 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Contrast-Classify For Semi-supervised Temporal Action Segmentation
Paper and Code
Dec 08, 2021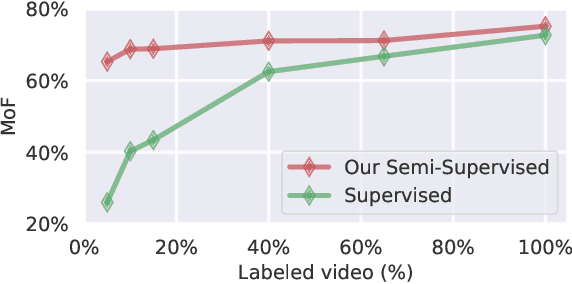



Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.