 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Visual Stimulus Images from EEG Signals Based on Deep Visual Representation Model
Mar 11, 2024Reconstructing visual stimulus images is a significant task in neural decoding, and up to now, most studies consider the functional magnetic resonance imaging (fMRI) as the signal source. However, the fMRI-based image reconstruction methods are difficult to widely applied because of the complexity and high cost of the acquisition equipments. Considering the advantages of low cost and easy portability of the electroencephalogram (EEG) acquisition equipments, we propose a novel image reconstruction method based on EEG signals in this paper. Firstly, to satisfy the high recognizability of visual stimulus images in fast switching manner, we build a visual stimuli image dataset, and obtain the EEG dataset by a corresponding EEG signals collection experiment. Secondly, the deep visual representation model(DVRM) consisting of a primary encoder and a subordinate decoder is proposed to reconstruct visual stimuli. The encoder is designed based on the residual-in-residual dense blocks to learn the distribution characteristics between EEG signals and visual stimulus images, while the decoder is designed based on the deep neural network to reconstruct the visual stimulus image from the learned deep visual representation. The DVRM can fit the deep and multiview visual features of human natural state and make the reconstructed images more precise. Finally, we evaluate the DVRM in the quality of the generated images on our EEG dataset. The results show that the DVRM have good performance in the task of learning deep visual representation from EEG signals and generating reconstructed images that are realistic and highly resemble the original images.
DC-Net: Divide-and-Conquer for Salient Object Detection
May 24, 2023



In this paper, we introduce Divide-and-Conquer into the salient object detection (SOD) task to enable the model to learn prior knowledge that is for predicting the saliency map. We design a novel network, Divide-and-Conquer Network (DC-Net) which uses two encoders to solve different subtasks that are conducive to predicting the final saliency map, here is to predict the edge maps with width 4 and location maps of salient objects and then aggregate the feature maps with different semantic information into the decoder to predict the final saliency map. The decoder of DC-Net consists of our newly designed two-level Residual nested-ASPP (ResASPP$^{2}$) modules, which have the ability to capture a large number of different scale features with a small number of convolution operations and have the advantages of maintaining high resolution all the time and being able to obtain a large and compact effective receptive field (ERF). Based on the advantage of Divide-and-Conquer's parallel computing, we use Parallel Acceleration to speed up DC-Net, allowing it to achieve competitive performance on six LR-SOD and five HR-SOD datasets under high efficiency (60 FPS and 55 FPS). Codes and results are available: https://github.com/PiggyJerry/DC-Net.
High-resolution Iterative Feedback Network for Camouflaged Object Detection
Mar 22, 2022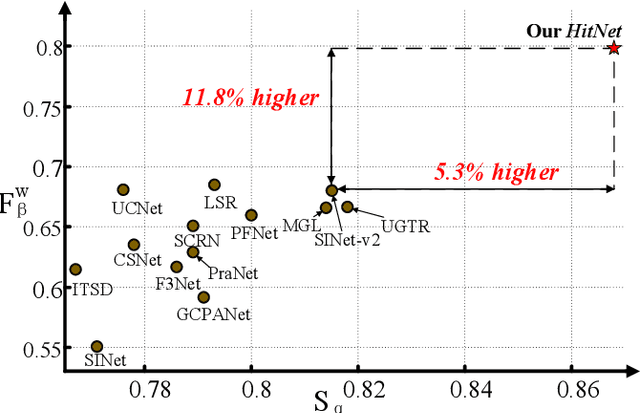



Spotting camouflaged objects that are visually assimilated into the background is tricky for both object detection algorithms and humans who are usually confused or cheated by the perfectly intrinsic similarities between the foreground objects and the background surroundings. To tackle this challenge, we aim to extract the high-resolution texture details to avoid the detail degradation that causes blurred vision in edges and boundaries. We introduce a novel HitNet to refine the low-resolution representations by high-resolution features in an iterative feedback manner, essentially a global loop-based connection among the multi-scale resolutions. In addition, an iterative feedback loss is proposed to impose more constraints on each feedback connection. Extensive experiments on four challenging datasets demonstrate that our \ourmodel~breaks the performance bottleneck and achieves significant improvements compared with 29 state-of-the-art methods. To address the data scarcity in camouflaged scenarios, we provide an application example by employing cross-domain learning to extract the features that can reflect the camouflaged object properties and embed the features into salient objects, thereby generating more camouflaged training samples from the diverse salient object datasets The code will be available at https://github.com/HUuxiaobin/HitNet.
