 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinGrAct: A Framework for FINe-GRrained Evaluation of ACTionability in Explainable Automatic Fact-Checking
Apr 07, 2025The field of explainable Automatic Fact-Checking (AFC) aims to enhance the transparency and trustworthiness of automated fact-verification systems by providing clear and comprehensible explanations. However, the effectiveness of these explanations depends on their actionability --their ability to empower users to make informed decisions and mitigate misinformation. Despite actionability being a critical property of high-quality explanations, no prior research has proposed a dedicated method to evaluate it. This paper introduces FinGrAct, a fine-grained evaluation framework that can access the web, and it is designed to assess actionability in AFC explanations through well-defined criteria and an evaluation dataset. FinGrAct surpasses state-of-the-art (SOTA) evaluators, achieving the highest Pearson and Kendall correlation with human judgments while demonstrating the lowest ego-centric bias, making it a more robust evaluation approach for actionability evaluation in AFC.
Can Large Language Models Address Open-Target Stance Detection?
Aug 30, 2024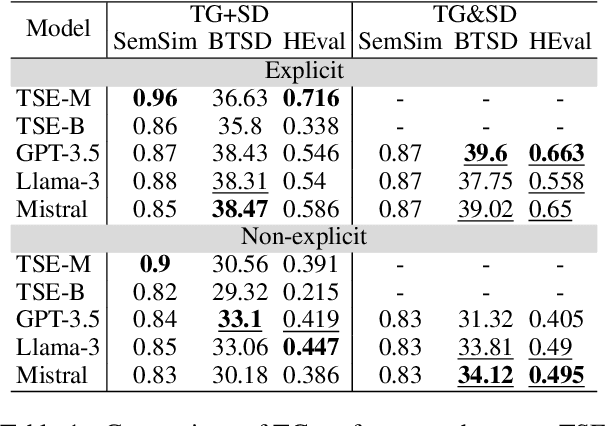
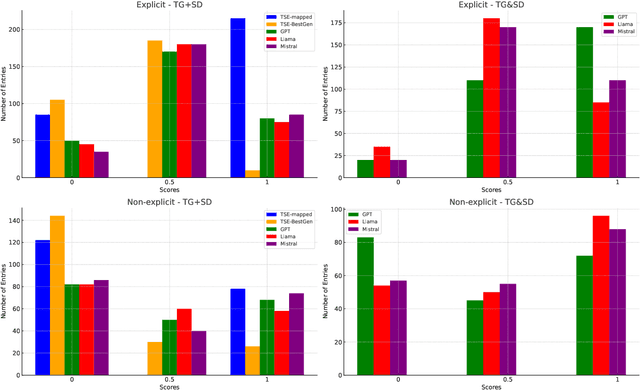
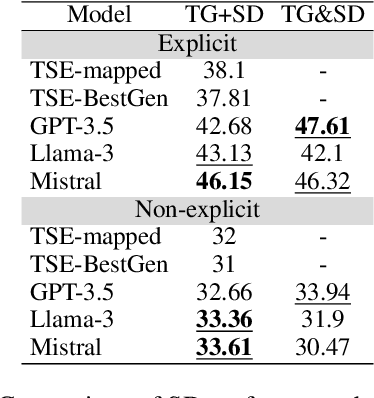
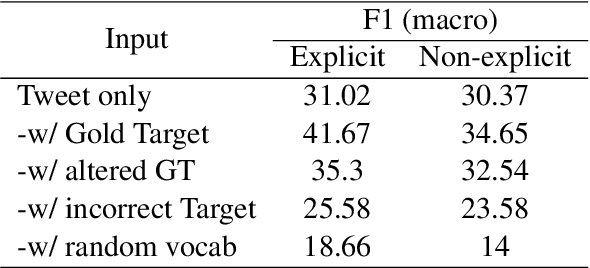
Stance detection (SD) assesses a text's position towards a target, typically labeled as "favor," "against," or "neutral." We introduce Open-Target Stance Detection (OTSD), where targets are neither seen during training nor provided as input. Evaluating Large Language Models (LLMs) like GPT-3.5, Llama 3, and Mistral, we compare their performance with the Target-Stance Extraction (TSE) approach, which has the advantage of using predefined targets. LLMs perform better than TSE in target generation when the real target is explicitly and not explicitly mentioned in the text. For stance detection, LLMs perform better in explicit scenarios but fail in non-explicit ones.
