 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuMoCon: Concept Discovery for Human Motion Understanding
May 27, 2025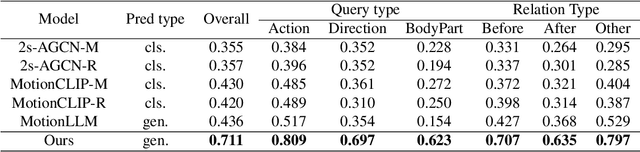
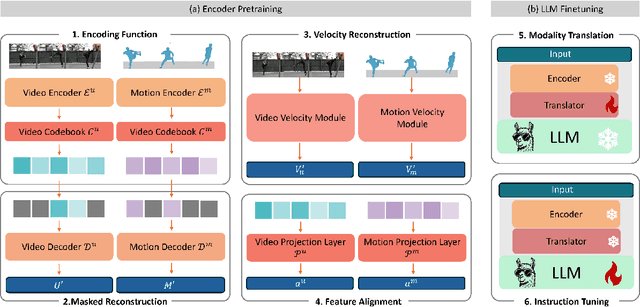
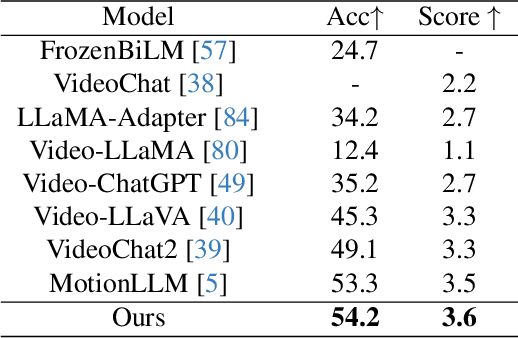
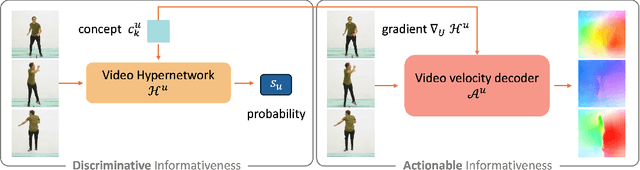
We present HuMoCon, a novel motion-video understanding framework designed for advanced human behavior analysis. The core of our method is a human motion concept discovery framework that efficiently trains multi-modal encoders to extract semantically meaningful and generalizable features. HuMoCon addresses key challenges in motion concept discovery for understanding and reasoning, including the lack of explicit multi-modality feature alignment and the loss of high-frequency information in masked autoencoding frameworks. Our approach integrates a feature alignment strategy that leverages video for contextual understanding and motion for fine-grained interaction modeling, further with a velocity reconstruction mechanism to enhance high-frequency feature expression and mitigate temporal over-smoothing. Comprehensive experiments on standard benchmarks demonstrate that HuMoCon enables effective motion concept discovery and significantly outperforms state-of-the-art methods in training large models for human motion understanding. We will open-source the associated code with our paper.
* 18 pages, 10 figures
POET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision
Oct 08, 2024While passive surfaces offer numerous benefits for interaction in mixed reality, reliably detecting touch input solely from head-mounted cameras has been a long-standing challenge. Camera specifics, hand self-occlusion, and rapid movements of both head and fingers introduce considerable uncertainty about the exact location of touch events. Existing methods have thus not been capable of achieving the performance needed for robust interaction. In this paper, we present a real-time pipeline that detects touch input from all ten fingers on any physical surface, purely based on egocentric hand tracking. Our method TouchInsight comprises a neural network to predict the moment of a touch event, the finger making contact, and the touch location. TouchInsight represents locations through a bivariate Gaussian distribution to account for uncertainties due to sensing inaccuracies, which we resolve through contextual priors to accurately infer intended user input. We first evaluated our method offline and found that it locates input events with a mean error of 6.3 mm, and accurately detects touch events (F1=0.99) and identifies the finger used (F1=0.96). In an online evaluation, we then demonstrate the effectiveness of our approach for a core application of dexterous touch input: two-handed text entry. In our study, participants typed 37.0 words per minute with an uncorrected error rate of 2.9% on average.