Highly Accurate Dichotomous Image Segmentation
Mar 08, 2022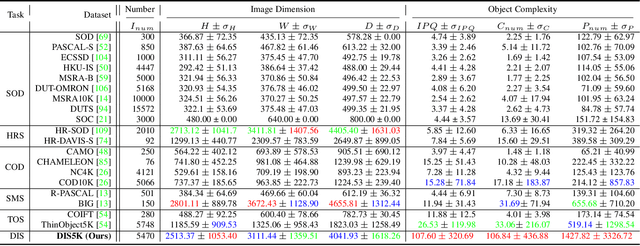
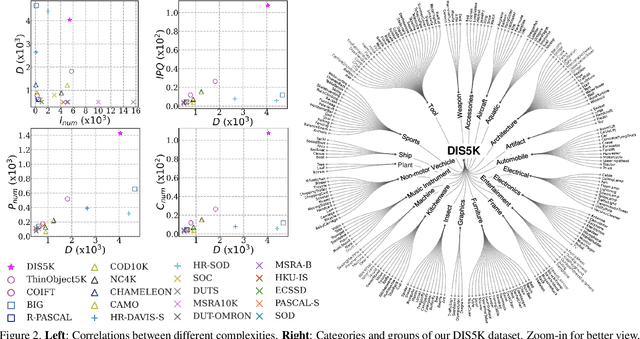


We present a systematic study on a new task called dichotomous image segmentation (DIS), which aims to segment highly accurate objects from natural images. To this end, we collected the first large-scale dataset, called DIS5K, which contains 5,470 high-resolution (e.g., 2K, 4K or larger) images covering camouflaged, salient, or meticulous objects in various backgrounds. All images are annotated with extremely fine-grained labels. In addition, we introduce a simple intermediate supervision baseline (IS-Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms various cutting-edge baselines on the proposed DIS5K, making it a general self-learned supervision network that can help facilitate future research in DIS. Further, we design a new metric called human correction efforts (HCE) which approximates the number of mouse clicking operations required to correct the false positives and false negatives. HCE is utilized to measure the gap between models and real-world applications and thus can complement existing metrics. Finally, we conduct the largest-scale benchmark, evaluating 16 representative segmentation models, providing a more insightful discussion regarding object complexities, and showing several potential applications (e.g., background removal, art design, 3D reconstruction). Hoping these efforts can open up promising directions for both academic and industries. We will release our DIS5K dataset, IS-Net baseline, HCE metric, and the complete benchmark results.
