 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers
Jun 16, 2025Training Transformers on algorithmic tasks frequently demonstrates an intriguing abrupt learning phenomenon: an extended performance plateau followed by a sudden, sharp improvement. This work investigates the underlying mechanisms for such dynamics, primarily in shallow Transformers. We reveal that during the plateau, the model often develops an interpretable partial solution while simultaneously exhibiting a strong repetition bias in their outputs. This output degeneracy is accompanied by internal representation collapse, where hidden states across different tokens become nearly parallel. We further identify the slow learning of optimal attention maps as a key bottleneck. Hidden progress in attention configuration during the plateau precedes the eventual rapid convergence, and directly intervening on attention significantly alters plateau duration and the severity of repetition bias and representational collapse. We validate that these identified phenomena-repetition bias and representation collapse-are not artifacts of toy setups but also manifest in the early pre-training stage of large language models like Pythia and OLMo.
Abrupt Learning in Transformers: A Case Study on Matrix Completion
Oct 29, 2024



Recent analysis on the training dynamics of Transformers has unveiled an interesting characteristic: the training loss plateaus for a significant number of training steps, and then suddenly (and sharply) drops to near--optimal values. To understand this phenomenon in depth, we formulate the low-rank matrix completion problem as a masked language modeling (MLM) task, and show that it is possible to train a BERT model to solve this task to low error. Furthermore, the loss curve shows a plateau early in training followed by a sudden drop to near-optimal values, despite no changes in the training procedure or hyper-parameters. To gain interpretability insights into this sudden drop, we examine the model's predictions, attention heads, and hidden states before and after this transition. Concretely, we observe that (a) the model transitions from simply copying the masked input to accurately predicting the masked entries; (b) the attention heads transition to interpretable patterns relevant to the task; and (c) the embeddings and hidden states encode information relevant to the problem. We also analyze the training dynamics of individual model components to understand the sudden drop in loss.
Global Convergence of SGD For Logistic Loss on Two Layer Neural Nets
Sep 17, 2023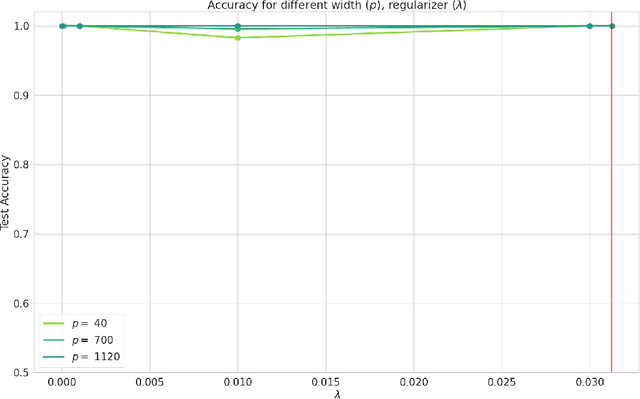
In this note, we demonstrate a first-of-its-kind provable convergence of SGD to the global minima of appropriately regularized logistic empirical risk of depth $2$ nets -- for arbitrary data and with any number of gates with adequately smooth and bounded activations like sigmoid and tanh. We also prove an exponentially fast convergence rate for continuous time SGD that also applies to smooth unbounded activations like SoftPlus. Our key idea is to show the existence of Frobenius norm regularized logistic loss functions on constant-sized neural nets which are "Villani functions" and thus be able to build on recent progress with analyzing SGD on such objectives.
Global Convergence of SGD On Two Layer Neural Nets
Oct 20, 2022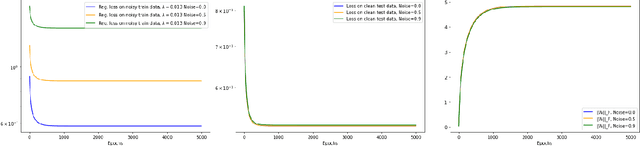
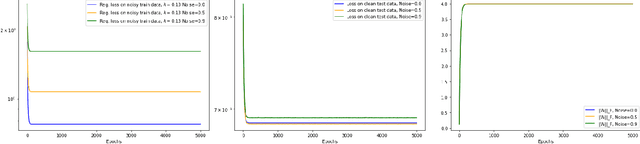


In this note we demonstrate provable convergence of SGD to the global minima of appropriately regularized $\ell_2-$empirical risk of depth $2$ nets -- for arbitrary data and with any number of gates, if they are using adequately smooth and bounded activations like sigmoid and tanh. We build on the results in [1] and leverage a constant amount of Frobenius norm regularization on the weights, along with sampling of the initial weights from an appropriate distribution. We also give a continuous time SGD convergence result that also applies to smooth unbounded activations like SoftPlus. Our key idea is to show the existence loss functions on constant sized neural nets which are "Villani Functions". [1] Bin Shi, Weijie J. Su, and Michael I. Jordan. On learning rates and schr\"odinger operators, 2020. arXiv:2004.06977
Capacity Bounds for the DeepONet Method of Solving Differential Equations
May 23, 2022



In recent times machine learning methods have made significant advances in becoming a useful tool for analyzing physical systems. A particularly active area in this theme has been "physics informed machine learning" [1] which focuses on using neural nets for numerically solving differential equations. Among all the proposals for solving differential equations using deep-learning, in this paper we aim to advance the theory of generalization error for DeepONets - which is unique among all the available ideas because of its particularly intriguing structure of having an inner-product of two neural nets. Our key contribution is to give a bound on the Rademacher complexity for a large class of DeepONets. Our bound does not explicitly scale with the number of parameters of the nets involved and is thus a step towards explaining the efficacy of overparameterized DeepONets. Additionally, a capacity bound such as ours suggests a novel regularizer on the neural net weights that can help in training DeepONets - irrespective of the differential equation being solved. [1] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang. Physics-informed machine learning. Nature Reviews Physics, 2021.