 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Ego-Centric modeling of Human-Object interactions
Aug 29, 2025
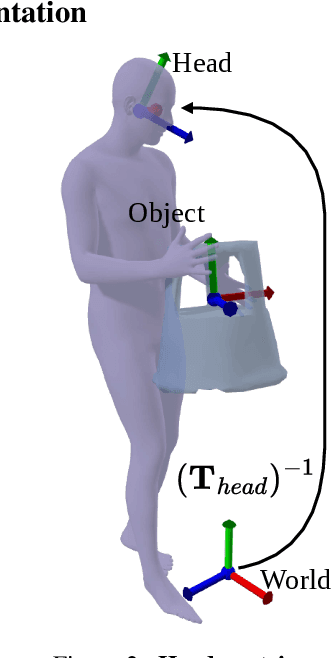
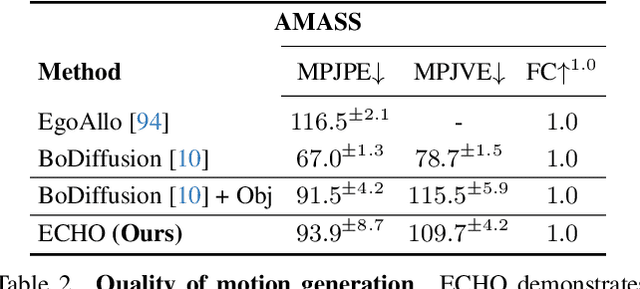
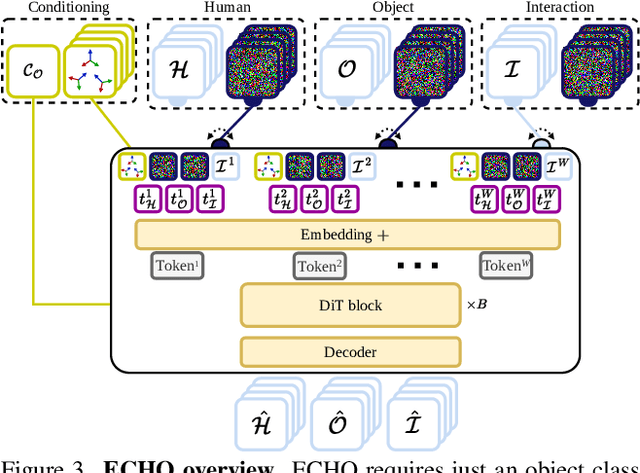
Modeling human-object interactions (HOI) from an egocentric perspective is a largely unexplored yet important problem due to the increasing adoption of wearable devices, such as smart glasses and watches. We investigate how much information about interaction can be recovered from only head and wrists tracking. Our answer is ECHO (Ego-Centric modeling of Human-Object interactions), which, for the first time, proposes a unified framework to recover three modalities: human pose, object motion, and contact from such minimal observation. ECHO employs a Diffusion Transformer architecture and a unique three-variate diffusion process, which jointly models human motion, object trajectory, and contact sequence, allowing for flexible input configurations. Our method operates in a head-centric canonical space, enhancing robustness to global orientation. We propose a conveyor-based inference, which progressively increases the diffusion timestamp with the frame position, allowing us to process sequences of any length. Through extensive evaluation, we demonstrate that ECHO outperforms existing methods that do not offer the same flexibility, setting a state-of-the-art in egocentric HOI reconstruction.