Deep Facial Synthesis: A New Challenge
Jan 07, 2022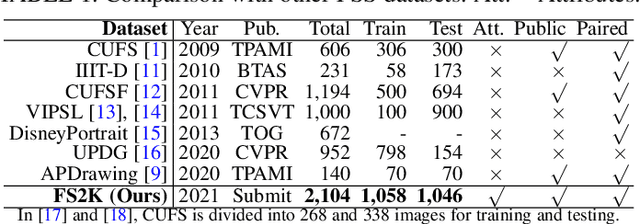


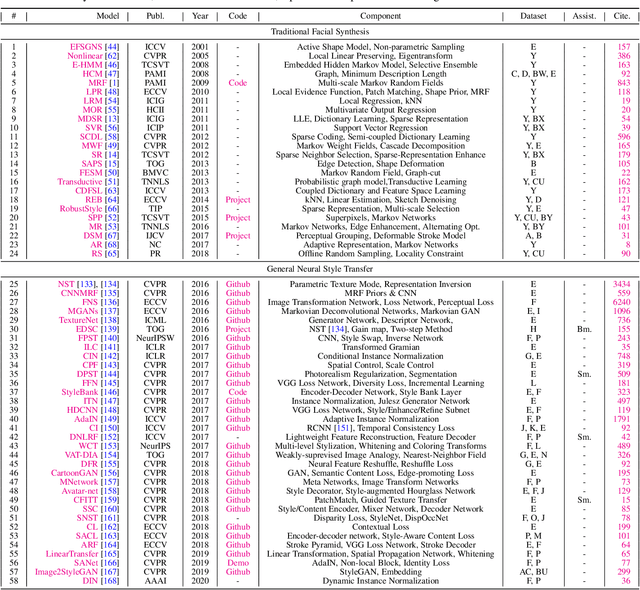
The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
Sample Efficient Learning of Image-Based Diagnostic Classifiers Using Probabilistic Labels
Feb 11, 2021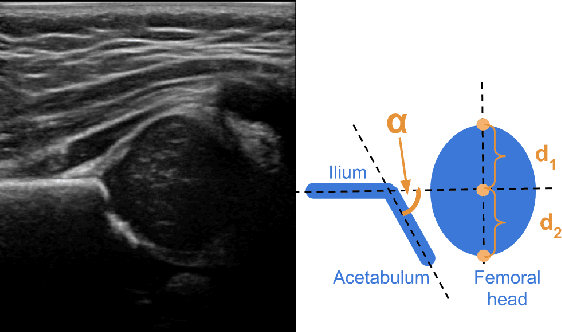
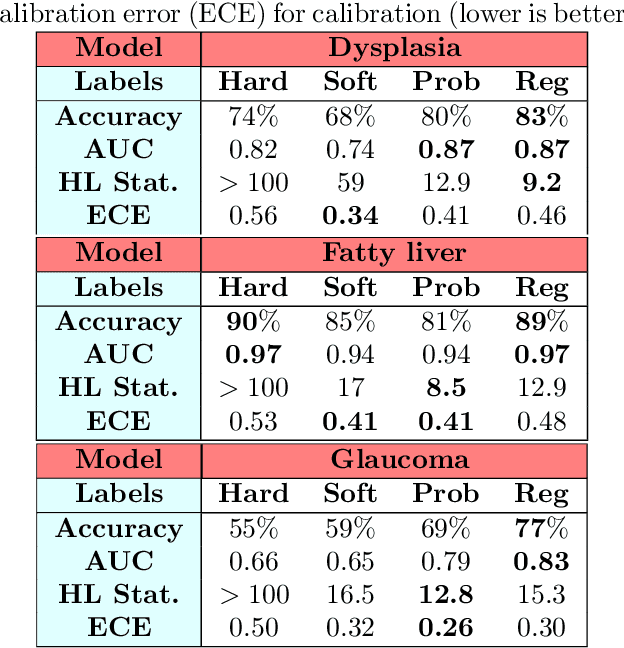
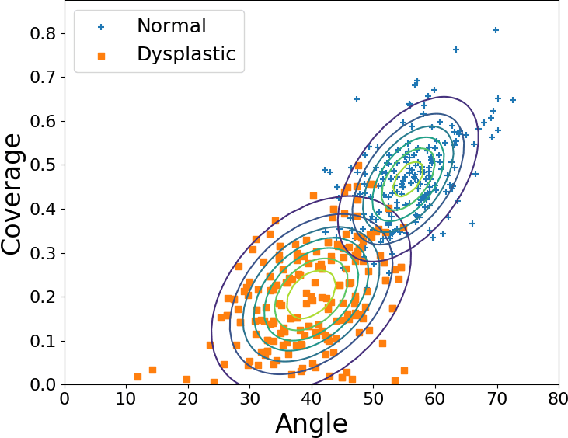
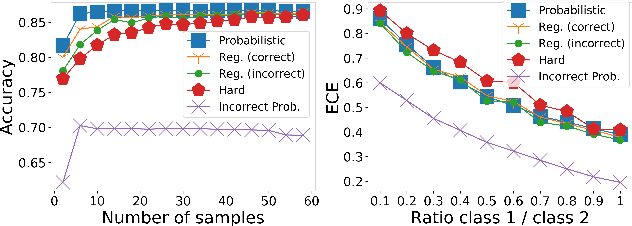
Deep learning approaches often require huge datasets to achieve good generalization. This complicates its use in tasks like image-based medical diagnosis, where the small training datasets are usually insufficient to learn appropriate data representations. For such sensitive tasks it is also important to provide the confidence in the predictions. Here, we propose a way to learn and use probabilistic labels to train accurate and calibrated deep networks from relatively small datasets. We observe gains of up to 22% in the accuracy of models trained with these labels, as compared with traditional approaches, in three classification tasks: diagnosis of hip dysplasia, fatty liver, and glaucoma. The outputs of models trained with probabilistic labels are calibrated, allowing the interpretation of its predictions as proper probabilities. We anticipate this approach will apply to other tasks where few training instances are available and expert knowledge can be encoded as probabilities.
