 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
PALM: A Dataset and Baseline for Learning Multi-subject Hand Prior
Nov 07, 2025

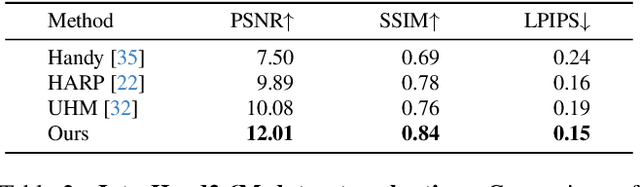
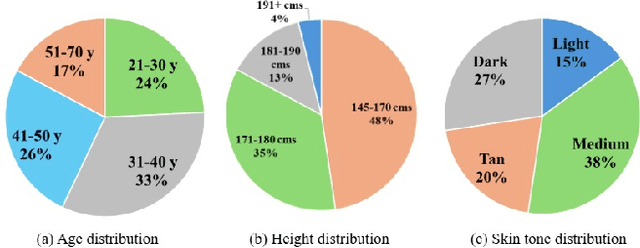
The ability to grasp objects, signal with gestures, and share emotion through touch all stem from the unique capabilities of human hands. Yet creating high-quality personalized hand avatars from images remains challenging due to complex geometry, appearance, and articulation, particularly under unconstrained lighting and limited views. Progress has also been limited by the lack of datasets that jointly provide accurate 3D geometry, high-resolution multiview imagery, and a diverse population of subjects. To address this, we present PALM, a large-scale dataset comprising 13k high-quality hand scans from 263 subjects and 90k multi-view images, capturing rich variation in skin tone, age, and geometry. To show its utility, we present a baseline PALM-Net, a multi-subject prior over hand geometry and material properties learned via physically based inverse rendering, enabling realistic, relightable single-image hand avatar personalization. PALM's scale and diversity make it a valuable real-world resource for hand modeling and related research.
Long-Tail Temporal Action Segmentation with Group-wise Temporal Logit Adjustment
Aug 19, 2024
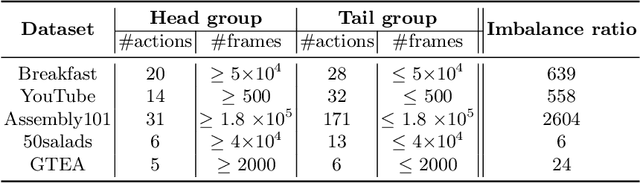
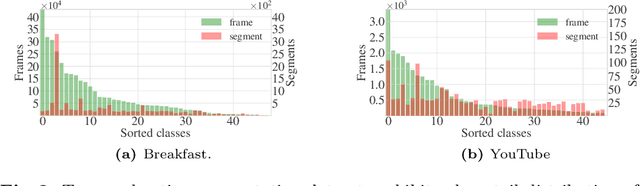
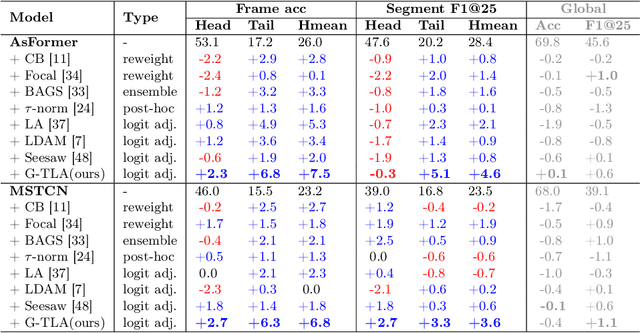
Procedural activity videos often exhibit a long-tailed action distribution due to varying action frequencies and durations. However, state-of-the-art temporal action segmentation methods overlook the long tail and fail to recognize tail actions. Existing long-tail methods make class-independent assumptions and struggle to identify tail classes when applied to temporal segmentation frameworks. This work proposes a novel group-wise temporal logit adjustment~(G-TLA) framework that combines a group-wise softmax formulation while leveraging activity information and action ordering for logit adjustment. The proposed framework significantly improves in segmenting tail actions without any performance loss on head actions.