X-MIC: Cross-Modal Instance Conditioning for Egocentric Action Generalization
Mar 28, 2024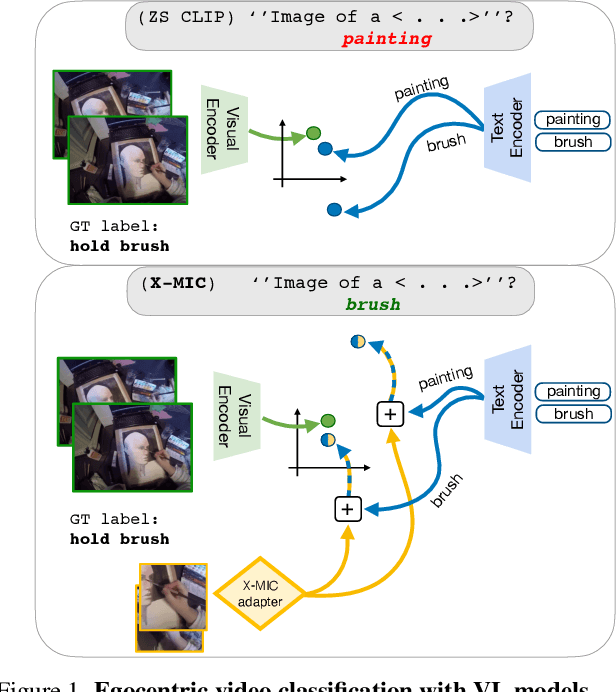
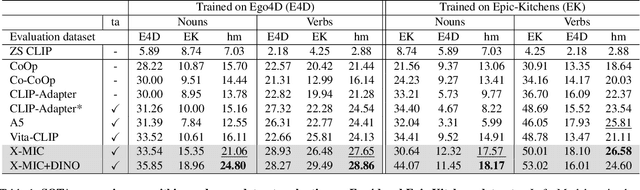
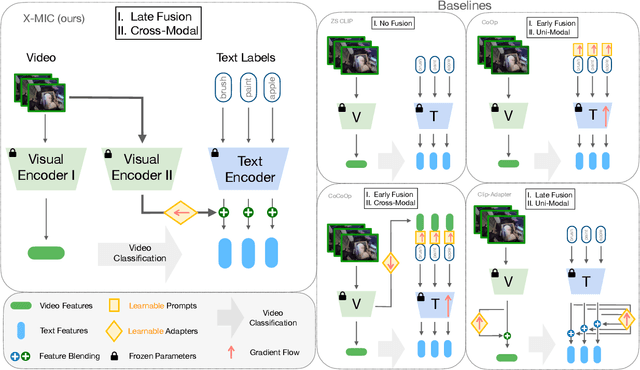
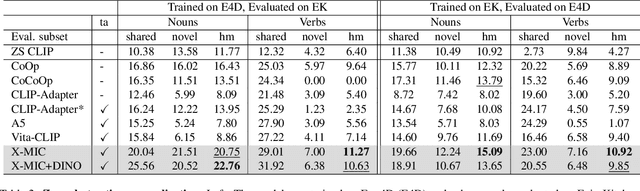
Lately, there has been growing interest in adapting vision-language models (VLMs) to image and third-person video classification due to their success in zero-shot recognition. However, the adaptation of these models to egocentric videos has been largely unexplored. To address this gap, we propose a simple yet effective cross-modal adaptation framework, which we call X-MIC. Using a video adapter, our pipeline learns to align frozen text embeddings to each egocentric video directly in the shared embedding space. Our novel adapter architecture retains and improves generalization of the pre-trained VLMs by disentangling learnable temporal modeling and frozen visual encoder. This results in an enhanced alignment of text embeddings to each egocentric video, leading to a significant improvement in cross-dataset generalization. We evaluate our approach on the Epic-Kitchens, Ego4D, and EGTEA datasets for fine-grained cross-dataset action generalization, demonstrating the effectiveness of our method. Code is available at https://github.com/annusha/xmic
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
Mar 26, 2024



Generating natural hand-object interactions in 3D is challenging as the resulting hand and object motions are expected to be physically plausible and semantically meaningful. Furthermore, generalization to unseen objects is hindered by the limited scale of available hand-object interaction datasets. We propose DiffH2O, a novel method to synthesize realistic, one or two-handed object interactions from provided text prompts and geometry of the object. The method introduces three techniques that enable effective learning from limited data. First, we decompose the task into a grasping stage and a text-based interaction stage and use separate diffusion models for each. In the grasping stage, the model only generates hand motions, whereas in the interaction phase both hand and object poses are synthesized. Second, we propose a compact representation that tightly couples hand and object poses. Third, we propose two different guidance schemes to allow more control of the generated motions: grasp guidance and detailed textual guidance. Grasp guidance takes a single target grasping pose and guides the diffusion model to reach this grasp at the end of the grasping stage, which provides control over the grasping pose. Given a grasping motion from this stage, multiple different actions can be prompted in the interaction phase. For textual guidance, we contribute comprehensive text descriptions to the GRAB dataset and show that they enable our method to have more fine-grained control over hand-object interactions. Our quantitative and qualitative evaluation demonstrates that the proposed method outperforms baseline methods and leads to natural hand-object motions. Moreover, we demonstrate the practicality of our framework by utilizing a hand pose estimate from an off-the-shelf pose estimator for guidance, and then sampling multiple different actions in the interaction stage.
