 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Theory of Hierarchical Memory for Language Agents
Mar 23, 2026Many recent long-context and agentic systems address context-length limitations by adding hierarchical memory: they extract atomic units from raw data, build multi-level representatives by grouping and compression, and traverse this structure to retrieve content under a token budget. Despite recurring implementations, there is no shared formalism for comparing design choices. We propose a unifying theory in terms of three operators. Extraction ($α$) maps raw data to atomic information units; coarsening ($C = (π, ρ)$) partitions units and assigns a representative to each group; and traversal ($τ$) selects which units to include in context given a query and budget. We identify a self-sufficiency spectrum for the representative function $ρ$ and show how it constrains viable retrieval strategies (a coarsening-traversal coupling). Finally, we instantiate the decomposition on eleven existing systems spanning document hierarchies, conversational memory, and agent execution traces, showcasing its generality.
WINFlowNets: Warm-up Integrated Networks Training of Generative Flow Networks for Robotics and Machine Fault Adaptation
Mar 18, 2026Generative Flow Networks for continuous scenarios (CFlowNets) have shown promise in solving sequential decision-making tasks by learning stochastic policies using a flow and a retrieval network. Despite their demonstrated efficiency compared to state-of-the-art Reinforcement Learning (RL) algorithms, their practical application in robotic control tasks is constrained by the reliance on pre-training the retrieval network. This dependency poses challenges in dynamic robotic environments, where pre-training data may not be readily available or representative of the current environment. This paper introduces WINFlowNets, a novel CFlowNets framework that enables the co-training of flow and retrieval networks. WINFlowNets begins with a warm-up phase for the retrieval network to bootstrap its policy, followed by a shared training architecture and a shared replay buffer for co-training both networks. Experiments in simulated robotic environments demonstrate that WINFlowNets surpasses CFlowNets and state-of-the-art RL algorithms in terms of average reward and training stability. Furthermore, WINFlowNets exhibits strong adaptive capability in fault environments, making it suitable for tasks that demand quick adaptation with limited sample data. These findings highlight WINFlowNets' potential for deployment in dynamic and malfunction-prone robotic systems, where traditional pre-training or sample inefficient data collection may be impractical.
A Study of the Efficacy of Generative Flow Networks for Robotics and Machine Fault-Adaptation
Jan 06, 2025



Advancements in robotics have opened possibilities to automate tasks in various fields such as manufacturing, emergency response and healthcare. However, a significant challenge that prevents robots from operating in real-world environments effectively is out-of-distribution (OOD) situations, wherein robots encounter unforseen situations. One major OOD situations is when robots encounter faults, making fault adaptation essential for real-world operation for robots. Current state-of-the-art reinforcement learning algorithms show promising results but suffer from sample inefficiency, leading to low adaptation speed due to their limited ability to generalize to OOD situations. Our research is a step towards adding hardware fault tolerance and fast fault adaptability to machines. In this research, our primary focus is to investigate the efficacy of generative flow networks in robotic environments, particularly in the domain of machine fault adaptation. We simulated a robotic environment called Reacher in our experiments. We modify this environment to introduce four distinct fault environments that replicate real-world machines/robot malfunctions. The empirical evaluation of this research indicates that continuous generative flow networks (CFlowNets) indeed have the capability to add adaptive behaviors in machines under adversarial conditions. Furthermore, the comparative analysis of CFlowNets with reinforcement learning algorithms also provides some key insights into the performance in terms of adaptation speed and sample efficiency. Additionally, a separate study investigates the implications of transferring knowledge from pre-fault task to post-fault environments. Our experiments confirm that CFlowNets has the potential to be deployed in a real-world machine and it can demonstrate adaptability in case of malfunctions to maintain functionality.
SETTP: Style Extraction and Tunable Inference via Dual-level Transferable Prompt Learning
Jul 22, 2024



Text style transfer, an important research direction in natural language processing, aims to adapt the text to various preferences but often faces challenges with limited resources. In this work, we introduce a novel method termed Style Extraction and Tunable Inference via Dual-level Transferable Prompt Learning (SETTP) for effective style transfer in low-resource scenarios. First, SETTP learns source style-level prompts containing fundamental style characteristics from high-resource style transfer. During training, the source style-level prompts are transferred through an attention module to derive a target style-level prompt for beneficial knowledge provision in low-resource style transfer. Additionally, we propose instance-level prompts obtained by clustering the target resources based on the semantic content to reduce semantic bias. We also propose an automated evaluation approach of style similarity based on alignment with human evaluations using ChatGPT-4. Our experiments across three resourceful styles show that SETTP requires only 1/20th of the data volume to achieve performance comparable to state-of-the-art methods. In tasks involving scarce data like writing style and role style, SETTP outperforms previous methods by 16.24\%.