X-MIC: Cross-Modal Instance Conditioning for Egocentric Action Generalization
Mar 28, 2024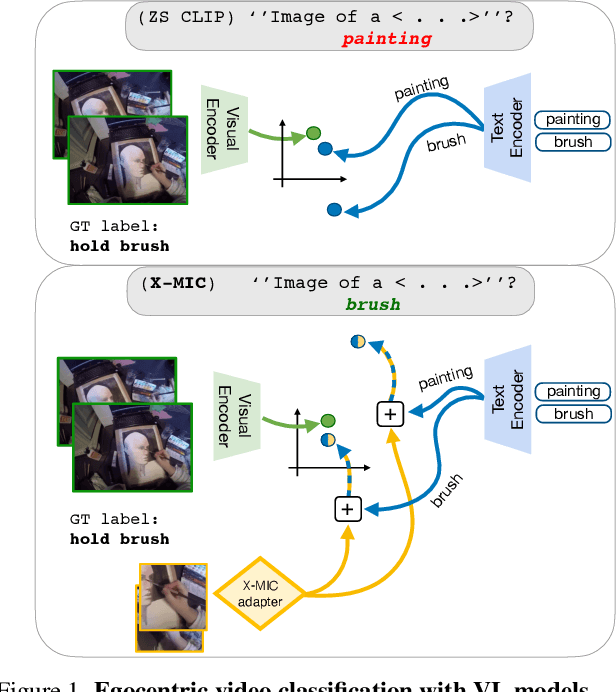
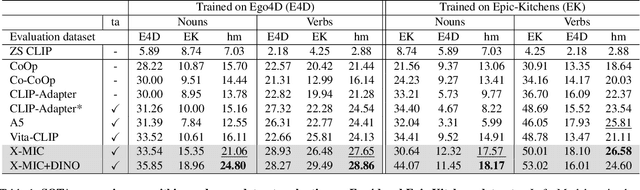
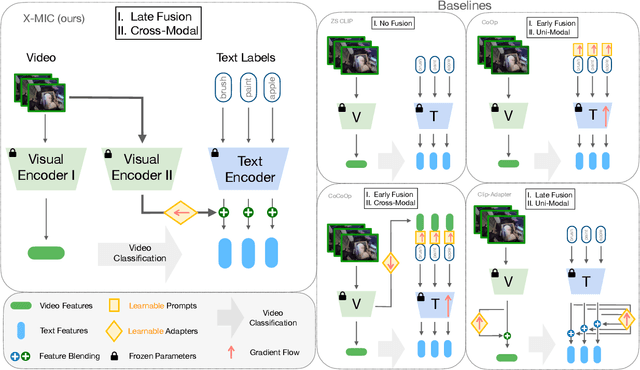
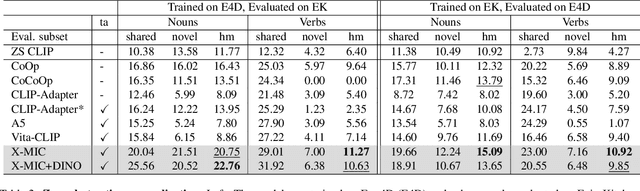
Lately, there has been growing interest in adapting vision-language models (VLMs) to image and third-person video classification due to their success in zero-shot recognition. However, the adaptation of these models to egocentric videos has been largely unexplored. To address this gap, we propose a simple yet effective cross-modal adaptation framework, which we call X-MIC. Using a video adapter, our pipeline learns to align frozen text embeddings to each egocentric video directly in the shared embedding space. Our novel adapter architecture retains and improves generalization of the pre-trained VLMs by disentangling learnable temporal modeling and frozen visual encoder. This results in an enhanced alignment of text embeddings to each egocentric video, leading to a significant improvement in cross-dataset generalization. We evaluate our approach on the Epic-Kitchens, Ego4D, and EGTEA datasets for fine-grained cross-dataset action generalization, demonstrating the effectiveness of our method. Code is available at https://github.com/annusha/xmic
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
Mar 26, 2024



Generating natural hand-object interactions in 3D is challenging as the resulting hand and object motions are expected to be physically plausible and semantically meaningful. Furthermore, generalization to unseen objects is hindered by the limited scale of available hand-object interaction datasets. We propose DiffH2O, a novel method to synthesize realistic, one or two-handed object interactions from provided text prompts and geometry of the object. The method introduces three techniques that enable effective learning from limited data. First, we decompose the task into a grasping stage and a text-based interaction stage and use separate diffusion models for each. In the grasping stage, the model only generates hand motions, whereas in the interaction phase both hand and object poses are synthesized. Second, we propose a compact representation that tightly couples hand and object poses. Third, we propose two different guidance schemes to allow more control of the generated motions: grasp guidance and detailed textual guidance. Grasp guidance takes a single target grasping pose and guides the diffusion model to reach this grasp at the end of the grasping stage, which provides control over the grasping pose. Given a grasping motion from this stage, multiple different actions can be prompted in the interaction phase. For textual guidance, we contribute comprehensive text descriptions to the GRAB dataset and show that they enable our method to have more fine-grained control over hand-object interactions. Our quantitative and qualitative evaluation demonstrates that the proposed method outperforms baseline methods and leads to natural hand-object motions. Moreover, we demonstrate the practicality of our framework by utilizing a hand pose estimate from an off-the-shelf pose estimator for guidance, and then sampling multiple different actions in the interaction stage.
