 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRoPS: A Training-Free Hallucination Mitigation Framework for Vision-Language Models
Jan 02, 2026Despite the rapid success of Large Vision-Language Models (LVLMs), a persistent challenge is their tendency to generate hallucinated content, undermining reliability in real-world use. Existing training-free methods address hallucinations but face two limitations: (i) they rely on narrow assumptions about hallucination sources, and (ii) their effectiveness declines toward the end of generation, where hallucinations are most likely to occur. A common strategy is to build hallucinated models by completely or partially removing visual tokens and contrasting them with the original model. Yet, this alone proves insufficient, since visual information still propagates into generated text. Building on this insight, we propose a novel hallucinated model that captures hallucination effects by selectively removing key text tokens. We further introduce Generalized Contrastive Decoding, which integrates multiple hallucinated models to represent diverse hallucination sources. Together, these ideas form CRoPS, a training-free hallucination mitigation framework that improves CHAIR scores by 20% and achieves consistent gains across six benchmarks and three LVLM families, outperforming state-of-the-art training-free methods.
Visual Hallucination: Definition, Quantification, and Prescriptive Remediations
Mar 31, 2024The troubling rise of hallucination presents perhaps the most significant impediment to the advancement of responsible AI. In recent times, considerable research has focused on detecting and mitigating hallucination in Large Language Models (LLMs). However, it's worth noting that hallucination is also quite prevalent in Vision-Language models (VLMs). In this paper, we offer a fine-grained discourse on profiling VLM hallucination based on two tasks: i) image captioning, and ii) Visual Question Answering (VQA). We delineate eight fine-grained orientations of visual hallucination: i) Contextual Guessing, ii) Identity Incongruity, iii) Geographical Erratum, iv) Visual Illusion, v) Gender Anomaly, vi) VLM as Classifier, vii) Wrong Reading, and viii) Numeric Discrepancy. We curate Visual HallucInation eLiciTation (VHILT), a publicly available dataset comprising 2,000 samples generated using eight VLMs across two tasks of captioning and VQA along with human annotations for the categories as mentioned earlier.
