 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPA: Contribution-Aware Pruning and FFN Approximation for Efficient Large Vision-Language Models
Jan 30, 2026Efficient inference in Large Vision-Language Models is constrained by the high cost of processing thousands of visual tokens, yet it remains unclear which tokens and computations can be safely removed. While attention scores are commonly used to estimate visual token importance, they are an imperfect proxy for actual contribution. We show that Attention Contribution, which weights attention probabilities by value vector magnitude, provides a more accurate criterion for visual token selection. Our empirical analysis reveals that visual attention sinks are functionally heterogeneous, comprising Probability Dumps with low contribution that can be safely pruned, and Structural Anchors with high contribution essential for maintaining model performance. Further, we identify substantial redundancy in Feed-Forward Networks (FFNs) associated with visual tokens, particularly in intermediate layers where image tokens exhibit linear behavior. Based on our findings, we introduce CAPA (Contribution-Aware Pruning and FFN Approximation), a dual-strategy framework that prunes visual tokens using attention contribution at critical functional transitions and reduces FFN computation through efficient linear approximations. Experiments on various benchmarks across baselines show that CAPA achieves competent efficiency--performance trade-offs with improved robustness.
CRoPS: A Training-Free Hallucination Mitigation Framework for Vision-Language Models
Jan 02, 2026Despite the rapid success of Large Vision-Language Models (LVLMs), a persistent challenge is their tendency to generate hallucinated content, undermining reliability in real-world use. Existing training-free methods address hallucinations but face two limitations: (i) they rely on narrow assumptions about hallucination sources, and (ii) their effectiveness declines toward the end of generation, where hallucinations are most likely to occur. A common strategy is to build hallucinated models by completely or partially removing visual tokens and contrasting them with the original model. Yet, this alone proves insufficient, since visual information still propagates into generated text. Building on this insight, we propose a novel hallucinated model that captures hallucination effects by selectively removing key text tokens. We further introduce Generalized Contrastive Decoding, which integrates multiple hallucinated models to represent diverse hallucination sources. Together, these ideas form CRoPS, a training-free hallucination mitigation framework that improves CHAIR scores by 20% and achieves consistent gains across six benchmarks and three LVLM families, outperforming state-of-the-art training-free methods.
Langevin Monte-Carlo Provably Learns Depth Two Neural Nets at Any Size and Data
Mar 13, 2025In this work, we will establish that the Langevin Monte-Carlo algorithm can learn depth-2 neural nets of any size and for any data and we give non-asymptotic convergence rates for it. We achieve this via showing that under Total Variation distance and q-Renyi divergence, the iterates of Langevin Monte Carlo converge to the Gibbs distribution of Frobenius norm regularized losses for any of these nets, when using smooth activations and in both classification and regression settings. Most critically, the amount of regularization needed for our results is independent of the size of the net. The key observation of ours is that two layer neural loss functions can always be regularized by a constant amount such that they satisfy the Villani conditions, and thus their Gibbs measures satisfy a Poincare inequality.
Global Convergence of SGD For Logistic Loss on Two Layer Neural Nets
Sep 17, 2023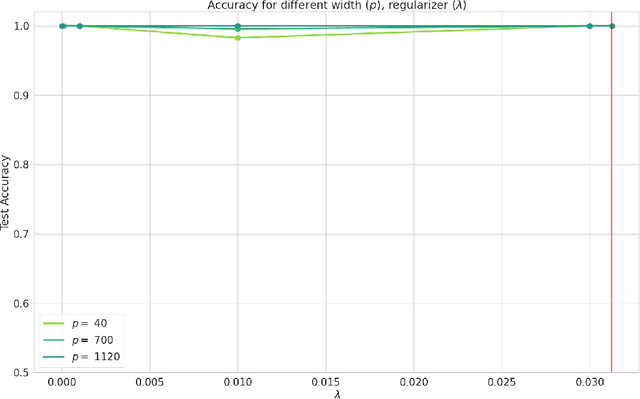
In this note, we demonstrate a first-of-its-kind provable convergence of SGD to the global minima of appropriately regularized logistic empirical risk of depth $2$ nets -- for arbitrary data and with any number of gates with adequately smooth and bounded activations like sigmoid and tanh. We also prove an exponentially fast convergence rate for continuous time SGD that also applies to smooth unbounded activations like SoftPlus. Our key idea is to show the existence of Frobenius norm regularized logistic loss functions on constant-sized neural nets which are "Villani functions" and thus be able to build on recent progress with analyzing SGD on such objectives.