On the Utility of 3D Hand Poses for Action Recognition
Mar 14, 2024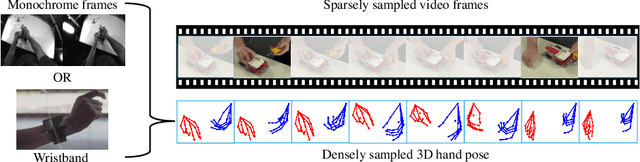
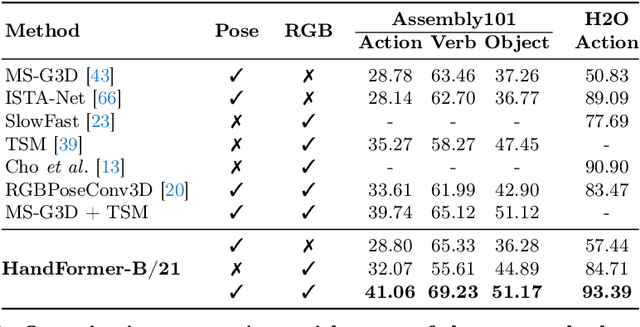
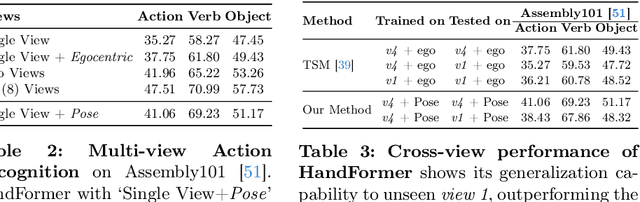
3D hand poses are an under-explored modality for action recognition. Poses are compact yet informative and can greatly benefit applications with limited compute budgets. However, poses alone offer an incomplete understanding of actions, as they cannot fully capture objects and environments with which humans interact. To efficiently model hand-object interactions, we propose HandFormer, a novel multimodal transformer. HandFormer combines 3D hand poses at a high temporal resolution for fine-grained motion modeling with sparsely sampled RGB frames for encoding scene semantics. Observing the unique characteristics of hand poses, we temporally factorize hand modeling and represent each joint by its short-term trajectories. This factorized pose representation combined with sparse RGB samples is remarkably efficient and achieves high accuracy. Unimodal HandFormer with only hand poses outperforms existing skeleton-based methods at 5x fewer FLOPs. With RGB, we achieve new state-of-the-art performance on Assembly101 and H2O with significant improvements in egocentric action recognition.