On the Utility of 3D Hand Poses for Action Recognition
Mar 14, 2024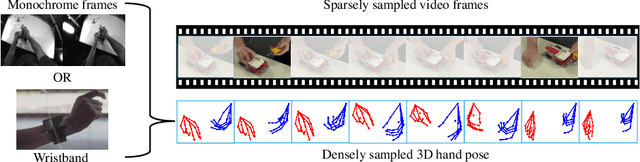
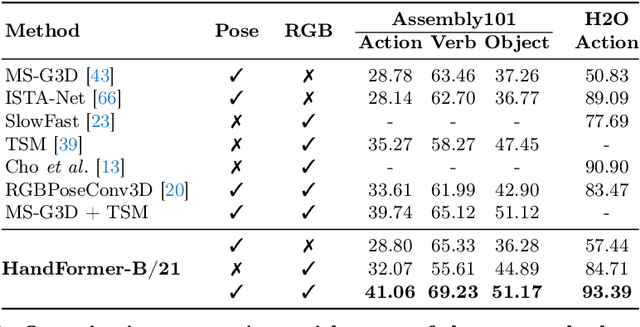
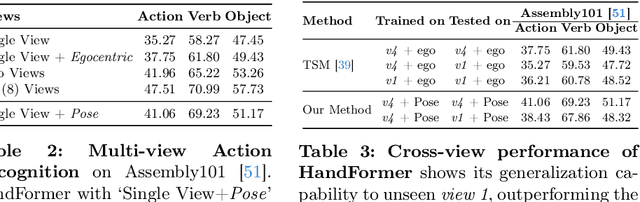
3D hand poses are an under-explored modality for action recognition. Poses are compact yet informative and can greatly benefit applications with limited compute budgets. However, poses alone offer an incomplete understanding of actions, as they cannot fully capture objects and environments with which humans interact. To efficiently model hand-object interactions, we propose HandFormer, a novel multimodal transformer. HandFormer combines 3D hand poses at a high temporal resolution for fine-grained motion modeling with sparsely sampled RGB frames for encoding scene semantics. Observing the unique characteristics of hand poses, we temporally factorize hand modeling and represent each joint by its short-term trajectories. This factorized pose representation combined with sparse RGB samples is remarkably efficient and achieves high accuracy. Unimodal HandFormer with only hand poses outperforms existing skeleton-based methods at 5x fewer FLOPs. With RGB, we achieve new state-of-the-art performance on Assembly101 and H2O with significant improvements in egocentric action recognition.