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Dec 19, 2023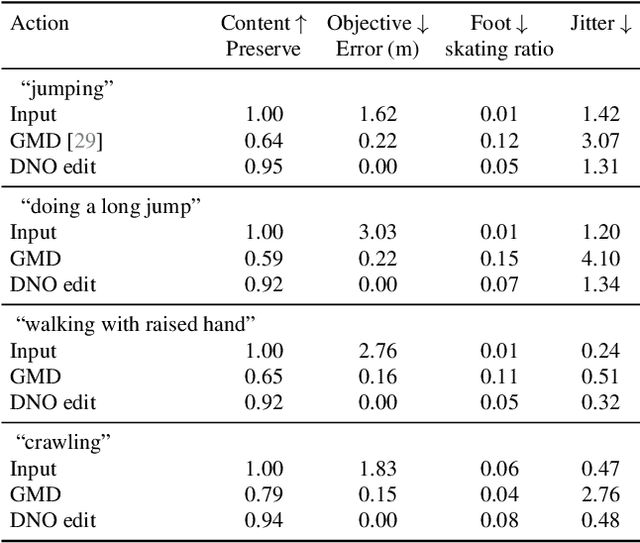
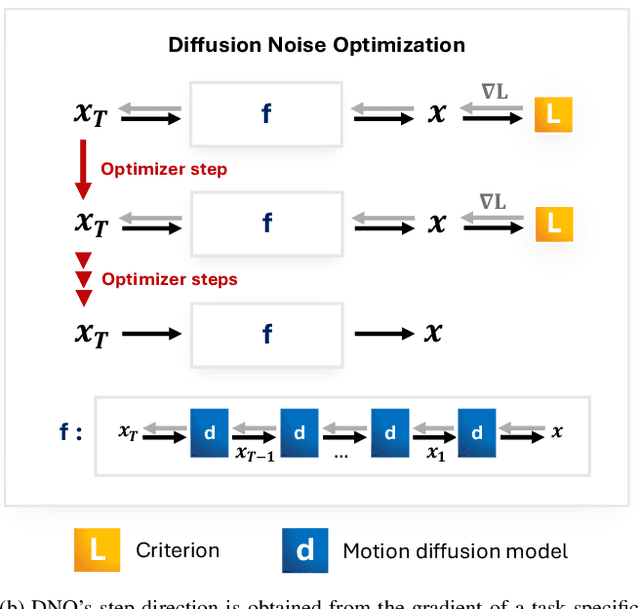
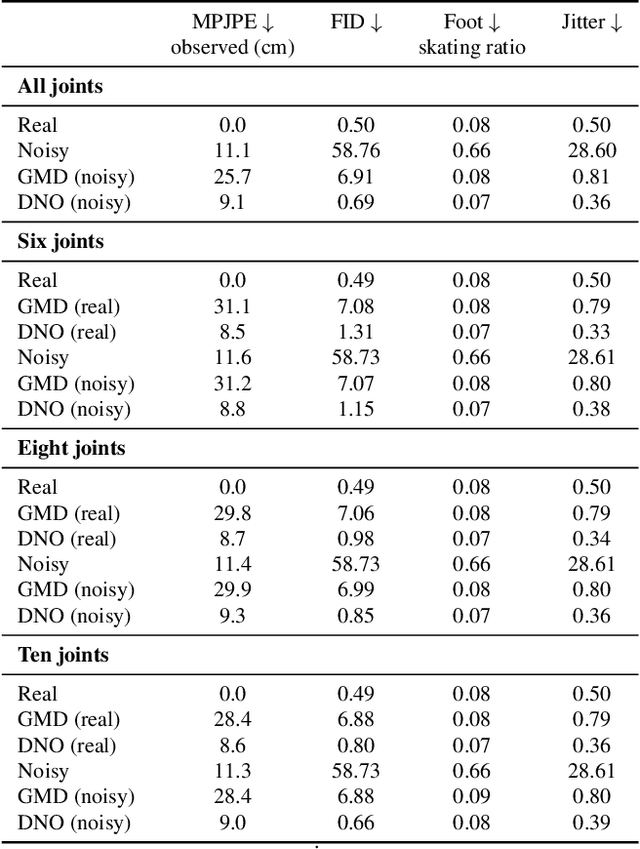

We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
Physically Plausible Full-Body Hand-Object Interaction Synthesis
Sep 14, 2023
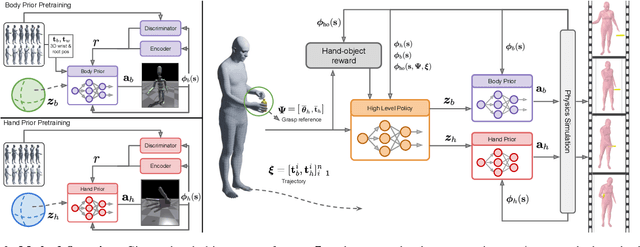
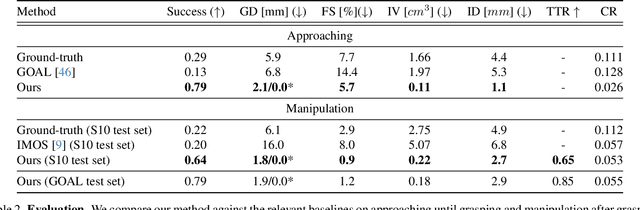
We propose a physics-based method for synthesizing dexterous hand-object interactions in a full-body setting. While recent advancements have addressed specific facets of human-object interactions, a comprehensive physics-based approach remains a challenge. Existing methods often focus on isolated segments of the interaction process and rely on data-driven techniques that may result in artifacts. In contrast, our proposed method embraces reinforcement learning (RL) and physics simulation to mitigate the limitations of data-driven approaches. Through a hierarchical framework, we first learn skill priors for both body and hand movements in a decoupled setting. The generic skill priors learn to decode a latent skill embedding into the motion of the underlying part. A