 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition for Partially Annotated Datasets
Apr 19, 2022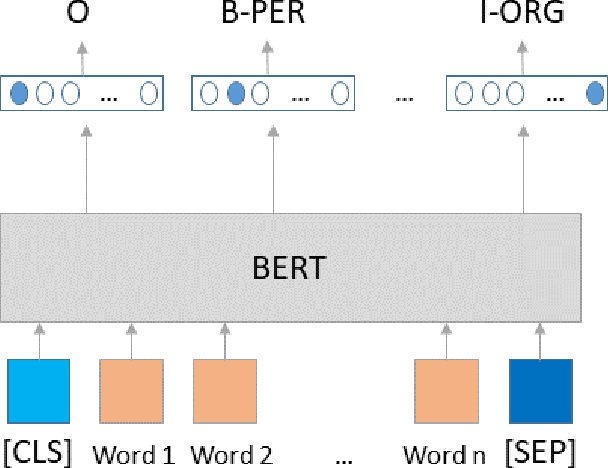

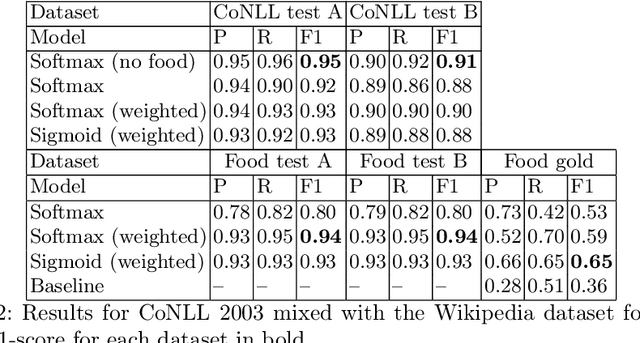
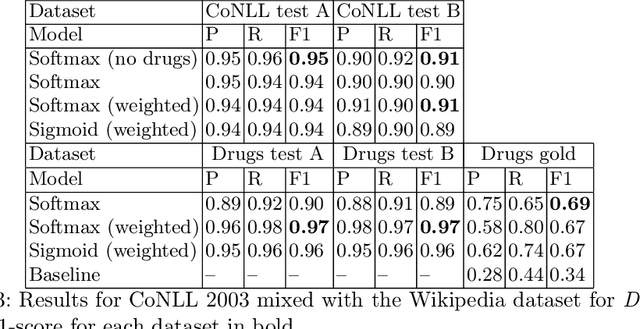
The most common Named Entity Recognizers are usually sequence taggers trained on fully annotated corpora, i.e. the class of all words for all entities is known. Partially annotated corpora, i.e. some but not all entities of some types are annotated, are too noisy for training sequence taggers since the same entity may be annotated one time with its true type but not another time, misleading the tagger. Therefore, we are comparing three training strategies for partially annotated datasets and an approach to derive new datasets for new classes of entities from Wikipedia without time-consuming manual data annotation. In order to properly verify that our data acquisition and training approaches are plausible, we manually annotated test datasets for two new classes, namely food and drugs.
FREDA: Flexible Relation Extraction Data Annotation
Apr 14, 2022
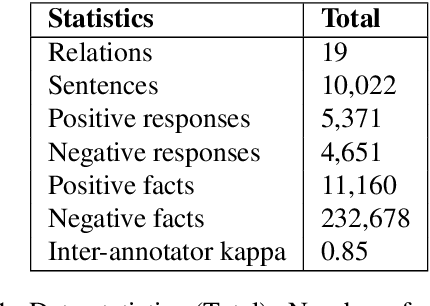
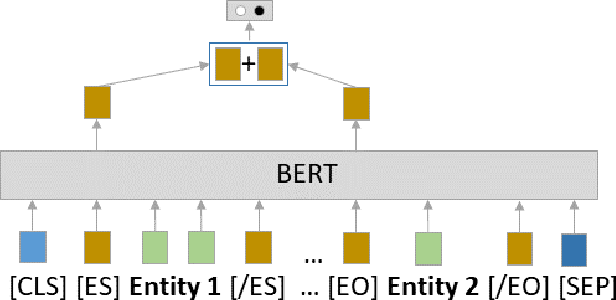
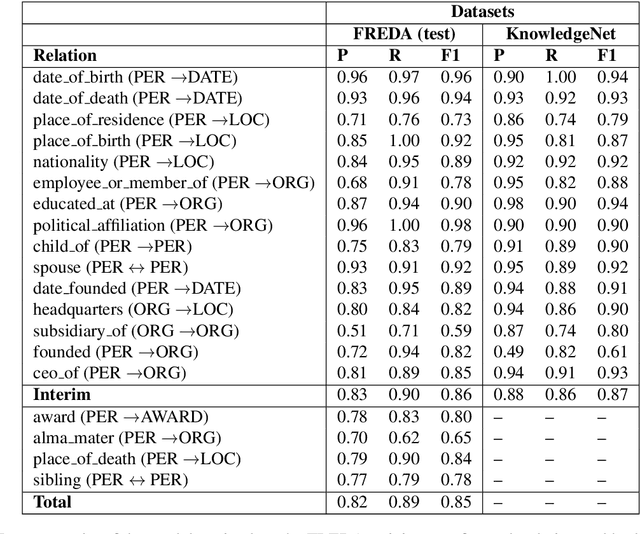
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.