BID: Boundary-Interior Decoding for Unsupervised Temporal Action Localization Pre-Trainin
Mar 12, 2024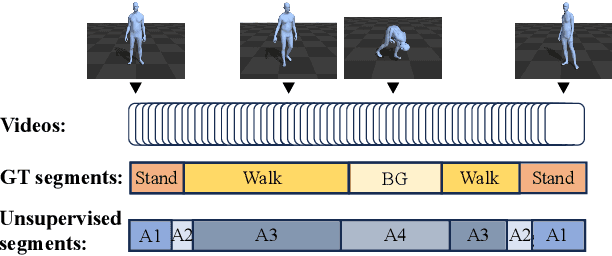
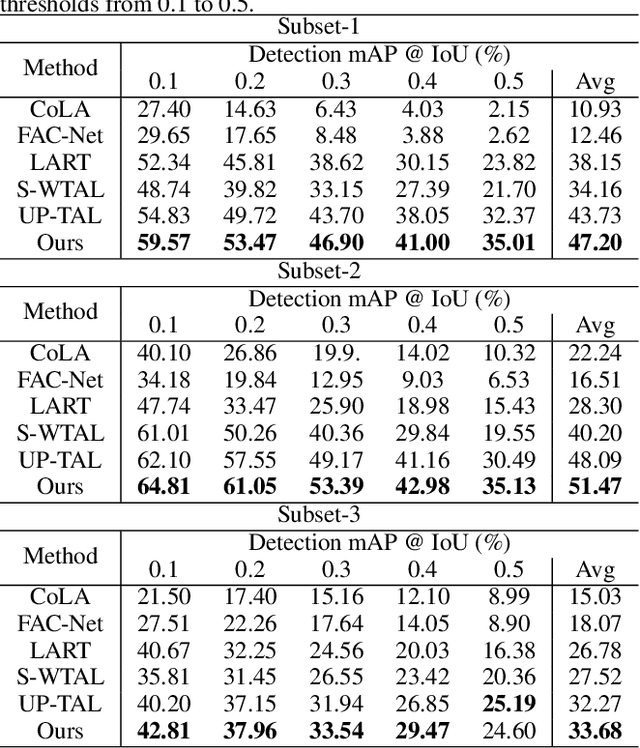
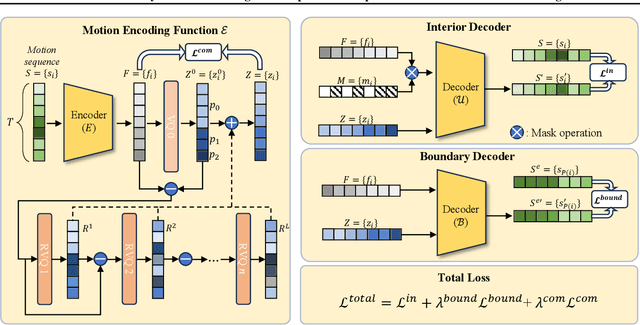
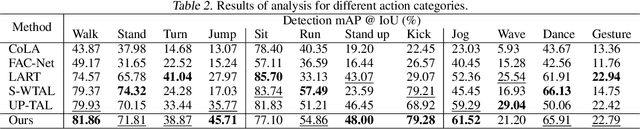
Skeleton-based motion representations are robust for action localization and understanding for their invariance to perspective, lighting, and occlusion, compared with images. Yet, they are often ambiguous and incomplete when taken out of context, even for human annotators. As infants discern gestures before associating them with words, actions can be conceptualized before being grounded with labels. Therefore, we propose the first unsupervised pre-training framework, Boundary-Interior Decoding (BID), that partitions a skeleton-based motion sequence into discovered semantically meaningful pre-action segments. By fine-tuning our pre-training network with a small number of annotated data, we show results out-performing SOTA methods by a large margin.
Opening the Vocabulary of Egocentric Actions
Aug 22, 2023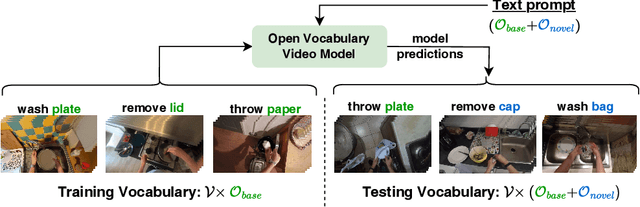
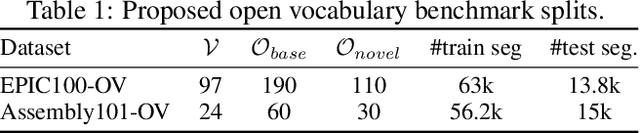
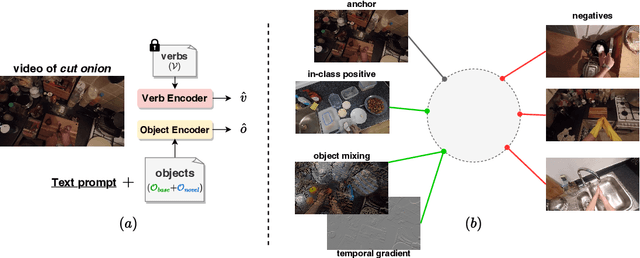
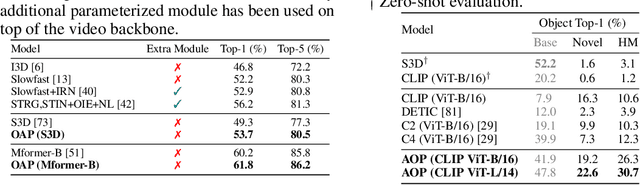
Human actions in egocentric videos are often hand-object interactions composed from a verb (performed by the hand) applied to an object. Despite their extensive scaling up, egocentric datasets still face two limitations - sparsity of action compositions and a closed set of interacting objects. This paper proposes a novel open vocabulary action recognition task. Given a set of verbs and objects observed during training, the goal is to generalize the verbs to an open vocabulary of actions with seen and novel objects. To this end, we decouple the verb and object predictions via an object-agnostic verb encoder and a prompt-based object encoder. The prompting leverages