high-level policy then controls hand-object interactions in these pretrained latent spaces, guided by task objectives of grasping and 3D target trajectory following. It is trained using a novel reward function that combines an adversarial style term with a task reward, encouraging natural motions while fulfilling the task incentives. Our method successfully accomplishes the complete interaction task, from approaching an object to grasping and subsequent manipulation. We compare our approach against kinematics-based baselines and show that it leads to more physically plausible motions.
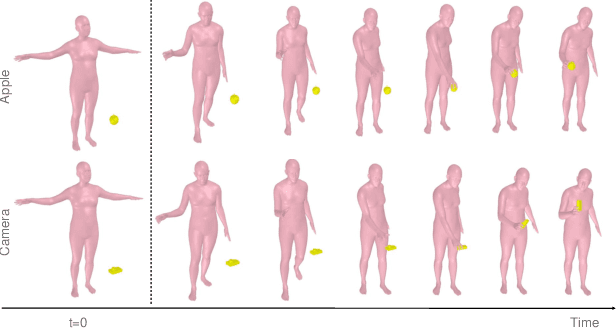
Reconstructing Action-Conditioned Human-Object Interactions Using Commonsense Knowledge Priors
Sep 06, 2022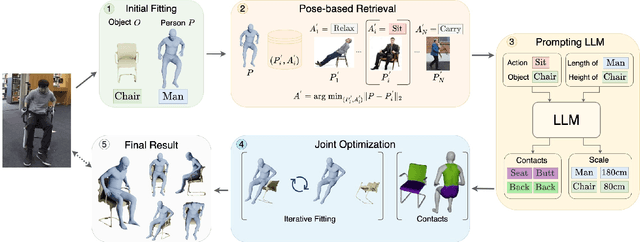
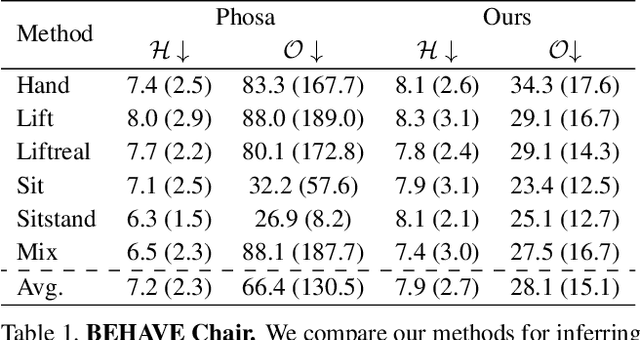
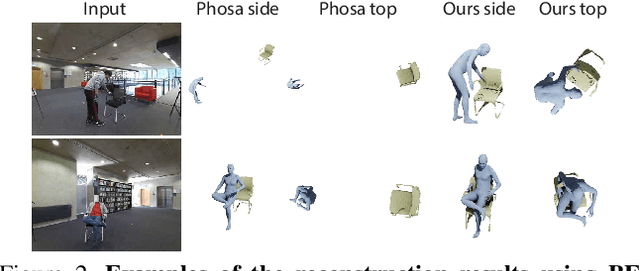
We present a method for inferring diverse 3D models of human-object interactions from images. Reasoning about how humans interact with objects in complex scenes from a single 2D image is a challenging task given ambiguities arising from the loss of information through projection. In addition, modeling 3D interactions