 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2F-TCN: A Framework for Semi and Fully Supervised Temporal Action Segmentation
Dec 20, 2022Temporal action segmentation tags action labels for every frame in an input untrimmed video containing multiple actions in a sequence. For the task of temporal action segmentation, we propose an encoder-decoder-style architecture named C2F-TCN featuring a "coarse-to-fine" ensemble of decoder outputs. The C2F-TCN framework is enhanced with a novel model agnostic temporal feature augmentation strategy formed by the computationally inexpensive strategy of the stochastic max-pooling of segments. It produces more accurate and well-calibrated supervised results on three benchmark action segmentation datasets. We show that the architecture is flexible for both supervised and representation learning. In line with this, we present a novel unsupervised way to learn frame-wise representation from C2F-TCN. Our unsupervised learning approach hinges on the clustering capabilities of the input features and the formation of multi-resolution features from the decoder's implicit structure. Further, we provide the first semi-supervised temporal action segmentation results by merging representation learning with conventional supervised learning. Our semi-supervised learning scheme, called ``Iterative-Contrastive-Classify (ICC)'', progressively improves in performance with more labeled data. The ICC semi-supervised learning in C2F-TCN, with 40% labeled videos, performs similar to fully supervised counterparts.
A Generalized & Robust Framework For Timestamp Supervision in Temporal Action Segmentation
Jul 20, 2022



In temporal action segmentation, Timestamp supervision requires only a handful of labelled frames per video sequence. For unlabelled frames, previous works rely on assigning hard labels, and performance rapidly collapses under subtle violations of the annotation assumptions. We propose a novel Expectation-Maximization (EM) based approach that leverages the label uncertainty of unlabelled frames and is robust enough to accommodate possible annotation errors. With accurate timestamp annotations, our proposed method produces SOTA results and even exceeds the fully-supervised setup in several metrics and datasets. When applied to timestamp annotations with missing action segments, our method presents stable performance. To further test our formulation's robustness, we introduce the new challenging annotation setup of Skip-tag supervision. This setup relaxes constraints and requires annotations of any fixed number of random frames in a video, making it more flexible than Timestamp supervision while remaining competitive.
Assembly101: A Large-Scale Multi-View Video Dataset for Understanding Procedural Activities
Mar 28, 2022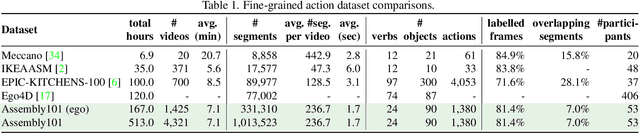

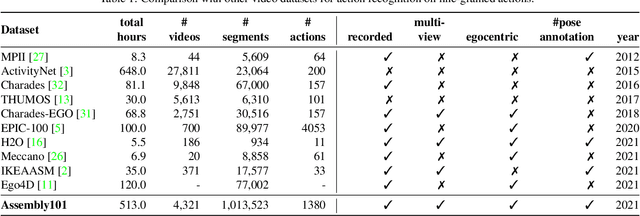

Assembly101 is a new procedural activity dataset featuring 4321 videos of people assembling and disassembling 101 "take-apart" toy vehicles. Participants work without fixed instructions, and the sequences feature rich and natural variations in action ordering, mistakes, and corrections. Assembly101 is the first multi-view action dataset, with simultaneous static (8) and egocentric (4) recordings. Sequences are annotated with more than 100K coarse and 1M fine-grained action segments, and 18M 3D hand poses. We benchmark on three action understanding tasks: recognition, anticipation and temporal segmentation. Additionally, we propose a novel task of detecting mistakes. The unique recording format and rich set of annotations allow us to investigate generalization to new toys, cross-view transfer, long-tailed distributions, and pose vs. appearance. We envision that Assembly101 will serve as a new challenge to investigate various activity understanding problems.
Iterative Contrast-Classify For Semi-supervised Temporal Action Segmentation
Dec 08, 2021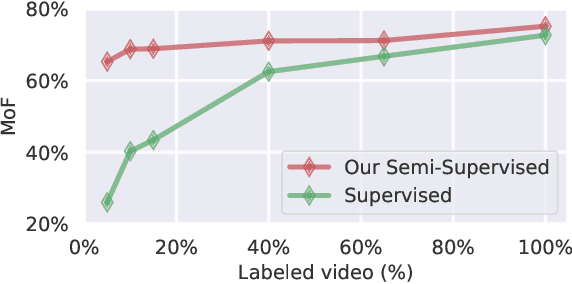



