 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
Unifying Dynamic Tool Creation and Cross-Task Experience Sharing through Cognitive Memory Architecture
Dec 12, 2025Large Language Model agents face fundamental challenges in adapting to novel tasks due to limitations in tool availability and experience reuse. Existing approaches either rely on predefined tools with limited coverage or build tools from scratch without leveraging past experiences, leading to inefficient exploration and suboptimal performance. We introduce SMITH (Shared Memory Integrated Tool Hub), a unified cognitive architecture that seamlessly integrates dynamic tool creation with cross-task experience sharing through hierarchical memory organization. SMITH organizes agent memory into procedural, semantic, and episodic components, enabling systematic capability expansion while preserving successful execution patterns. Our approach formalizes tool creation as iterative code generation within controlled sandbox environments and experience sharing through episodic memory retrieval with semantic similarity matching. We further propose a curriculum learning strategy based on agent-ensemble difficulty re-estimation. Extensive experiments on the GAIA benchmark demonstrate SMITH's effectiveness, achieving 81.8% Pass@1 accuracy and outperforming state-of-the-art baselines including Alita (75.2%) and Memento (70.9%). Our work establishes a foundation for building truly adaptive agents that continuously evolve their capabilities through principled integration of tool creation and experience accumulation.
JoyAgent-JDGenie: Technical Report on the GAIA
Oct 01, 2025Large Language Models are increasingly deployed as autonomous agents for complex real-world tasks, yet existing systems often focus on isolated improvements without a unifying design for robustness and adaptability. We propose a generalist agent architecture that integrates three core components: a collective multi-agent framework combining planning and execution agents with critic model voting, a hierarchical memory system spanning working, semantic, and procedural layers, and a refined tool suite for search, code execution, and multimodal parsing. Evaluated on a comprehensive benchmark, our framework consistently outperforms open-source baselines and approaches the performance of proprietary systems. These results demonstrate the importance of system-level integration and highlight a path toward scalable, resilient, and adaptive AI assistants capable of operating across diverse domains and tasks.
SynMatch: Rethinking Consistency in Medical Image Segmentation with Sparse Annotations
Aug 10, 2025Label scarcity remains a major challenge in deep learning-based medical image segmentation. Recent studies use strong-weak pseudo supervision to leverage unlabeled data. However, performance is often hindered by inconsistencies between pseudo labels and their corresponding unlabeled images. In this work, we propose \textbf{SynMatch}, a novel framework that sidesteps the need for improving pseudo labels by synthesizing images to match them instead. Specifically, SynMatch synthesizes images using texture and shape features extracted from the same segmentation model that generates the corresponding pseudo labels for unlabeled images. This design enables the generation of highly consistent synthesized-image-pseudo-label pairs without requiring any training parameters for image synthesis. We extensively evaluate SynMatch across diverse medical image segmentation tasks under semi-supervised learning (SSL), weakly-supervised learning (WSL), and barely-supervised learning (BSL) settings with increasingly limited annotations. The results demonstrate that SynMatch achieves superior performance, especially in the most challenging BSL setting. For example, it outperforms the recent strong-weak pseudo supervision-based method by 29.71\% and 10.05\% on the polyp segmentation task with 5\% and 10\% scribble annotations, respectively. The code will be released at https://github.com/Senyh/SynMatch.
ConStyX: Content Style Augmentation for Generalizable Medical Image Segmentation
Jun 12, 2025Medical images are usually collected from multiple domains, leading to domain shifts that impair the performance of medical image segmentation models. Domain Generalization (DG) aims to address this issue by training a robust model with strong generalizability. Recently, numerous domain randomization-based DG methods have been proposed. However, these methods suffer from the following limitations: 1) constrained efficiency of domain randomization due to their exclusive dependence on image style perturbation, and 2) neglect of the adverse effects of over-augmented images on model training. To address these issues, we propose a novel domain randomization-based DG method, called content style augmentation (ConStyX), for generalizable medical image segmentation. Specifically, ConStyX 1) augments the content and style of training data, allowing the augmented training data to better cover a wider range of data domains, and 2) leverages well-augmented features while mitigating the negative effects of over-augmented features during model training. Extensive experiments across multiple domains demonstrate that our ConStyX achieves superior generalization performance. The code is available at https://github.com/jwxsp1/ConStyX.