MixBin: Towards Budgeted Binarization
Nov 12, 2022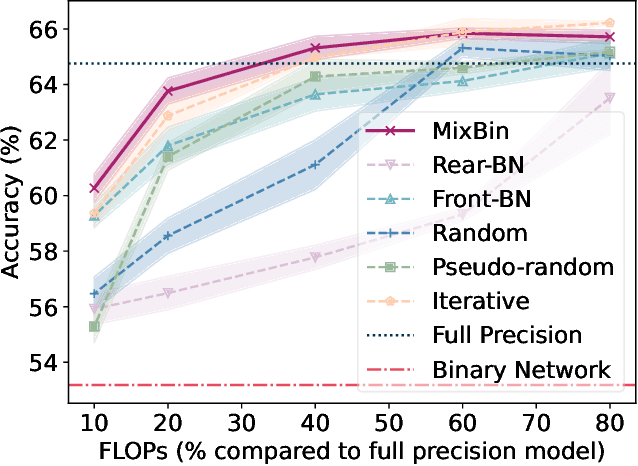
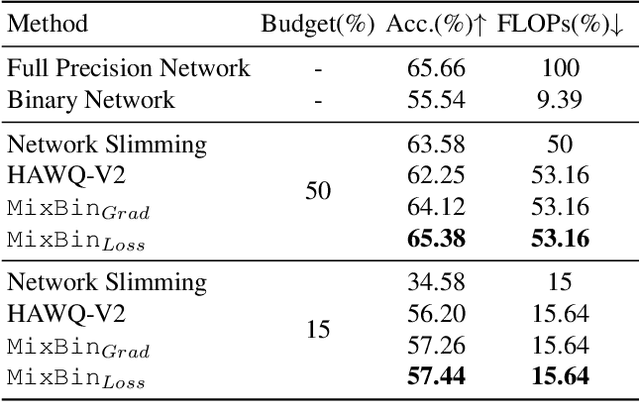
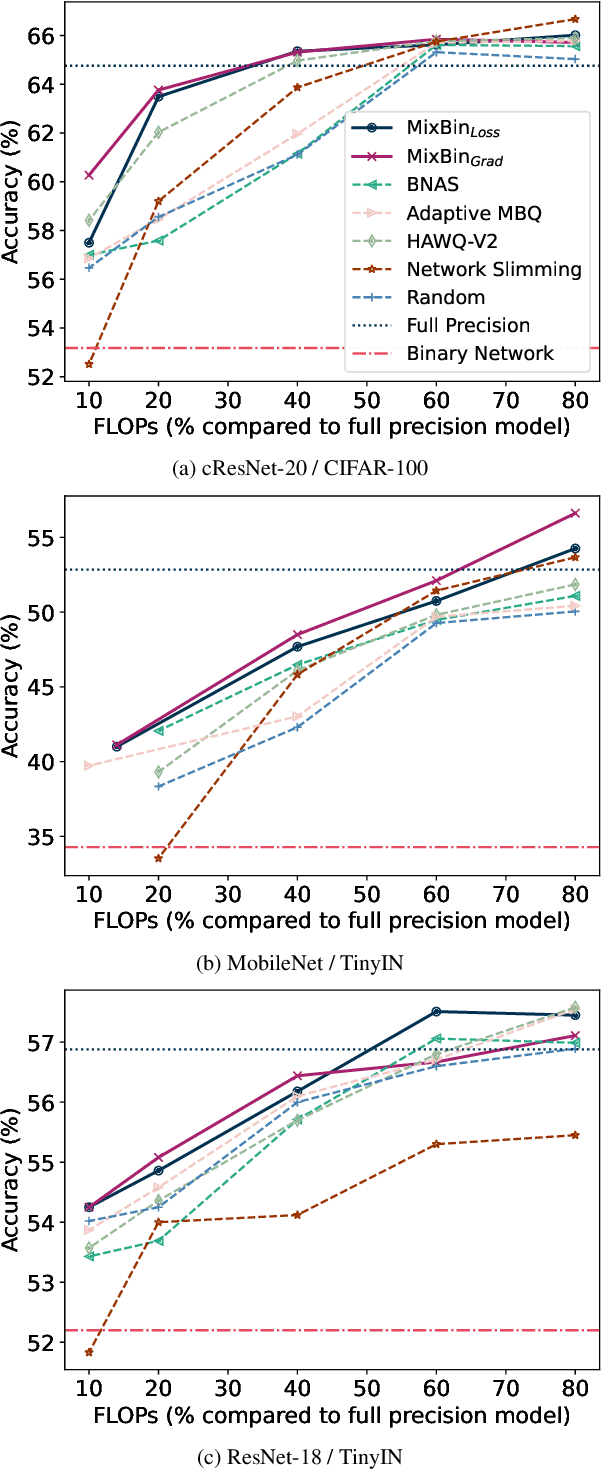
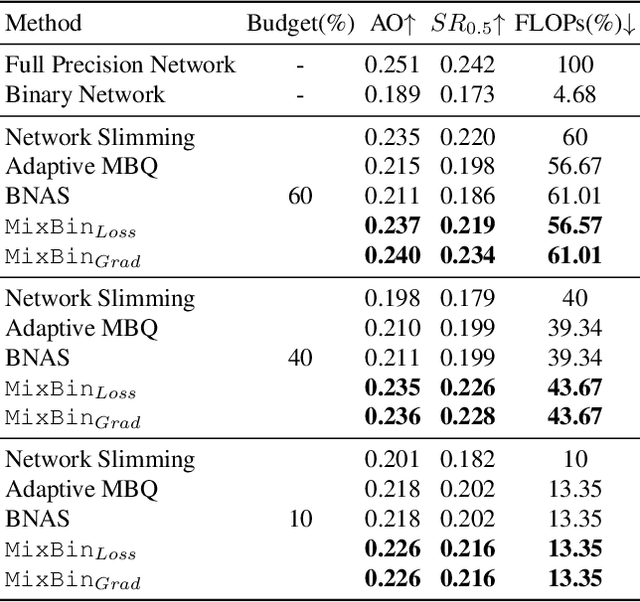
Binarization has proven to be amongst the most effective ways of neural network compression, reducing the FLOPs of the original model by a large extent. However, such levels of compression are often accompanied by a significant drop in the performance. There exist some approaches that reduce this performance drop by facilitating partial binarization of the network, however, a systematic approach to mix binary and full-precision parameters in a single network is still missing. In this paper, we propose a paradigm to perform partial binarization of neural networks in a controlled sense, thereby constructing budgeted binary neural network (B2NN). We present MixBin, an iterative search-based strategy that constructs B2NN through optimized mixing of the binary and full-precision components. MixBin allows to explicitly choose the approximate fraction of the network to be kept as binary, thereby presenting the flexibility to adapt the inference cost at a prescribed budget. We demonstrate through experiments that B2NNs obtained from our MixBin strategy are significantly better than those obtained from random selection of the network layers. To perform partial binarization in an effective manner, it is important that both the full-precision as well as the binary components of the B2NN are appropriately optimized. We also demonstrate that the choice of the activation function can have a significant effect on this process, and to circumvent this issue, we present BinReLU, that can be used as an effective activation function for the full-precision as well as the binary components of any B2NN. Experimental investigations reveal that BinReLU outperforms the other activation functions in all possible scenarios of B2NN: zero-, partial- as well as full binarization. Finally, we demonstrate the efficacy of MixBin on the tasks of classification and object tracking using benchmark datasets.