requires the generalization ability towards diverse object categories and interaction types. We propose an action-conditioned modeling of interactions that allows us to infer diverse 3D arrangements of humans and objects without supervision on contact regions or 3D scene geometry. Our method extracts high-level commonsense knowledge from large language models (such as GPT-3), and applies them to perform 3D reasoning of human-object interactions. Our key insight is priors extracted from large language models can help in reasoning about human-object contacts from textural prompts only. We quantitatively evaluate the inferred 3D models on a large human-object interaction dataset and show how our method leads to better 3D reconstructions. We further qualitatively evaluate the effectiveness of our method on real images and demonstrate its generalizability towards interaction types and object categories.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022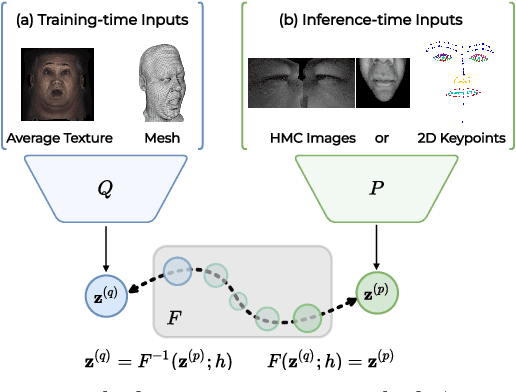
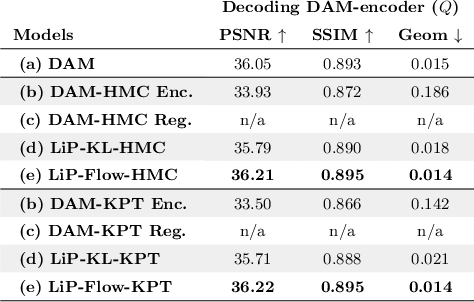

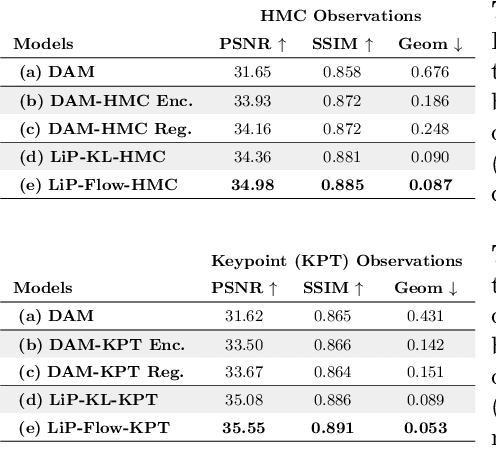
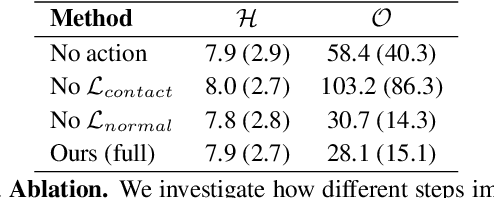
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.