Enhancing Argument Summarization: Prioritizing Exhaustiveness in Key Point Generation and Introducing an Automatic Coverage Evaluation Metric
Apr 17, 2024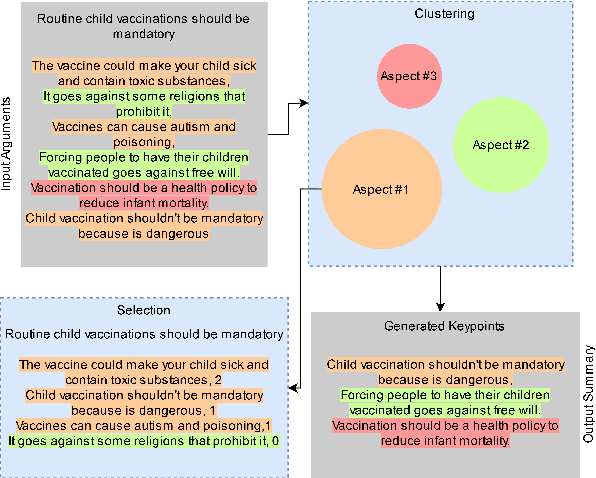
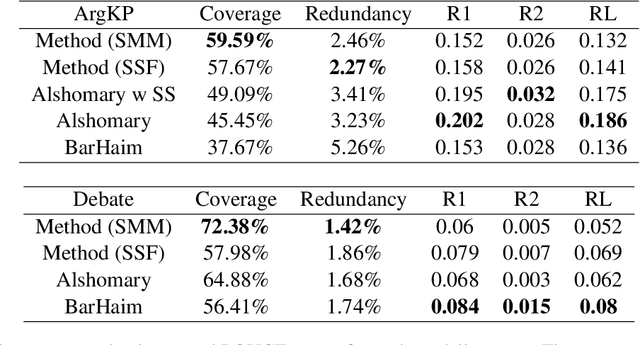
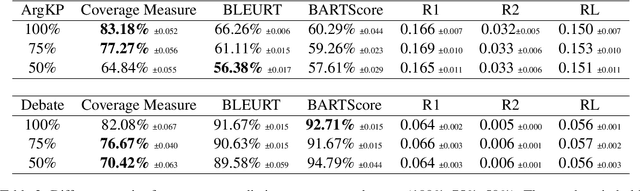

The proliferation of social media platforms has given rise to the amount of online debates and arguments. Consequently, the need for automatic summarization methods for such debates is imperative, however this area of summarization is rather understudied. The Key Point Analysis (KPA) task formulates argument summarization as representing the summary of a large collection of arguments in the form of concise sentences in bullet-style format, called key points. A sub-task of KPA, called Key Point Generation (KPG), focuses on generating these key points given the arguments. This paper introduces a novel extractive approach for key point generation, that outperforms previous state-of-the-art methods for the task. Our method utilizes an extractive clustering based approach that offers concise, high quality generated key points with higher coverage of reference summaries, and less redundant outputs. In addition, we show that the existing evaluation metrics for summarization such as ROUGE are incapable of differentiating between generated key points of different qualities. To this end, we propose a new evaluation metric for assessing the generated key points by their coverage. Our code can be accessed online.
Recent Trends in Unsupervised Summarization
May 18, 2023Unsupervised summarization is a powerful technique that enables training summarizing models without requiring labeled datasets. This survey covers different recent techniques and models used for unsupervised summarization. We cover extractive, abstractive, and hybrid models and strategies used to achieve unsupervised summarization. While the main focus of this survey is on recent research, we also cover some of the important previous research. We additionally introduce a taxonomy, classifying different research based on their approach to unsupervised training. Finally, we discuss the current approaches and mention some datasets and evaluation methods.
