 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRoPS: A Training-Free Hallucination Mitigation Framework for Vision-Language Models
Jan 02, 2026Despite the rapid success of Large Vision-Language Models (LVLMs), a persistent challenge is their tendency to generate hallucinated content, undermining reliability in real-world use. Existing training-free methods address hallucinations but face two limitations: (i) they rely on narrow assumptions about hallucination sources, and (ii) their effectiveness declines toward the end of generation, where hallucinations are most likely to occur. A common strategy is to build hallucinated models by completely or partially removing visual tokens and contrasting them with the original model. Yet, this alone proves insufficient, since visual information still propagates into generated text. Building on this insight, we propose a novel hallucinated model that captures hallucination effects by selectively removing key text tokens. We further introduce Generalized Contrastive Decoding, which integrates multiple hallucinated models to represent diverse hallucination sources. Together, these ideas form CRoPS, a training-free hallucination mitigation framework that improves CHAIR scores by 20% and achieves consistent gains across six benchmarks and three LVLM families, outperforming state-of-the-art training-free methods.
C2F-TCN: A Framework for Semi and Fully Supervised Temporal Action Segmentation
Dec 20, 2022Temporal action segmentation tags action labels for every frame in an input untrimmed video containing multiple actions in a sequence. For the task of temporal action segmentation, we propose an encoder-decoder-style architecture named C2F-TCN featuring a "coarse-to-fine" ensemble of decoder outputs. The C2F-TCN framework is enhanced with a novel model agnostic temporal feature augmentation strategy formed by the computationally inexpensive strategy of the stochastic max-pooling of segments. It produces more accurate and well-calibrated supervised results on three benchmark action segmentation datasets. We show that the architecture is flexible for both supervised and representation learning. In line with this, we present a novel unsupervised way to learn frame-wise representation from C2F-TCN. Our unsupervised learning approach hinges on the clustering capabilities of the input features and the formation of multi-resolution features from the decoder's implicit structure. Further, we provide the first semi-supervised temporal action segmentation results by merging representation learning with conventional supervised learning. Our semi-supervised learning scheme, called ``Iterative-Contrastive-Classify (ICC)'', progressively improves in performance with more labeled data. The ICC semi-supervised learning in C2F-TCN, with 40% labeled videos, performs similar to fully supervised counterparts.
A Generalized & Robust Framework For Timestamp Supervision in Temporal Action Segmentation
Jul 20, 2022



In temporal action segmentation, Timestamp supervision requires only a handful of labelled frames per video sequence. For unlabelled frames, previous works rely on assigning hard labels, and performance rapidly collapses under subtle violations of the annotation assumptions. We propose a novel Expectation-Maximization (EM) based approach that leverages the label uncertainty of unlabelled frames and is robust enough to accommodate possible annotation errors. With accurate timestamp annotations, our proposed method produces SOTA results and even exceeds the fully-supervised setup in several metrics and datasets. When applied to timestamp annotations with missing action segments, our method presents stable performance. To further test our formulation's robustness, we introduce the new challenging annotation setup of Skip-tag supervision. This setup relaxes constraints and requires annotations of any fixed number of random frames in a video, making it more flexible than Timestamp supervision while remaining competitive.
Iterative Contrast-Classify For Semi-supervised Temporal Action Segmentation
Dec 08, 2021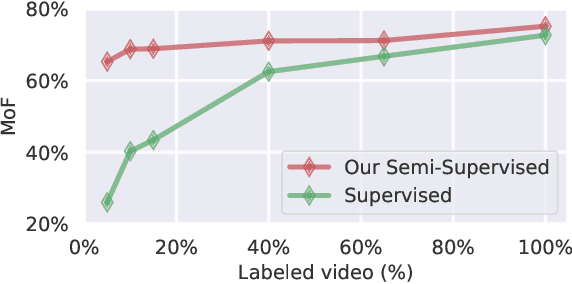



Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.
Coarse to Fine Multi-Resolution Temporal Convolutional Network
May 23, 2021
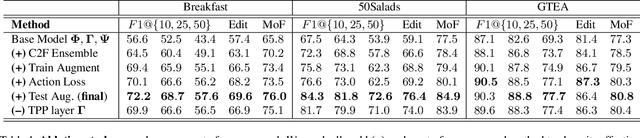