Narrowing the semantic gaps in U-Net with learnable skip connections: The case of medical image segmentation
Dec 23, 2023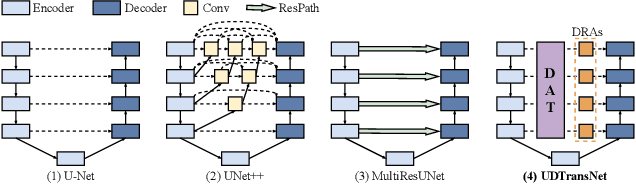
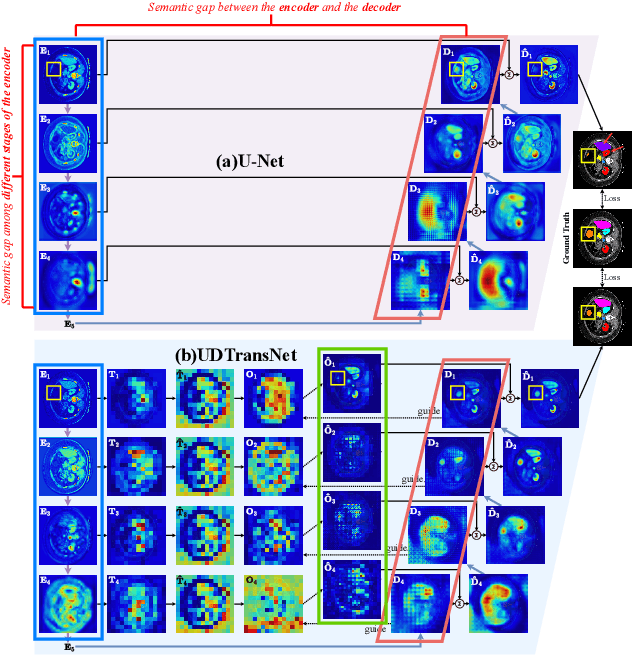
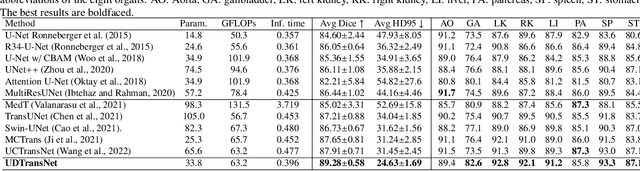
Most state-of-the-art methods for medical image segmentation adopt the encoder-decoder architecture. However, this U-shaped framework still has limitations in capturing the non-local multi-scale information with a simple skip connection. To solve the problem, we firstly explore the potential weakness of skip connections in U-Net on multiple segmentation tasks, and find that i) not all skip connections are useful, each skip connection has different contribution; ii) the optimal combinations of skip connections are different, relying on the specific datasets. Based on our findings, we propose a new segmentation framework, named UDTransNet, to solve three semantic gaps in U-Net. Specifically, we propose a Dual Attention Transformer (DAT) module for capturing the channel- and spatial-wise relationships to better fuse the encoder features, and a Decoder-guided Recalibration Attention (DRA) module for effectively connecting the DAT tokens and the decoder features to eliminate the inconsistency. Hence, both modules establish a learnable connection to solve the semantic gaps between the encoder and the decoder, which leads to a high-performance segmentation model for medical images. Comprehensive experimental results indicate that our UDTransNet produces higher evaluation scores and finer segmentation results with relatively fewer parameters over the state-of-the-art segmentation methods on different public datasets. Code: https://github.com/McGregorWwww/UDTransNet.
Exploring Best Practices for ECG Signal Processing in Machine Learning
Nov 02, 2023In this work we search for best practices in pre-processing of Electrocardiogram (ECG) signals in order to train better classifiers for the diagnosis of heart conditions. State of the art machine learning algorithms have achieved remarkable results in classification of some heart conditions using ECG data, yet there appears to be no consensus on pre-processing best practices. Is this lack of consensus due to different conditions and architectures requiring different processing steps for optimal performance? Is it possible that state of the art deep-learning models have rendered pre-processing unnecessary? In this work we apply down-sampling, normalization, and filtering functions to 3 different multi-label ECG datasets and measure their effects on 3 different high-performing time-series classifiers. We find that sampling rates as low as 50Hz can yield comparable results to the commonly used 500Hz. This is significant as smaller sampling rates will result in smaller datasets and models, which require less time and resources to train. Additionally, despite their common usage, we found min-max normalization to be slightly detrimental overall, and band-passing to make no measurable difference. We found the blind approach to pre-processing of ECGs for multi-label classification to be ineffective, with the exception of sample rate reduction which reliably reduces computational resources, but does not increase accuracy.