Named Entity Recognition for Partially Annotated Datasets
Apr 19, 2022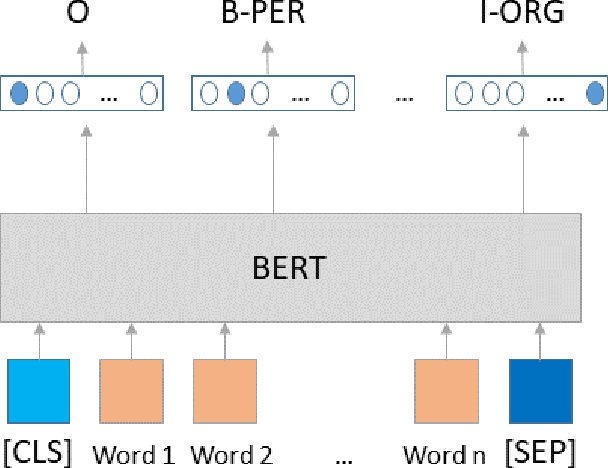

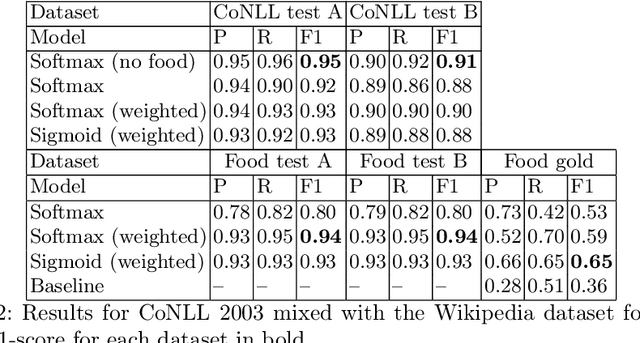
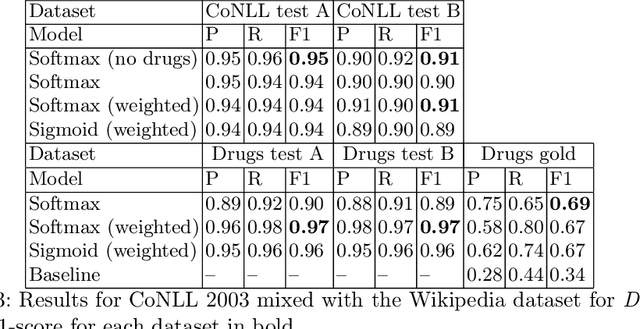
The most common Named Entity Recognizers are usually sequence taggers trained on fully annotated corpora, i.e. the class of all words for all entities is known. Partially annotated corpora, i.e. some but not all entities of some types are annotated, are too noisy for training sequence taggers since the same entity may be annotated one time with its true type but not another time, misleading the tagger. Therefore, we are comparing three training strategies for partially annotated datasets and an approach to derive new datasets for new classes of entities from Wikipedia without time-consuming manual data annotation. In order to properly verify that our data acquisition and training approaches are plausible, we manually annotated test datasets for two new classes, namely food and drugs.
FREDA: Flexible Relation Extraction Data Annotation
Apr 14, 2022
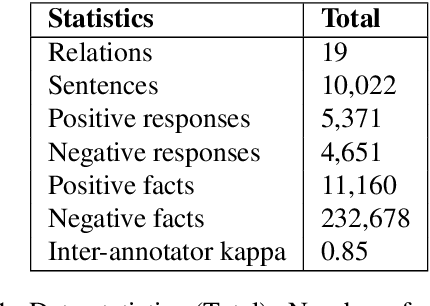
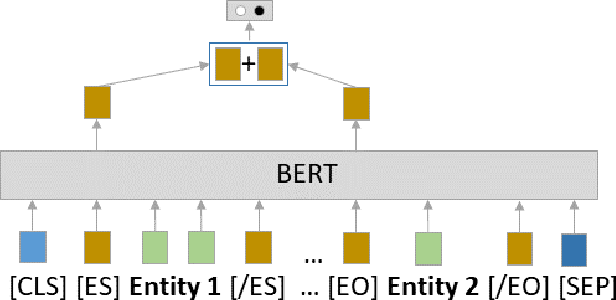
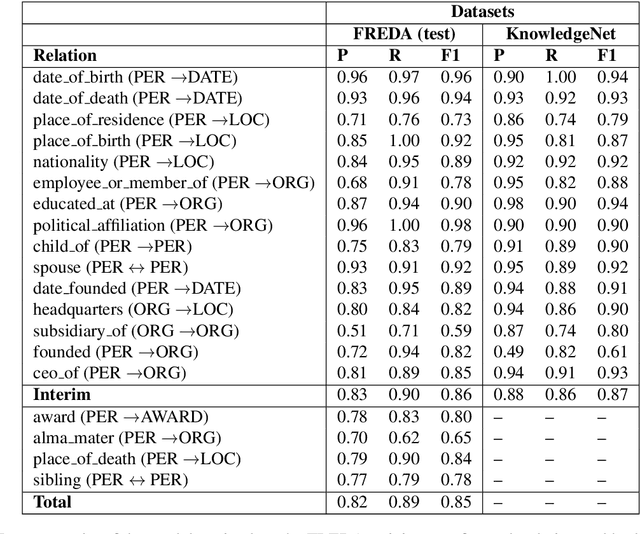
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.