Tianyi: A Traditional Chinese Medicine all-rounder language model and its Real-World Clinical Practice
May 19, 2025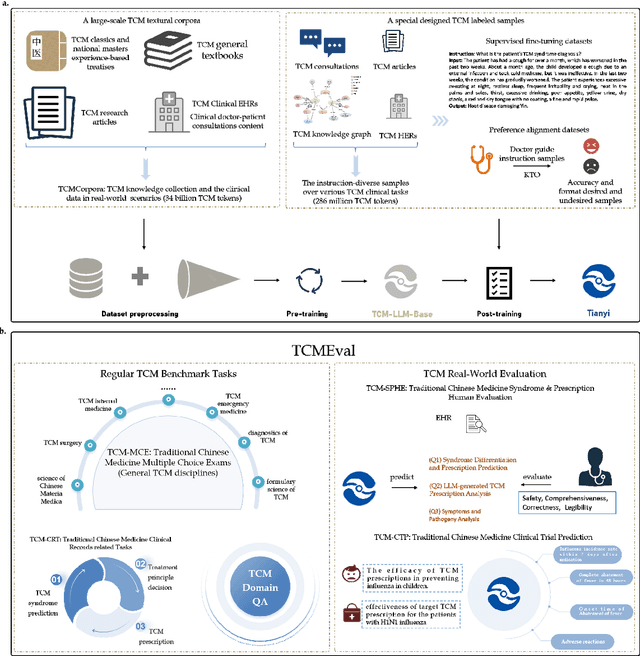
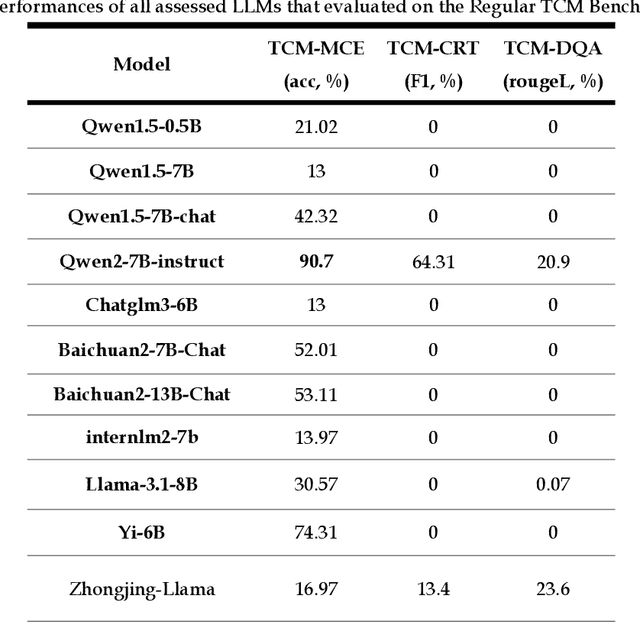

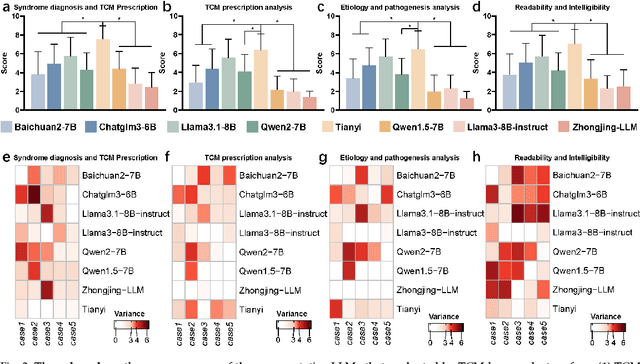
Natural medicines, particularly Traditional Chinese Medicine (TCM), are gaining global recognition for their therapeutic potential in addressing human symptoms and diseases. TCM, with its systematic theories and extensive practical experience, provides abundant resources for healthcare. However, the effective application of TCM requires precise syndrome diagnosis, determination of treatment principles, and prescription formulation, which demand decades of clinical expertise. Despite advancements in TCM-based decision systems, machine learning, and deep learning research, limitations in data and single-objective constraints hinder their practical application. In recent years, large language models (LLMs) have demonstrated potential in complex tasks, but lack specialization in TCM and face significant challenges, such as too big model scale to deploy and issues with hallucination. To address these challenges, we introduce Tianyi with 7.6-billion-parameter LLM, a model scale proper and specifically designed for TCM, pre-trained and fine-tuned on diverse TCM corpora, including classical texts, expert treatises, clinical records, and knowledge graphs. Tianyi is designed to assimilate interconnected and systematic TCM knowledge through a progressive learning manner. Additionally, we establish TCMEval, a comprehensive evaluation benchmark, to assess LLMs in TCM examinations, clinical tasks, domain-specific question-answering, and real-world trials. The extensive evaluations demonstrate the significant potential of Tianyi as an AI assistant in TCM clinical practice and research, bridging the gap between TCM knowledge and practical application.