Temporal action segmentation classifies the action of each frame in (long) video sequences. Due to the high cost of frame-wise labeling, we propose the first semi-supervised method for temporal action segmentation. Our method hinges on unsupervised representation learning, which, for temporal action segmentation, poses unique challenges. Actions in untrimmed videos vary in length and have unknown labels and start/end times. Ordering of actions across videos may also vary. We propose a novel way to learn frame-wise representations from temporal convolutional networks (TCNs) by clustering input features with added time-proximity condition and multi-resolution similarity. By merging representation learning with conventional supervised learning, we develop an "Iterative-Contrast-Classify (ICC)" semi-supervised learning scheme. With more labelled data, ICC progressively improves in performance; ICC semi-supervised learning, with 40% labelled videos, performs similar to fully-supervised counterparts. Our ICC improves MoF by {+1.8, +5.6, +2.5}% on Breakfast, 50Salads and GTEA respectively for 100% labelled videos.
Coarse to Fine Multi-Resolution Temporal Convolutional Network
May 23, 2021
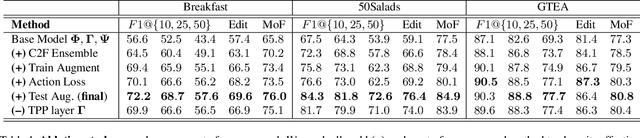


Temporal convolutional networks (TCNs) are a commonly used architecture for temporal video segmentation. TCNs however, tend to suffer from over-segmentation errors and require additional refinement modules to ensure smoothness and temporal coherency. In this work, we propose a novel temporal encoder-decoder to tackle the problem of sequence fragmentation. In particular, the decoder follows a coarse-to-fine structure with an implicit ensemble of multiple temporal resolutions. The ensembling produces smoother segmentations that are more accurate and better-calibrated, bypassing the need for additional refinement modules. In addition, we enhance our training with a multi-resolution feature-augmentation strategy to promote robustness to varying temporal resolutions. Finally, to support our architecture and encourage further sequence coherency, we propose an action loss that penalizes misclassifications at the video level. Experiments show that our stand-alone architecture, together with our novel feature-augmentation strategy and new loss, outperforms the state-of-the-art on three temporal video segmentation benchmarks.
Rethinking CNN Models for Audio Classification
Jul 22, 2020



In this paper, we show that ImageNet-Pretrained standard deep CNN models can be used as strong baseline networks for audio classification. Even though there is a significant difference between audio Spectrogram and standard ImageNet image samples, transfer learning assumptions still hold firmly. To understand what enables the ImageNet pretrained models to learn useful audio representations, we systematically study how much of pretrained weights is useful for learning spectrograms. We show (1) that for a given standard model using pretrained weights is better than using randomly initialized weights (2) qualitative results of what the CNNs learn from the spectrograms by visualizing the gradients. Besides, we show that even though we use the pretrained model weights for initialization, there is variance in performance in various output runs of the same model. This variance in performance is due to the random initialization of linear classification layer and random mini-batch orderings in multiple runs. This brings significant diversity to build stronger ensemble models with an overall improvement in accuracy. An ensemble of ImageNet pretrained DenseNet achieves 92.89% validation accuracy on the ESC-50 dataset and 87.42% validation accuracy on the UrbanSound8K dataset which is the current state-of-the-art on both of these datasets.
Temporal Aggregate Representations for Long Term Video Understanding
Jun 01, 2020



Future prediction requires reasoning from current and past observations and raises several fundamental questions. How much past information is necessary? What is a reasonable temporal scale to process the past? How much semantic abstraction is required? We address all of these questions with a flexible multi-granular temporal aggregation framework. We show that it is possible to achieve state-of-the-art results in both next action and dense anticipation using simple techniques such as max pooling and attention. To demonstrate the anticipation capabilities of our model, we conduct experiments on the Breakfast Actions, 50Salads and EPIC-Kitchens datasets where we achieve state-of-the-art or comparable results. We also show that our model can be used for temporal video segmentation and action recognition with minimal modifications.