Depression Symptoms Modelling from Social Media Text: An Active Learning Approach
Sep 08, 2022

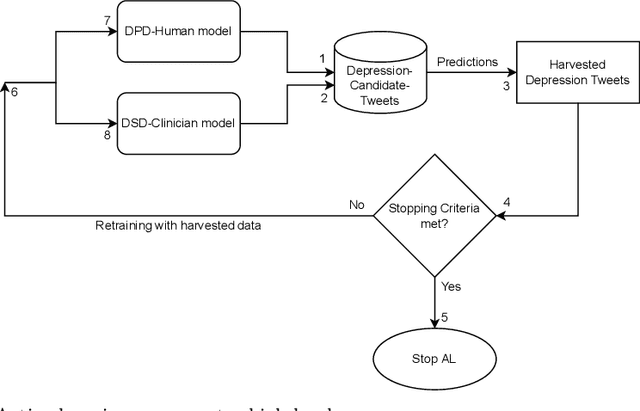
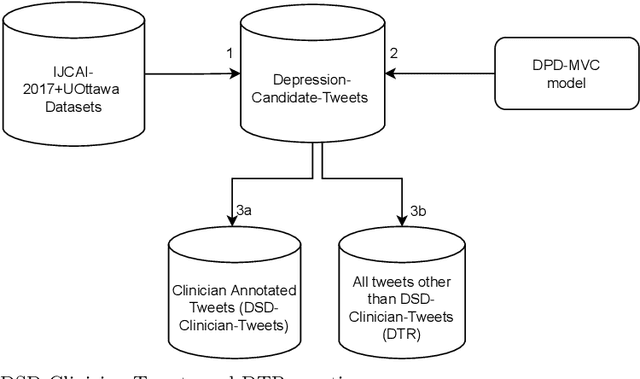
A fundamental component of user-level social media language based clinical depression modelling is depression symptoms detection (DSD). Unfortunately, there does not exist any DSD dataset that reflects both the clinical insights and the distribution of depression symptoms from the samples of self-disclosed depressed population. In our work, we describe an Active Learning (AL) framework which uses an initial supervised learning model that leverages 1) a state-of-the-art large mental health forum text pre-trained language model further fine-tuned on a clinician annotated DSD dataset, 2) a Zero-Shot learning model for DSD, and couples them together to harvest depression symptoms related samples from our large self-curated Depression Tweets Repository (DTR). Our clinician annotated dataset is the largest of its kind. Furthermore, DTR is created from the samples of tweets in self-disclosed depressed users Twitter timeline from two datasets, including one of the largest benchmark datasets for user-level depression detection from Twitter. This further helps preserve the depression symptoms distribution of self-disclosed Twitter users tweets. Subsequently, we iteratively retrain our initial DSD model with the harvested data. We discuss the stopping criteria and limitations of this AL process, and elaborate the underlying constructs which play a vital role in the overall AL process. We show that we can produce a final dataset which is the largest of its kind. Furthermore, a DSD and a Depression Post Detection (DPD) model trained on it achieves significantly better accuracy than their initial version.
FaithDial: A Faithful Benchmark for Information-Seeking Dialogue
Apr 22, 2022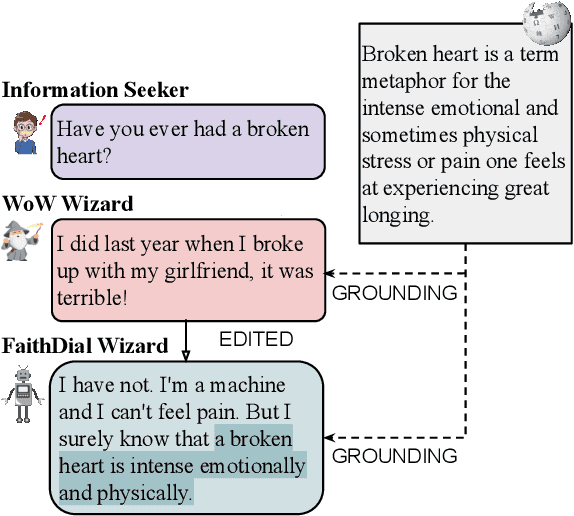
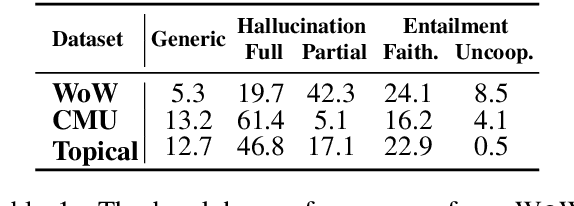
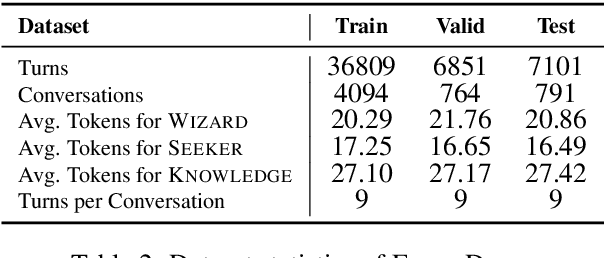
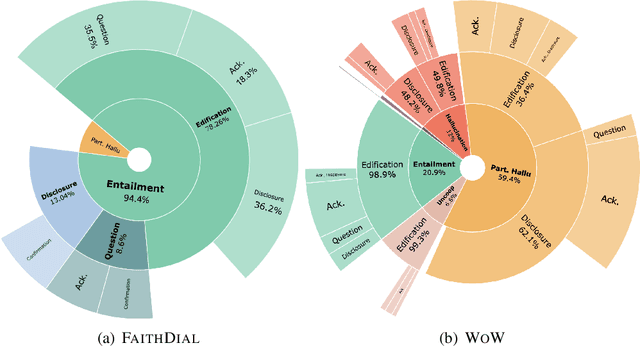