Opening the Vocabulary of Egocentric Actions
Aug 22, 2023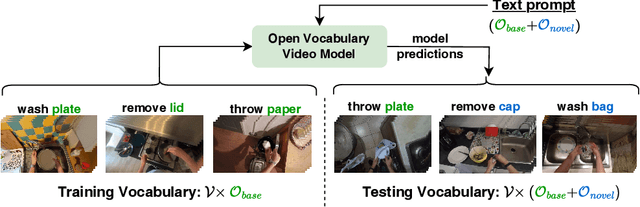
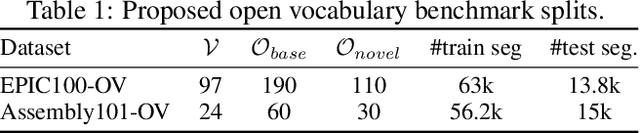
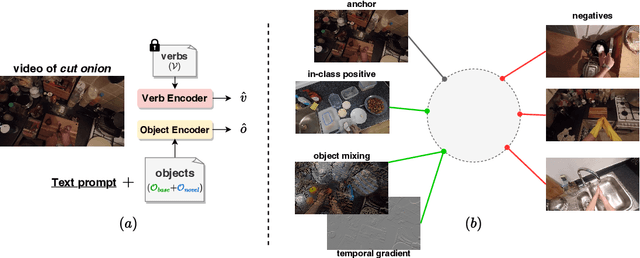
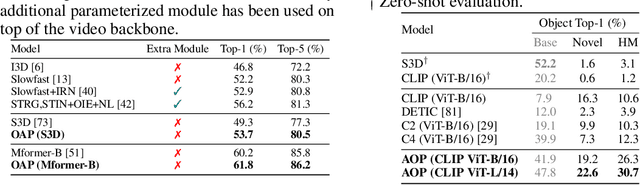
Human actions in egocentric videos are often hand-object interactions composed from a verb (performed by the hand) applied to an object. Despite their extensive scaling up, egocentric datasets still face two limitations - sparsity of action compositions and a closed set of interacting objects. This paper proposes a novel open vocabulary action recognition task. Given a set of verbs and objects observed during training, the goal is to generalize the verbs to an open vocabulary of actions with seen and novel objects. To this end, we decouple the verb and object predictions via an object-agnostic verb encoder and a prompt-based object encoder. The prompting leverages CLIP representations to predict an open vocabulary of interacting objects. We create open vocabulary benchmarks on the EPIC-KITCHENS-100 and Assembly101 datasets; whereas closed-action methods fail to generalize, our proposed method is effective. In addition, our object encoder significantly outperforms existing open-vocabulary visual recognition methods in recognizing novel interacting objects.
Every Mistake Counts in Assembly
Jul 31, 2023



One promising use case of AI assistants is to help with complex procedures like cooking, home repair, and assembly tasks. Can we teach the assistant to interject after the user makes a mistake? This paper targets the problem of identifying ordering mistakes in assembly procedures. We propose a system that can detect ordering mistakes by utilizing a learned knowledge base. Our framework constructs a knowledge base with spatial and temporal beliefs based on observed mistakes. Spatial beliefs depict the topological relationship of the assembling components, while temporal beliefs aggregate prerequisite actions as ordering constraints. With an episodic memory design, our algorithm can dynamically update and construct the belief sets as more actions are observed, all in an online fashion. We demonstrate experimentally that our inferred spatial and temporal beliefs are capable of identifying incorrect orderings in real-world action sequences. To construct the spatial beliefs, we collect a new set of coarse-level action annotations for Assembly101 based on the positioning of the toy parts. Finally, we demonstrate the superior performance of our belief inference algorithm in detecting ordering mistakes on the Assembly101 dataset.
AssemblyHands: Towards Egocentric Activity Understanding via 3D Hand Pose Estimation
Apr 24, 2023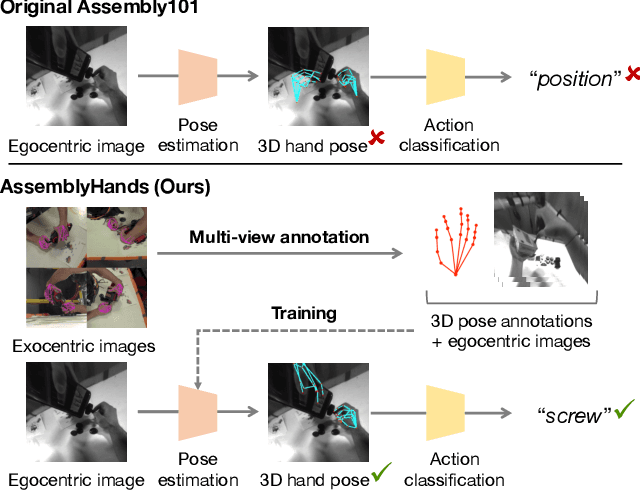
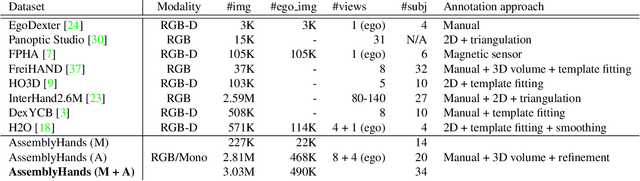