Cell Library Characterization for Composite Current Source Models Based on Gaussian Process Regression and Active Learning
May 16, 2025The composite current source (CCS) model has been adopted as an advanced timing model that represents the current behavior of cells for improved accuracy and better capability than traditional non-linear delay models (NLDM) to model complex dynamic effects and interactions under advanced process nodes. However, the high accuracy requirement, large amount of data and extensive simulation cost pose severe challenges to CCS characterization. To address these challenges, we introduce a novel Gaussian Process Regression(GPR) model with active learning(AL) to establish the characterization framework efficiently and accurately. Our approach significantly outperforms conventional commercial tools as well as learning based approaches by achieving an average absolute error of 2.05 ps and a relative error of 2.27% for current waveform of 57 cells under 9 process, voltage, temperature (PVT) corners with TSMC 22nm process. Additionally, our model drastically reduces the runtime to 27% and the storage by up to 19.5x compared with that required by commercial tools.
Style Content Decomposition-based Data Augmentation for Domain Generalizable Medical Image Segmentation
Feb 28, 2025Due to the domain shifts between training and testing medical images, learned segmentation models often experience significant performance degradation during deployment. In this paper, we first decompose an image into its style code and content map and reveal that domain shifts in medical images involve: \textbf{style shifts} (\emph{i.e.}, differences in image appearance) and \textbf{content shifts} (\emph{i.e.}, variations in anatomical structures), the latter of which has been largely overlooked. To this end, we propose \textbf{StyCona}, a \textbf{sty}le \textbf{con}tent decomposition-based data \textbf{a}ugmentation method that innovatively augments both image style and content within the rank-one space, for domain generalizable medical image segmentation. StyCona is a simple yet effective plug-and-play module that substantially improves model generalization without requiring additional training parameters or modifications to the segmentation model architecture. Experiments on cross-sequence, cross-center, and cross-modality medical image segmentation settings with increasingly severe domain shifts, demonstrate the effectiveness of StyCona and its superiority over state-of-the-arts. The code is available at https://github.com/Senyh/StyCona.
Adaptive Mix for Semi-Supervised Medical Image Segmentation
Jul 31, 2024



Mix-up is a key technique for consistency regularization-based semi-supervised learning methods, generating strong-perturbed samples for strong-weak pseudo-supervision. Existing mix-up operations are performed either randomly or with predefined rules, such as replacing low-confidence patches with high-confidence ones. The former lacks control over the perturbation degree, leading to overfitting on randomly perturbed samples, while the latter tends to generate images with trivial perturbations, both of which limit the effectiveness of consistency learning. This paper aims to answer the following question: How can image mix-up perturbation be adaptively performed during training? To this end, we propose an Adaptive Mix algorithm (AdaMix) for image mix-up in a self-paced learning manner. Given that, in general, a model's performance gradually improves during training, AdaMix is equipped with a self-paced curriculum that, in the initial training stage, provides relatively simple perturbed samples and then gradually increases the difficulty of perturbed images by adaptively controlling the perturbation degree based on the model's learning state estimated by a self-paced regularize. We develop three frameworks with our AdaMix, i.e., AdaMix-ST, AdaMix-MT, and AdaMix-CT, for semi-supervised medical image segmentation. Extensive experiments on three public datasets, including both 2D and 3D modalities, show that the proposed frameworks are capable of achieving superior performance. For example, compared with the state-of-the-art, AdaMix-CT achieves relative improvements of 2.62% in Dice and 48.25% in average surface distance on the ACDC dataset with 10% labeled data. The results demonstrate that mix-up operations with dynamically adjusted perturbation strength based on the segmentation model's state can significantly enhance the effectiveness of consistency regularization.
A Novel Perception Entropy Metric for Optimizing Vehicle Perception with LiDAR Deployment
Jul 25, 2024



Developing an effective evaluation metric is crucial for accurately and swiftly measuring LiDAR perception performance. One major issue is the lack of metrics that can simultaneously generate fast and accurate evaluations based on either object detection or point cloud data. In this study, we propose a novel LiDAR perception entropy metric based on the probability of vehicle grid occupancy. This metric reflects the influence of point cloud distribution on vehicle detection performance. Based on this, we also introduce a LiDAR deployment optimization model, which is solved using a differential evolution-based particle swarm optimization algorithm. A comparative experiment demonstrated that the proposed PE-VGOP offers a correlation of more than 0.98 with vehicle detection ground truth in evaluating LiDAR perception performance. Furthermore, compared to the base deployment, field experiments indicate that the proposed optimization model can significantly enhance the perception capabilities of various types of LiDARs, including RS-16, RS-32, and RS-80. Notably, it achieves a 25% increase in detection Recall for the RS-32 LiDAR.