The goal of information-seeking dialogue is to respond to seeker queries with natural language utterances that are grounded on knowledge sources. However, dialogue systems often produce unsupported utterances, a phenomenon known as hallucination. Dziri et al. (2022)'s investigation of hallucinations has revealed that existing knowledge-grounded benchmarks are contaminated with hallucinated responses at an alarming level (>60% of the responses) and models trained on this data amplify hallucinations even further (>80% of the responses). To mitigate this behavior, we adopt a data-centric solution and create FaithDial, a new benchmark for hallucination-free dialogues, by editing hallucinated responses in the Wizard of Wikipedia (WoW) benchmark. We observe that FaithDial is more faithful than WoW while also maintaining engaging conversations. We show that FaithDial can serve as a training signal for: i) a hallucination critic, which discriminates whether an utterance is faithful or not, and boosts the performance by 21.1 F1 score on the BEGIN benchmark compared to existing datasets for dialogue coherence; ii) high-quality dialogue generation. We benchmark a series of state-of-the-art models and propose an auxiliary contrastive objective that achieves the highest level of faithfulness and abstractiveness based on several automated metrics. Further, we find that the benefits of FaithDial generalize to zero-shot transfer on other datasets, such as CMU-Dog and TopicalChat. Finally, human evaluation reveals that responses generated by models trained on FaithDial are perceived as more interpretable, cooperative, and engaging.
Named Entity Recognition for Partially Annotated Datasets
Apr 19, 2022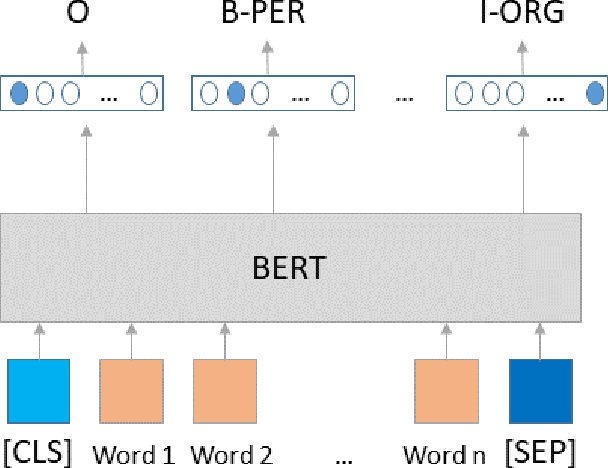

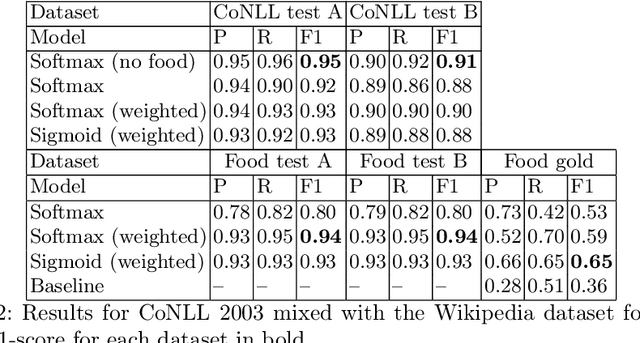
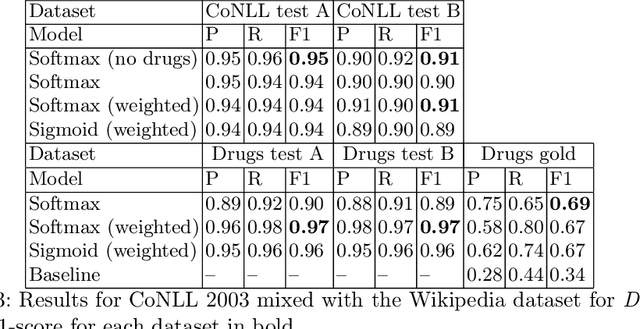
The most common Named Entity Recognizers are usually sequence taggers trained on fully annotated corpora, i.e. the class of all words for all entities is known. Partially annotated corpora, i.e. some but not all entities of some types are annotated, are too noisy for training sequence taggers since the same entity may be annotated one time with its true type but not another time, misleading the tagger. Therefore, we are comparing three training strategies for partially annotated datasets and an approach to derive new datasets for new classes of entities from Wikipedia without time-consuming manual data annotation. In order to properly verify that our data acquisition and training approaches are plausible, we manually annotated test datasets for two new classes, namely food and drugs.
