 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention, please: A Spatio-temporal Transformer for 3D Human Motion Prediction
Paper and Code
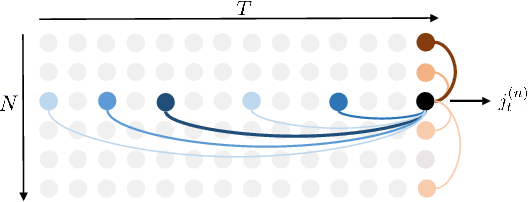
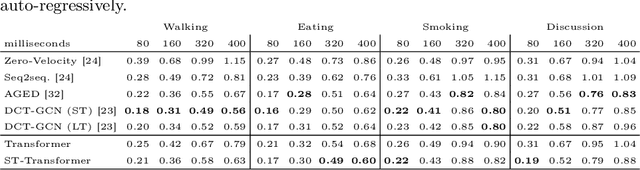
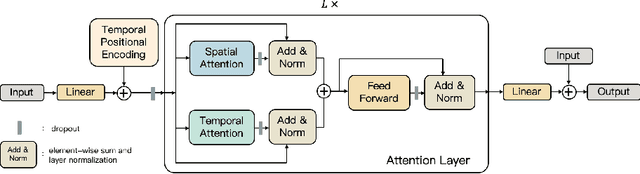

In this paper, we propose a novel architecture for the task of 3D human motion modelling. We argue that the problem can be interpreted as a generative modelling task: A network learns the conditional synthesis of human poses where the model is conditioned on a seed sequence. Our focus lies on the generation of plausible future developments over longer time horizons, whereas previous work considered shorter time frames of up to 1 second. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional joint embeddings followed by a decoupled temporal and spatial self-attention mechanism. The two attention blocks operate in parallel to aggregate the most informative components of the sequence to update the joint representation. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons as well as accurate short-term predictions. Accompanying video available at https://youtu.be/yF0cdt2yCNE .