Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report: Temporal Aggregate Representations
Paper and Code
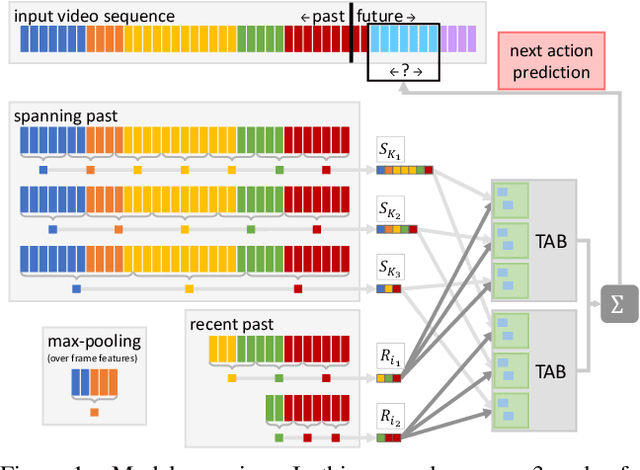

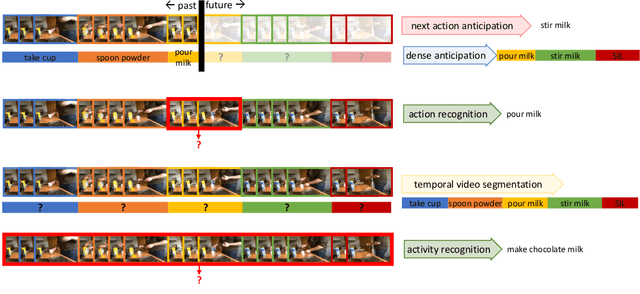
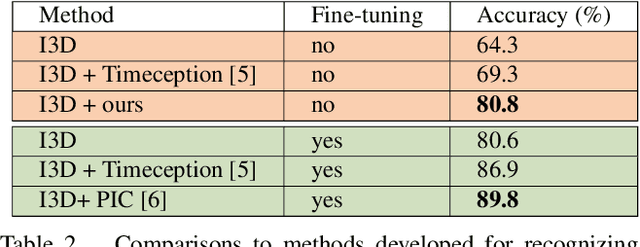
This technical report extends our work presented in [9] with more experiments. In [9], we tackle long-term video understanding, which requires reasoning from current and past or future observations and raises several fundamental questions. How should temporal or sequential relationships be modelled? What temporal extent of information and context needs to be processed? At what temporal scale should they be derived? [9] addresses these questions with a flexible multi-granular temporal aggregation framework. In this report, we conduct further experiments with this framework on different tasks and a new dataset, EPIC-KITCHENS-100.
View paper on