ANA at SemEval-2020 Task 4: mUlti-task learNIng for cOmmonsense reasoNing
Jun 29, 2020In this paper, we describe our mUlti-task learNIng for cOmmonsense reasoNing (UNION) system submitted for Task C of the SemEval2020 Task 4, which is to generate a reason explaining why a given false statement is non-sensical. However, we found in the early experiments that simple adaptations such as fine-tuning GPT2 often yield dull and non-informative generations (e.g. simple negations). In order to generate more meaningful explanations, we propose UNION, a unified end-to-end framework, to utilize several existing commonsense datasets so that it allows a model to learn more dynamics under the scope of commonsense reasoning. In order to perform model selection efficiently, accurately and promptly, we also propose a couple of auxiliary automatic evaluation metrics so that we can extensively compare the models from different perspectives. Our submitted system not only results in a good performance in the proposed metrics but also outperforms its competitors with the highest achieved score of 2.10 for human evaluation while remaining a BLEU score of 15.7. Our code is made publicly available at GitHub.
Seq2Emo for Multi-label Emotion Classification Based on Latent Variable Chains Transformation
Nov 08, 2019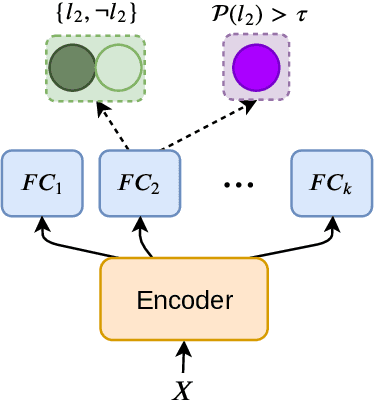


Emotion detection in text is an important task in NLP and is essential in many applications. Most of the existing methods treat this task as a problem of single-label multi-class text classification. To predict multiple emotions for one instance, most of the existing works regard it as a general Multi-label Classification (MLC) problem, where they usually either apply a manually determined threshold on the last output layer of their neural network models or train multiple binary classifiers and make predictions in the fashion of one-vs-all. However, compared to labels in the general MLC datasets, the number of emotion categories are much fewer (less than 10). Additionally, emotions tend to have more correlations with each other. For example, the human usually does not express "joy" and "anger" at the same time, but it is very likely to have "joy" and "love" expressed together. Given this intuition, in this paper, we propose a Latent Variable Chain (LVC) transformation and a tailored model -- Seq2Emo model that not only naturally predicts multiple emotion labels but also takes into consideration their correlations. We perform the experiments on the existing multi-label emotion datasets as well as on our newly collected datasets. The results show that our model compares favorably with existing state-of-the-art methods.