D-Grasp: Physically Plausible Dynamic Grasp Synthesis for Hand-Object Interactions
Dec 01, 2021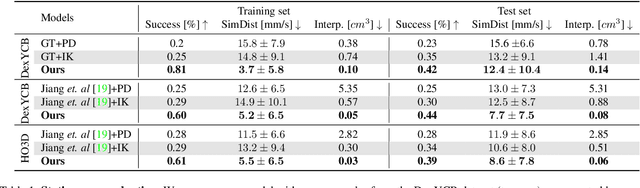
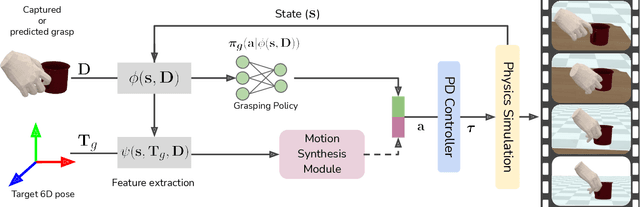
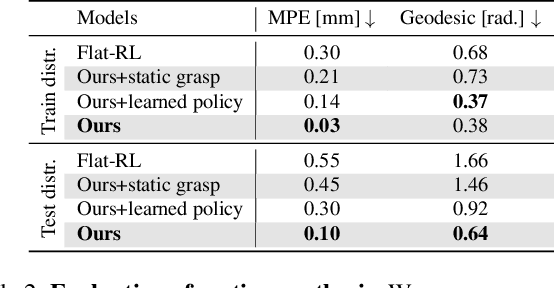
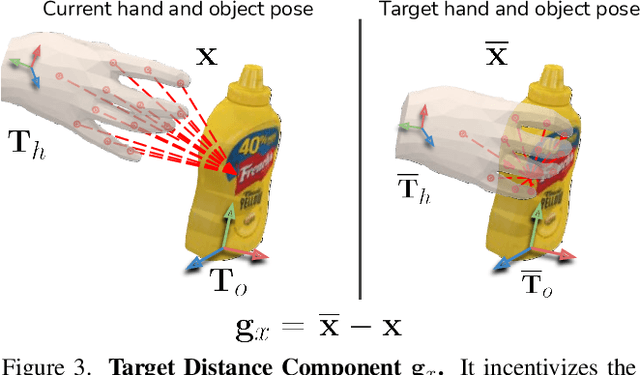
We introduce the dynamic grasp synthesis task: given an object with a known 6D pose and a grasp reference, our goal is to generate motions that move the object to a target 6D pose. This is challenging, because it requires reasoning about the complex articulation of the human hand and the intricate physical interaction with the object. We propose a novel method that frames this problem in the reinforcement learning framework and leverages a physics simulation, both to learn and to evaluate such dynamic interactions. A hierarchical approach decomposes the task into low-level grasping and high-level motion synthesis. It can be used to generate novel hand sequences that approach, grasp, and move an object to a desired location, while retaining human-likeness. We show that our approach leads to stable grasps and generates a wide range of motions. Furthermore, even imperfect labels can be corrected by our method to generate dynamic interaction sequences. Video is available at https://eth-ait.github.io/d-grasp/ .
Convolutional Autoencoders for Human Motion Infilling
Oct 22, 2020
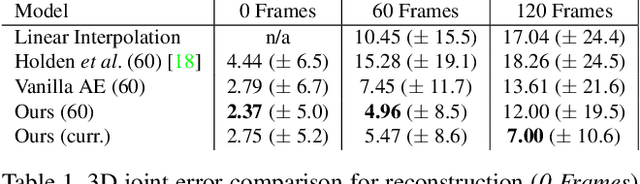
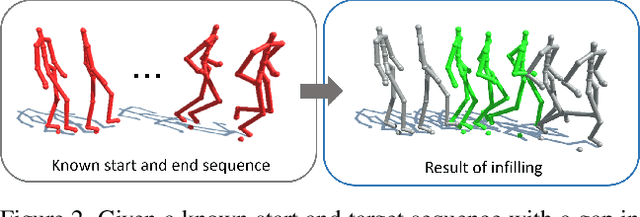
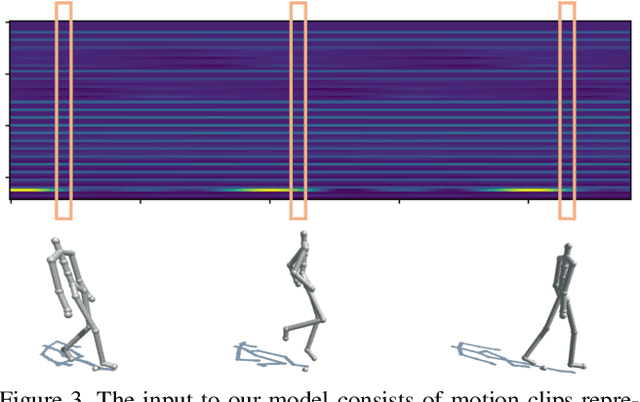
In this paper we propose a convolutional autoencoder to address the problem of motion infilling for 3D human motion data. Given a start and end sequence, motion infilling aims to complete the missing gap in between, such that the filled in poses plausibly forecast the start sequence and naturally transition into the end sequence. To this end, we propose a single, end-to-end trainable convolutional autoencoder. We show that a single model can be used to create natural transitions between different types of activities. Furthermore, our method is not only able to fill in entire missing frames, but it can also be used to complete gaps where partial poses are available (e.g. from end effectors), or to clean up other forms of noise (e.g. Gaussian). Also, the model can fill in an arbitrary number of gaps that potentially vary in length. In addition, no further post-processing on the model's outputs is necessary such as smoothing or closing discontinuities at the end of the gap. At the heart of our approach lies the idea to cast motion infilling as an inpainting problem and to train a convolutional de-noising autoencoder on image-like representations of motion sequences. At training time, blocks of columns are removed from such images and we ask the model to fill in the gaps. We demonstrate the versatility of the approach via a number of complex motion sequences and report on thorough evaluations performed to better understand the capabilities and limitations of the proposed approach.