Boundary-Aware Segmentation Network for Mobile and Web Applications
Jan 12, 2021
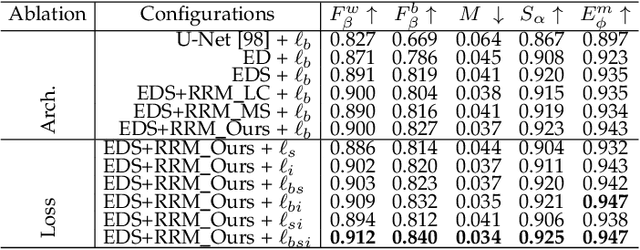
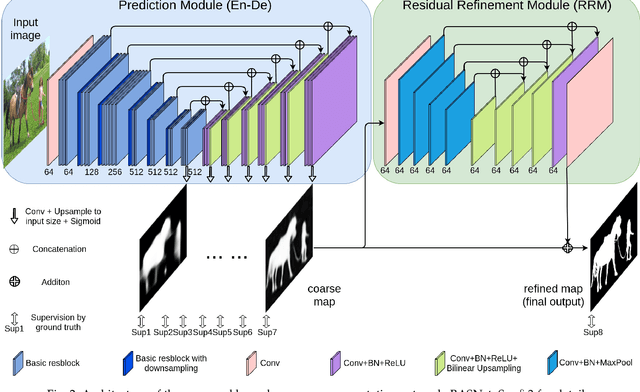
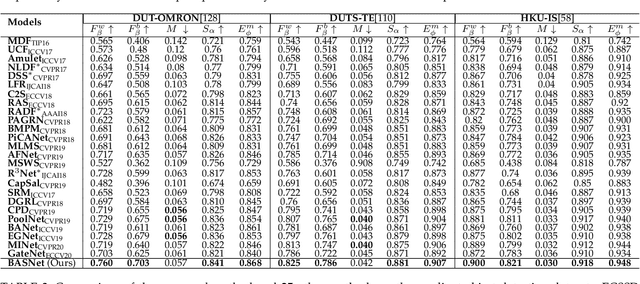
Although deep models have greatly improved the accuracy and robustness of image segmentation, obtaining segmentation results with highly accurate boundaries and fine structures is still a challenging problem. In this paper, we propose a simple yet powerful Boundary-Aware Segmentation Network (BASNet), which comprises a predict-refine architecture and a hybrid loss, for highly accurate image segmentation. The predict-refine architecture consists of a densely supervised encoder-decoder network and a residual refinement module, which are respectively used to predict and refine a segmentation probability map. The hybrid loss is a combination of the binary cross entropy, structural similarity and intersection-over-union losses, which guide the network to learn three-level (ie, pixel-, patch- and map- level) hierarchy representations. We evaluate our BASNet on two reverse tasks including salient object segmentation, camouflaged object segmentation, showing that it achieves very competitive performance with sharp segmentation boundaries. Importantly, BASNet runs at over 70 fps on a single GPU which benefits many potential real applications. Based on BASNet, we further developed two (close to) commercial applications: AR COPY & PASTE, in which BASNet is integrated with augmented reality for "COPYING" and "PASTING" real-world objects, and OBJECT CUT, which is a web-based tool for automatic object background removal. Both applications have already drawn huge amount of attention and have important real-world impacts. The code and two applications will be publicly available at: https://github.com/NathanUA/BASNet.