Self-Attentional Models Application in Task-Oriented Dialogue Generation Systems
Sep 11, 2019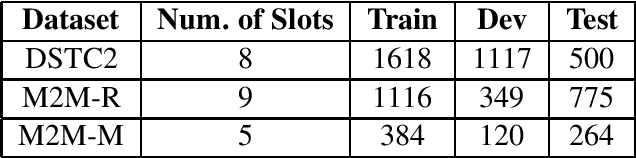

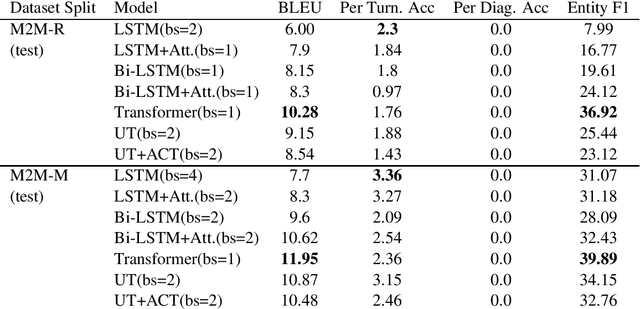
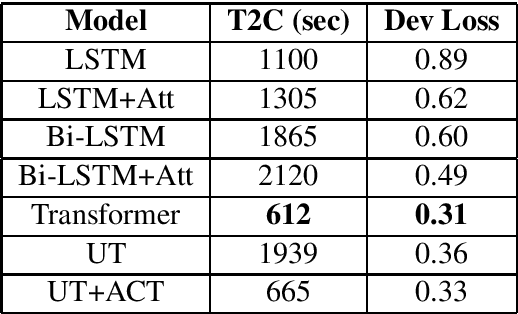
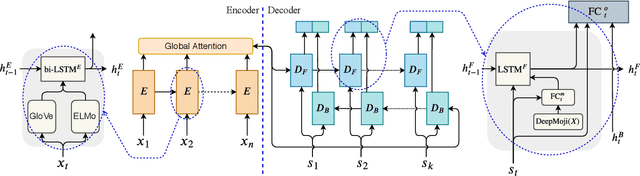
Self-attentional models are a new paradigm for sequence modelling tasks which differ from common sequence modelling methods, such as recurrence-based and convolution-based sequence learning, in the way that their architecture is only based on the attention mechanism. Self-attentional models have been used in the creation of the state-of-the-art models in many NLP tasks such as neural machine translation, but their usage has not been explored for the task of training end-to-end task-oriented dialogue generation systems yet. In this study, we apply these models on the three different datasets for training task-oriented chatbots. Our finding shows that self-attentional models can be exploited to create end-to-end task-oriented chatbots which not only achieve higher evaluation scores compared to recurrence-based models, but also do so more efficiently.
Contrastive Reasons Detection and Clustering from Online Polarized Debate
Aug 01, 2019
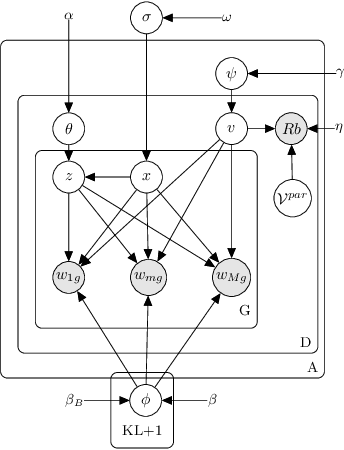
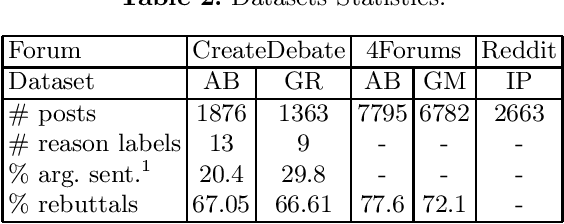
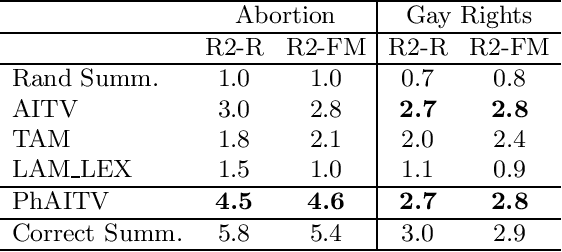
This work tackles the problem of unsupervised modeling and extraction of the main contrastive sentential reasons conveyed by divergent viewpoints on polarized issues. It proposes a pipeline approach centered around the detection and clustering of phrases, assimilated to argument facets using a novel Phrase Author Interaction Topic-Viewpoint model. The evaluation is based on the informativeness, the relevance and the clustering accuracy of extracted reasons. The pipeline approach shows a significant improvement over state-of-the-art methods in contrastive summarization on online debate datasets.