Temporal convolutional networks (TCNs) are a commonly used architecture for temporal video segmentation. TCNs however, tend to suffer from over-segmentation errors and require additional refinement modules to ensure smoothness and temporal coherency. In this work, we propose a novel temporal encoder-decoder to tackle the problem of sequence fragmentation. In particular, the decoder follows a coarse-to-fine structure with an implicit ensemble of multiple temporal resolutions. The ensembling produces smoother segmentations that are more accurate and better-calibrated, bypassing the need for additional refinement modules. In addition, we enhance our training with a multi-resolution feature-augmentation strategy to promote robustness to varying temporal resolutions. Finally, to support our architecture and encourage further sequence coherency, we propose an action loss that penalizes misclassifications at the video level. Experiments show that our stand-alone architecture, together with our novel feature-augmentation strategy and new loss, outperforms the state-of-the-art on three temporal video segmentation benchmarks.
Pretrained equivariant features improve unsupervised landmark discovery
Apr 07, 2021
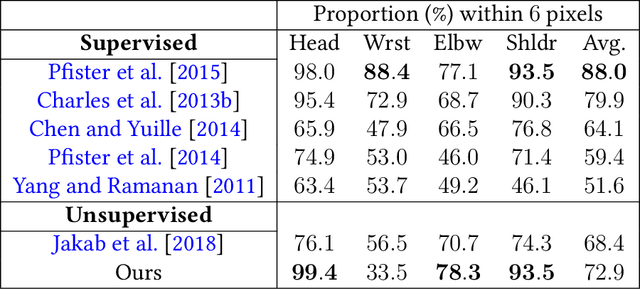
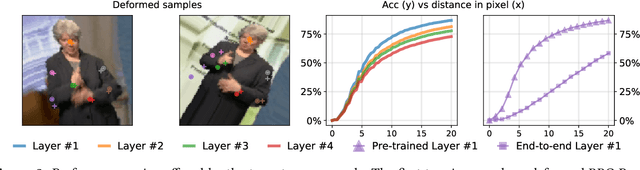

Locating semantically meaningful landmark points is a crucial component of a large number of computer vision pipelines. Because of the small number of available datasets with ground truth landmark annotations, it is important to design robust unsupervised and semi-supervised methods for landmark detection. Many of the recent unsupervised learning methods rely on the equivariance properties of landmarks to synthetic image deformations. Our work focuses on such widely used methods and sheds light on its core problem, its inability to produce equivariant intermediate convolutional features. This finding leads us to formulate a two-step unsupervised approach that overcomes this challenge by first learning powerful pixel-based features and then use the pre-trained features to learn a landmark detector by the traditional equivariance method. Our method produces state-of-the-art results in several challenging landmark detection datasets such as the BBC Pose dataset and the Cat-Head dataset. It performs comparably on a range of other benchmarks.
Uncertainty Quantification and Deep Ensembles
Jul 20, 2020



Deep Learning methods are known to suffer from calibration issues: they typically produce over-confident estimates. These problems are exacerbated in the low data regime. Although the calibration of probabilistic models is well studied, calibrating extremely over-parametrized models in the low-data regime presents unique challenges. We show that deep-ensembles do not necessarily lead to improved calibration properties. In fact, we show that standard ensembling methods, when used in conjunction with modern techniques such as mixup regularization, can lead to less calibrated models. In this text, we examine the interplay between three of the most simple and commonly used approaches to leverage deep learning when data is scarce: data-augmentation, ensembling, and post-processing calibration methods. We demonstrate that, although standard ensembling techniques certainly help to boost accuracy, the calibration of deep-ensembles relies on subtle trade-offs. Our main finding is that calibration methods such as temperature scaling need to be slightly tweaked when used with deep-ensembles and, crucially, need to be executed after the averaging process. Our simulations indicate that, in the low data regime, this simple strategy can halve the Expected Calibration Error (ECE) on a range of benchmark classification problems when compared to standard deep-ensembles.