U$^2$-Net: Going Deeper with Nested U-Structure for Salient Object Detection
May 18, 2020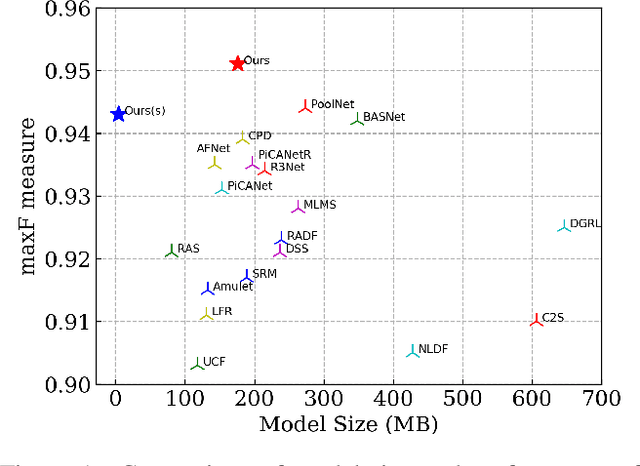
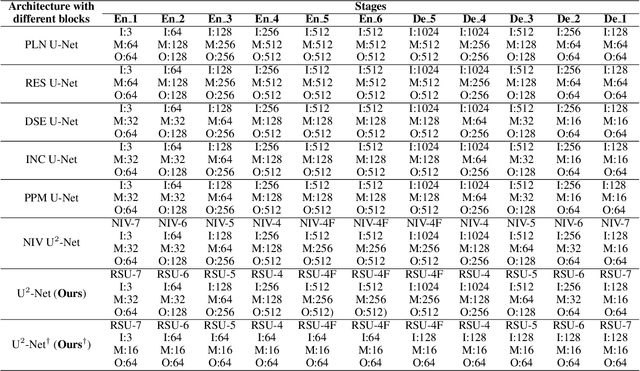
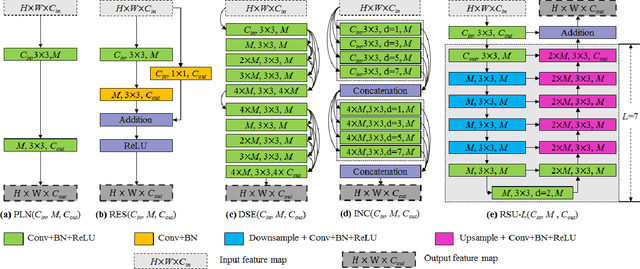
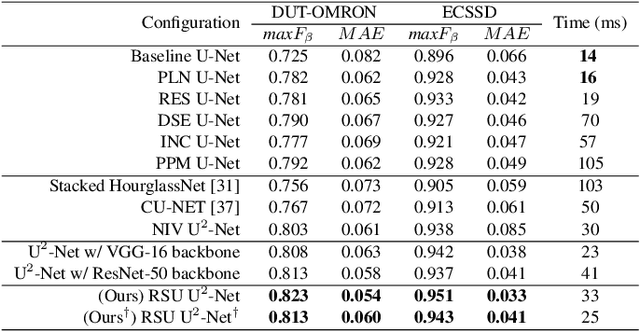
In this paper, we design a simple yet powerful deep network architecture, U$^2$-Net, for salient object detection (SOD). The architecture of our U$^2$-Net is a two-level nested U-structure. The design has the following advantages: (1) it is able to capture more contextual information from different scales thanks to the mixture of receptive fields of different sizes in our proposed ReSidual U-blocks (RSU), (2) it increases the depth of the whole architecture without significantly increasing the computational cost because of the pooling operations used in these RSU blocks. This architecture enables us to train a deep network from scratch without using backbones from image classification tasks. We instantiate two models of the proposed architecture, U$^2$-Net (176.3 MB, 30 FPS on GTX 1080Ti GPU) and U$^2$-Net$^{\dagger}$ (4.7 MB, 40 FPS), to facilitate the usage in different environments. Both models achieve competitive performance on six SOD datasets. The code is available: https://github.com/NathanUA/U-2-Net.