Towards End-to-end Video-based Eye-Tracking
Jul 26, 2020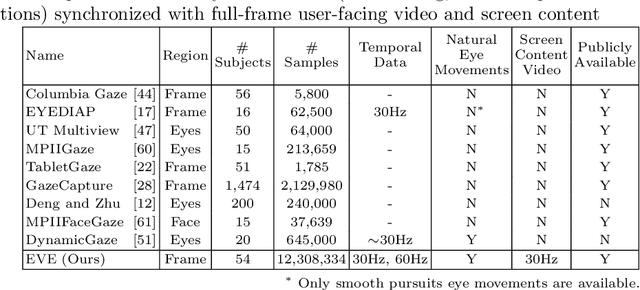

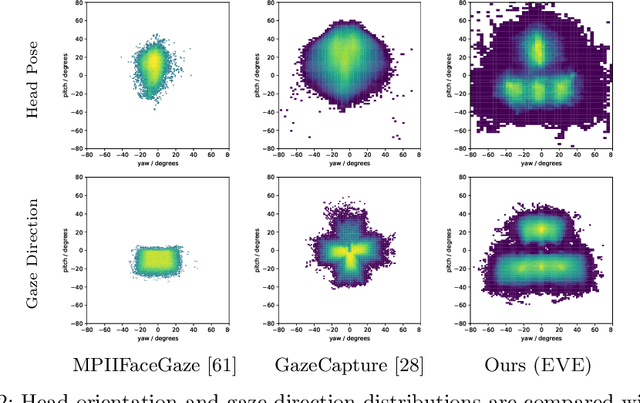
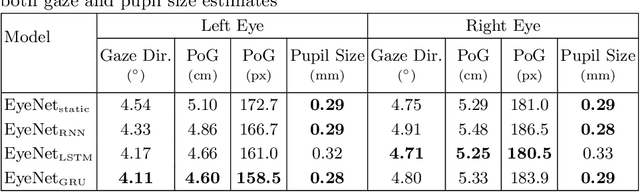
Estimating eye-gaze from images alone is a challenging task, in large parts due to un-observable person-specific factors. Achieving high accuracy typically requires labeled data from test users which may not be attainable in real applications. We observe that there exists a strong relationship between what users are looking at and the appearance of the user's eyes. In response to this understanding, we propose a novel dataset and accompanying method which aims to explicitly learn these semantic and temporal relationships. Our video dataset consists of time-synchronized screen recordings, user-facing camera views, and eye gaze data, which allows for new benchmarks in temporal gaze tracking as well as label-free refinement of gaze. Importantly, we demonstrate that the fusion of information from visual stimuli as well as eye images can lead towards achieving performance similar to literature-reported figures acquired through supervised personalization. Our final method yields significant performance improvements on our proposed EVE dataset, with up to a 28 percent improvement in Point-of-Gaze estimates (resulting in 2.49 degrees in angular error), paving the path towards high-accuracy screen-based eye tracking purely from webcam sensors. The dataset and reference source code are available at https://ait.ethz.ch/projects/2020/EVE
CoSE: Compositional Stroke Embeddings
Jun 17, 2020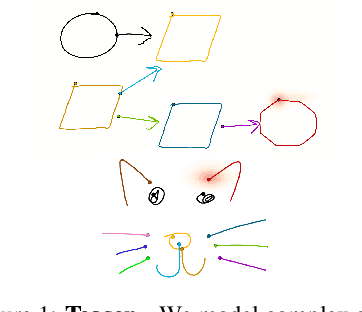
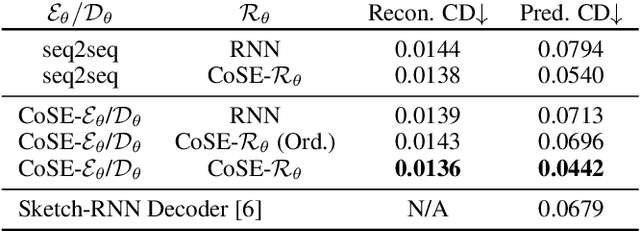
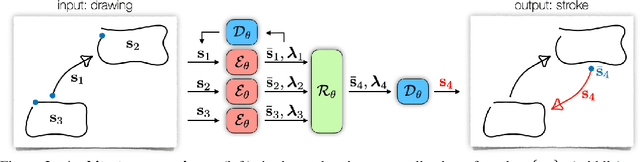
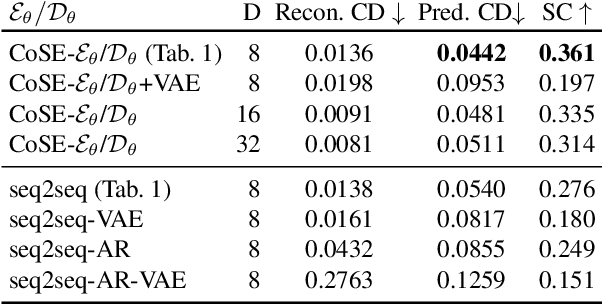