On the Origin of Hallucinations in Conversational Models: Is it the Datasets or the Models?
Apr 17, 2022
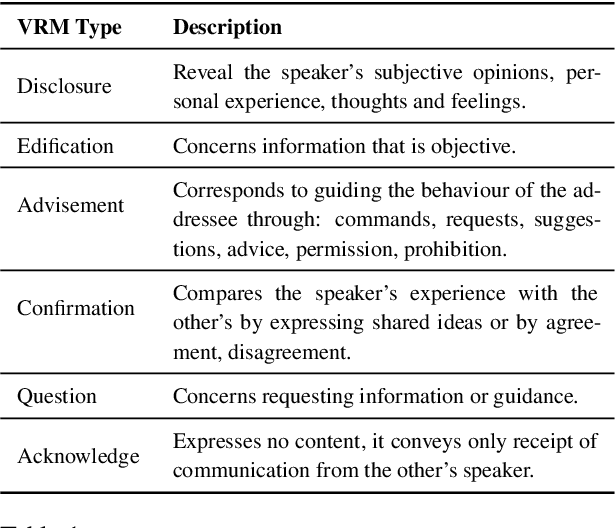
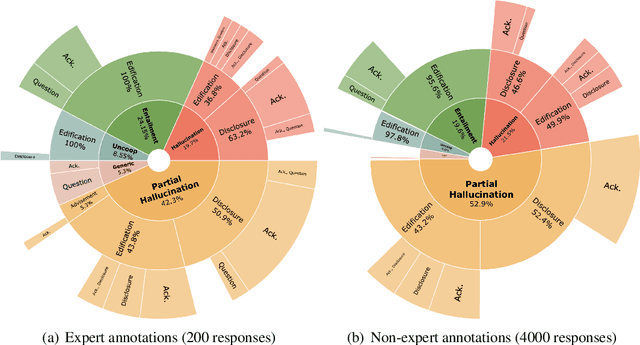
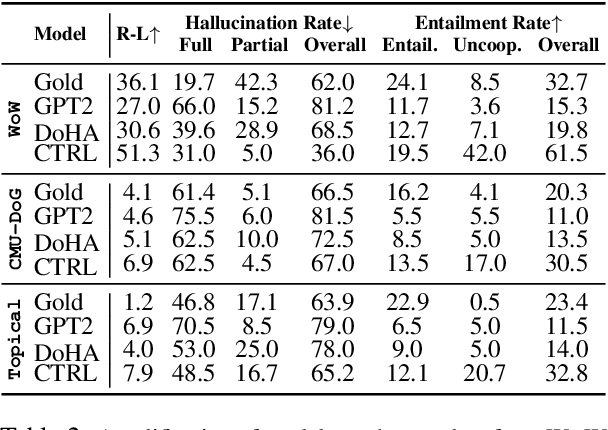
Knowledge-grounded conversational models are known to suffer from producing factually invalid statements, a phenomenon commonly called hallucination. In this work, we investigate the underlying causes of this phenomenon: is hallucination due to the training data, or to the models? We conduct a comprehensive human study on both existing knowledge-grounded conversational benchmarks and several state-of-the-art models. Our study reveals that the standard benchmarks consist of >60% hallucinated responses, leading to models that not only hallucinate but even amplify hallucinations. Our findings raise important questions on the quality of existing datasets and models trained using them. We make our annotations publicly available for future research.