Seq2Emo for Multi-label Emotion Classification Based on Latent Variable Chains Transformation
Nov 08, 2019

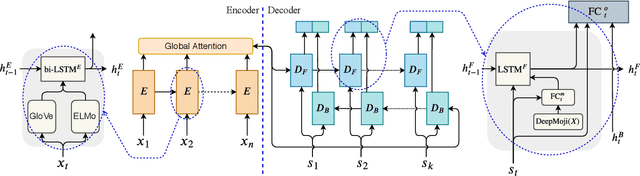

Emotion detection in text is an important task in NLP and is essential in many applications. Most of the existing methods treat this task as a problem of single-label multi-class text classification. To predict multiple emotions for one instance, most of the existing works regard it as a general Multi-label Classification (MLC) problem, where they usually either apply a manually determined threshold on the last output layer of their neural network models or train multiple binary classifiers and make predictions in the fashion of one-vs-all. However, compared to labels in the general MLC datasets, the number of emotion categories are much fewer (less than 10). Additionally, emotions tend to have more correlations with each other. For example, the human usually does not express "joy" and "anger" at the same time, but it is very likely to have "joy" and "love" expressed together. Given this intuition, in this paper, we propose a Latent Variable Chain (LVC) transformation and a tailored model -- Seq2Emo model that not only naturally predicts multiple emotion labels but also takes into consideration their correlations. We perform the experiments on the existing multi-label emotion datasets as well as on our newly collected datasets. The results show that our model compares favorably with existing state-of-the-art methods.
Incremental 3D Line Segment Extraction from Semi-dense SLAM
Apr 26, 2018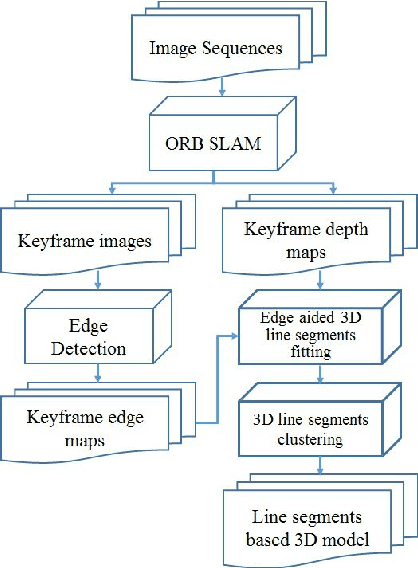
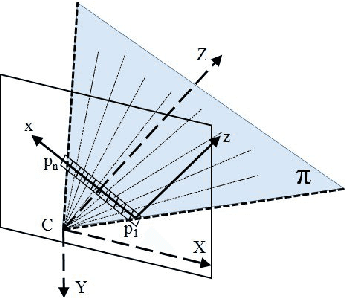
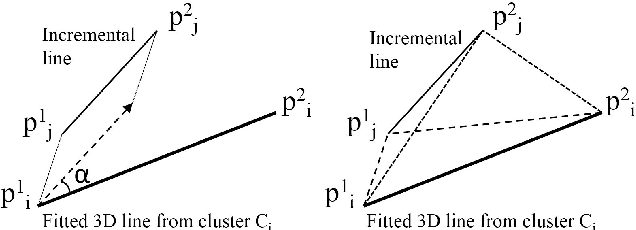

Although semi-dense Simultaneous Localization and Mapping (SLAM) has been becoming more popular over the last few years, there is a lack of efficient methods for representing and processing their large scale point clouds. In this paper, we propose using 3D line segments to simplify the point clouds generated by semi-dense SLAM. Specifically, we present a novel incremental approach for 3D line segment extraction. This approach reduces a 3D line segment fitting problem into two 2D line segment fitting problems and takes advantage of both images and depth maps. In our method, 3D line segments are fitted incrementally along detected edge segments via minimizing fitting errors on two planes. By clustering the detected line segments, the resulting 3D representation of the scene achieves a good balance between compactness and completeness. Our experimental results show that the 3D line segments generated by our method are highly accurate. As an application, we demonstrate that these line segments greatly improve the quality of 3D surface reconstruction compared to a feature point based baseline.