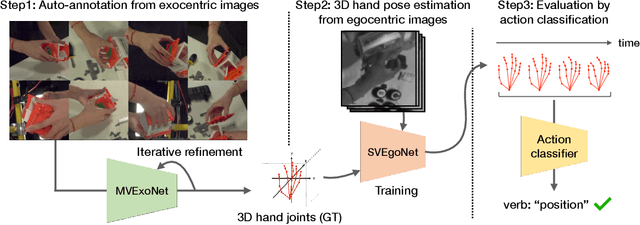
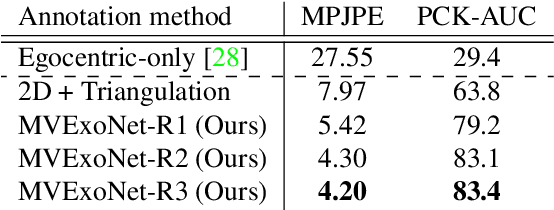
We present AssemblyHands, a large-scale benchmark dataset with accurate 3D hand pose annotations, to facilitate the study of egocentric activities with challenging hand-object interactions. The dataset includes synchronized egocentric and exocentric images sampled from the recent Assembly101 dataset, in which participants assemble and disassemble take-apart toys. To obtain high-quality 3D hand pose annotations for the egocentric images, we develop an efficient pipeline, where we use an initial set of manual annotations to train a model to automatically annotate a much larger dataset. Our annotation model uses multi-view feature fusion and an iterative refinement scheme, and achieves an average keypoint error of 4.20 mm, which is 85% lower than the error of the original annotations in Assembly101. AssemblyHands provides 3.0M annotated images, including 490K egocentric images, making it the largest existing benchmark dataset for egocentric 3D hand pose estimation. Using this data, we develop a strong single-view baseline of 3D hand pose estimation from egocentric images. Furthermore, we design a novel action classification task to evaluate predicted 3D hand poses. Our study shows that having higher-quality hand poses directly improves the ability to recognize actions.
Temporal Action Segmentation: An Analysis of Modern Technique
Oct 19, 2022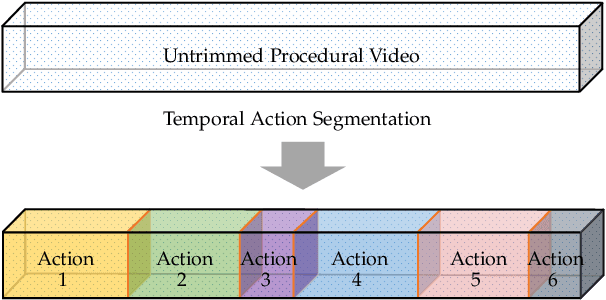
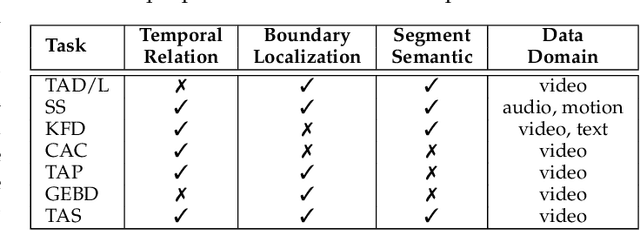

Temporal action segmentation from videos aims at the dense labeling of video frames with multiple action classes in minutes-long videos. Categorized as a long-range video understanding task, researchers have proposed an extended collection of methods and examined their performance using various benchmarks. Despite the rapid development of action segmentation techniques in recent years, there has been no systematic survey in such fields. To this end, in this survey, we analyze and summarize the main contributions and trends for this task. Specifically, we first examine the task definition, common benchmarks, types of supervision, and popular evaluation measures. Furthermore, we systematically investigate two fundamental aspects of this topic, i.e., frame representation and temporal modeling, which are widely and extensively studied in the literature. We then comprehensively review existing temporal action segmentation works, each categorized by their form of supervision. Finally, we conclude our survey by highlighting and identifying several open topics for research. In addition, we supplement our survey with a curated list of temporal action segmentation resources, which is available at https://github.com/atlas-eccv22/awesome-temporal-action-segmentation.