CLIP representations to predict an open vocabulary of interacting objects. We create open vocabulary benchmarks on the EPIC-KITCHENS-100 and Assembly101 datasets; whereas closed-action methods fail to generalize, our proposed method is effective. In addition, our object encoder significantly outperforms existing open-vocabulary visual recognition methods in recognizing novel interacting objects.
Every Mistake Counts in Assembly
Jul 31, 2023



One promising use case of AI assistants is to help with complex procedures like cooking, home repair, and assembly tasks. Can we teach the assistant to interject after the user makes a mistake? This paper targets the problem of identifying ordering mistakes in assembly procedures. We propose a system that can detect ordering mistakes by utilizing a learned knowledge base. Our framework constructs a knowledge base with spatial and temporal beliefs based on observed mistakes. Spatial beliefs depict the topological relationship of the assembling components, while temporal beliefs aggregate prerequisite actions as ordering constraints. With an episodic memory design, our algorithm can dynamically update and construct the belief sets as more actions are observed, all in an online fashion. We demonstrate experimentally that our inferred spatial and temporal beliefs are capable of identifying incorrect orderings in real-world action sequences. To construct the spatial beliefs, we collect a new set of coarse-level action annotations for Assembly101 based on the positioning of the toy parts. Finally, we demonstrate the superior performance of our belief inference algorithm in detecting ordering mistakes on the Assembly101 dataset.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022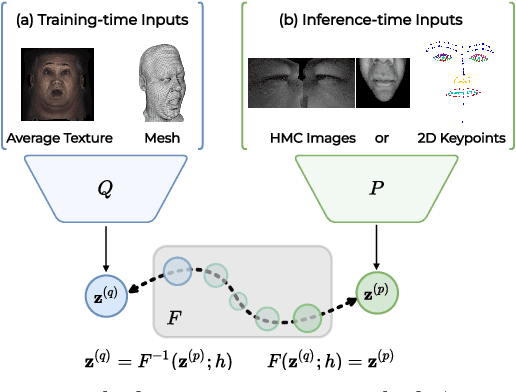
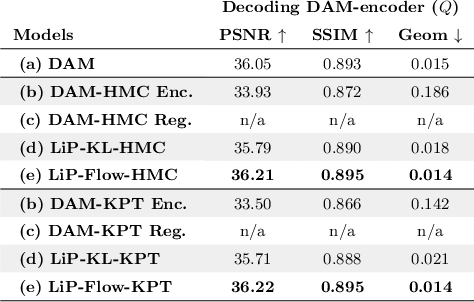

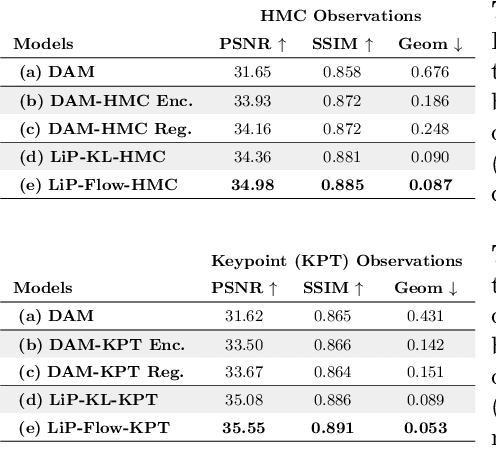
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.