We present a generative model for stroke-based drawing tasks which is able to model complex free-form structures. While previous approaches rely on sequence-based models for drawings of basic objects or handwritten text, we propose a model that treats drawings as a collection of strokes that can be composed into complex structures such as diagrams (e.g., flow-charts). At the core of the approach lies a novel auto-encoder that projects variable-length strokes into a latent space of fixed dimension. This representation space allows a relational model, operating in latent space, to better capture the relationship between strokes and to predict subsequent strokes. We demonstrate qualitatively and quantitatively that our proposed approach is able to model the appearance of individual strokes, as well as the compositional structure of larger diagram drawings. Our approach is suitable for interactive use cases such as auto-completing diagrams.
Attention, please: A Spatio-temporal Transformer for 3D Human Motion Prediction
Apr 18, 2020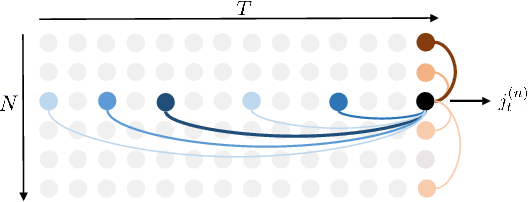
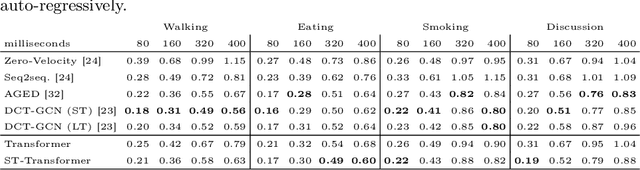
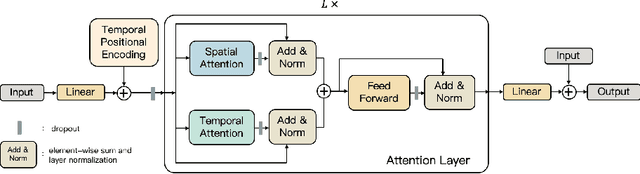

In this paper, we propose a novel architecture for the task of 3D human motion modelling. We argue that the problem can be interpreted as a generative modelling task: A network learns the conditional synthesis of human poses where the model is conditioned on a seed sequence. Our focus lies on the generation of plausible future developments over longer time horizons, whereas previous work considered shorter time frames of up to 1 second. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional joint embeddings followed by a decoupled temporal and spatial self-attention mechanism. The two attention blocks operate in parallel to aggregate the most informative components of the sequence to update the joint representation. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons as well as accurate short-term predictions. Accompanying video available at https://youtu.be/yF0cdt2yCNE .