deploying these powerful LLMs into real-world production systems that impact people's lives. The journey toward widespread adoption of LLMs in practical settings heavily relies on addressing and mitigating hallucinations. Unlike traditional AI systems focused on limited tasks, LLMs have been exposed to vast amounts of online text data during training. While this allows them to display impressive language fluency, it also means they are capable of extrapolating information from the biases in training data, misinterpreting ambiguous prompts, or modifying the information to align superficially with the input. This becomes hugely alarming when we rely on language generation capabilities for sensitive applications, such as summarizing medical records, financial analysis reports, etc. This paper presents a comprehensive survey of over 32 techniques developed to mitigate hallucination in LLMs. Notable among these are Retrieval Augmented Generation (Lewis et al, 2021), Knowledge Retrieval (Varshney et al,2023), CoNLI (Lei et al, 2023), and CoVe (Dhuliawala et al, 2023). Furthermore, we introduce a detailed taxonomy categorizing these methods based on various parameters, such as dataset utilization, common tasks, feedback mechanisms, and retriever types. This classification helps distinguish the diverse approaches specifically designed to tackle hallucination issues in LLMs. Additionally, we analyze the challenges and limitations inherent in these techniques, providing a solid foundation for future research in addressing hallucinations and related phenomena within the realm of LLMs.
SEPSIS: I Can Catch Your Lies -- A New Paradigm for Deception Detection
Dec 01, 2023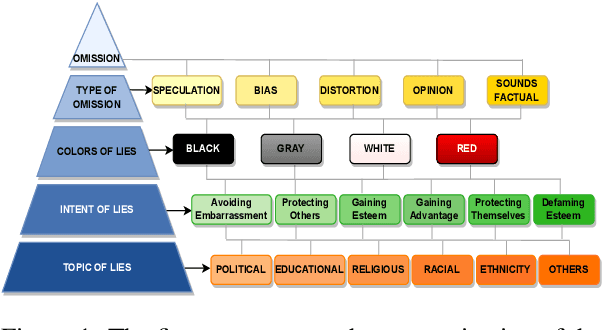


Deception is the intentional practice of twisting information. It is a nuanced societal practice deeply intertwined with human societal evolution, characterized by a multitude of facets. This research explores the problem of deception through the lens of psychology, employing a framework that categorizes deception into three forms: lies of omission, lies of commission, and lies of influence. The primary focus of this study is specifically on investigating only lies of omission. We propose a novel framework for deception detection leveraging NLP techniques. We curated an annotated dataset of 876,784 samples by amalgamating a popular large-scale fake news dataset and scraped news headlines from the Twitter handle of Times of India, a well-known Indian news media house. Each sample has been labeled with four layers, namely: (i) the type of omission (speculation, bias, distortion, sounds factual, and opinion), (ii) colors of lies(black, white, etc), and (iii) the intention of such lies (to influence, etc) (iv) topic of lies (political, educational, religious, etc). We present a novel multi-task learning pipeline that leverages the dataless merging of fine-tuned language models to address the deception detection task mentioned earlier. Our proposed model achieved an F1 score of 0.87, demonstrating strong performance across all layers including the type, color, intent, and topic aspects of deceptive content. Finally, our research explores the relationship between lies of omission and propaganda techniques. To accomplish this, we conducted an in-depth analysis, uncovering compelling findings. For instance, our analysis revealed a significant correlation between loaded language and opinion, shedding light on their interconnectedness. To encourage further research in this field, we will be making the models and dataset available with the MIT License, making it favorable for open-source research.
Overview of Memotion 3: Sentiment and Emotion Analysis of Codemixed Hinglish Memes
Sep 12, 2023
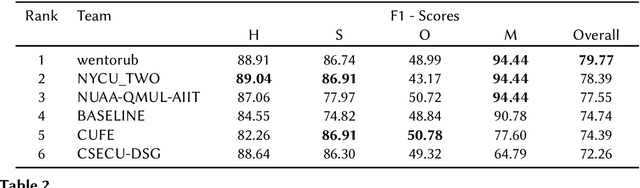

Analyzing memes on the internet has emerged as a crucial endeavor due to the impact this multi-modal form of content wields in shaping online discourse. Memes have become a powerful tool for expressing emotions and sentiments, possibly even spreading hate and misinformation, through humor and sarcasm. In this paper, we present the overview of the Memotion 3 shared task, as part of the DeFactify 2 workshop at AAAI-23. The task released an annotated dataset of Hindi-English code-mixed memes based on their Sentiment (Task A), Emotion (Task B), and Emotion intensity (Task C). Each of these is defined as an individual task and the participants are ranked separately for each task. Over 50 teams registered for the shared task and 5 made final submissions to the test set of the Memotion 3 dataset. CLIP, BERT modifications, ViT etc. were the most popular models among the participants along with approaches such as Student-Teacher model, Fusion, and Ensembling. The best final F1 score for Task A is 34.41, Task B is 79.77 and Task C is 59.82.
Findings of Factify 2: Multimodal Fake News Detection
Jul 19, 2023With social media usage growing exponentially in the past few years, fake news has also become extremely prevalent. The detrimental impact of fake news emphasizes the need for research focused on automating the detection of false information and verifying its accuracy. In this work, we present the outcome of the Factify 2 shared task, which provides a multi-modal fact verification and satire news dataset, as part of the DeFactify 2 workshop at AAAI'23. The data calls for a comparison based approach to the task by pairing social media claims with supporting documents, with both text and image, divided into 5 classes based on multi-modal relations. In the second iteration of this task we had over 60 participants and 9 final test-set submissions. The best performances came from the use of DeBERTa for text and Swinv2 and CLIP for image. The highest F1 score averaged for all five classes was 81.82%.
FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering
May 07, 2023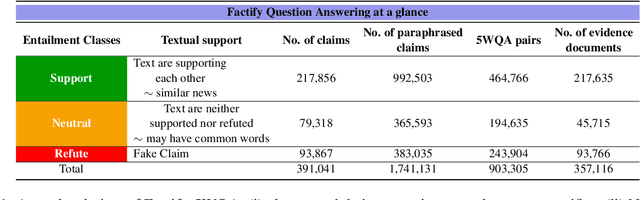

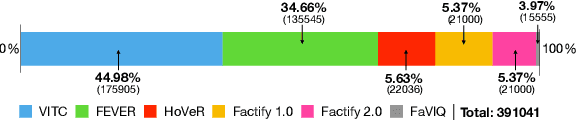
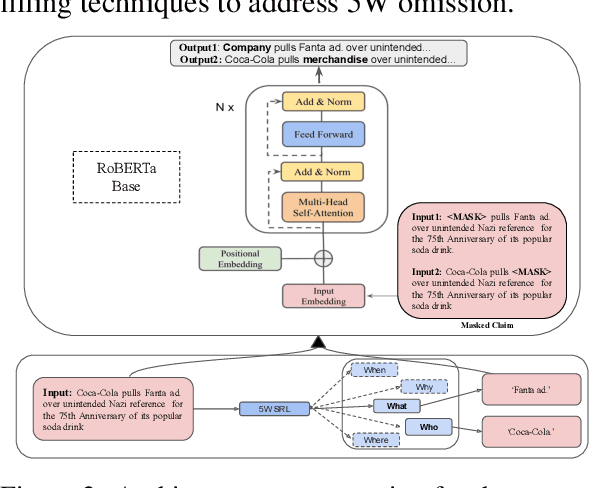
Automatic fact verification has received significant attention recently. Contemporary automatic fact-checking systems focus on estimating truthfulness using numerical scores which are not human-interpretable. A human fact-checker generally follows several logical steps to verify a verisimilitude claim and conclude whether it is truthful or a mere masquerade. Popular fact-checking websites follow a common structure for fact categorization such as half true, half false, false, pants on fire, etc. Therefore, it is necessary to have an aspect-based (which part is true and which part is false) explainable system that can assist human fact-checkers in asking relevant questions related to a fact, which can then be validated separately to reach a final verdict. In this paper, we propose a 5W framework (who, what, when, where, and why) for question-answer-based fact explainability. To that end, we have gathered a semi-automatically generated dataset called FACTIFY-5WQA, which consists of 395, 019 facts along with relevant 5W QAs underscoring our major contribution to this paper. A semantic role labeling system has been utilized to locate 5Ws, which generates QA pairs for claims using a masked language model. Finally, we report a baseline QA system to automatically locate those answers from evidence documents, which can be served as the baseline for future research in this field. Lastly, we propose a robust fact verification system that takes paraphrased claims and automatically validates them. The dataset and the baseline model are available at https://github.com/ankuranii/acl-5W-QA.
Factify 2: A Multimodal Fake News and Satire News Dataset
Apr 08, 2023The internet gives the world an open platform to express their views and share their stories. While this is very valuable, it makes fake news one of our society's most pressing problems. Manual fact checking process is time consuming, which makes it challenging to disprove misleading assertions before they cause significant harm. This is he driving interest in automatic fact or claim verification. Some of the existing datasets aim to support development of automating fact-checking techniques, however, most of them are text based. Multi-modal fact verification has received relatively scant attention. In this paper, we provide a multi-modal fact-checking dataset called FACTIFY 2, improving Factify 1 by using new data sources and adding satire articles. Factify 2 has 50,000 new data instances. Similar to FACTIFY 1.0, we have three broad categories - support, no-evidence, and refute, with sub-categories based on the entailment of visual and textual data. We also provide a BERT and Vison Transformer based baseline, which acheives 65% F1 score in the test set. The baseline codes and the dataset will be made available at https://github.com/surya1701/Factify-2.0.