 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM's Attachment to External Knowledge In Dialogue Generation Tasks Through Entity Anonymization
Nov 14, 2025



Knowledge graph-based dialogue generation (KG-DG) is a challenging task requiring models to effectively incorporate external knowledge into conversational responses. While large language models (LLMs) have achieved impressive results across various NLP tasks, their ability to utilize external knowledge in KG-DG remains under-explored. We observe that LLMs often rely on internal knowledge, leading to detachment from provided knowledge graphs, even when they are given a flawlessly retrieved knowledge graph. First, we introduce LLM-KAT, an evaluation procedure for measuring knowledge attachment in generated responses. Second, we propose a simple yet effective entity anonymization technique to encourage LLMs to better leverage external knowledge. Experiments on the OpenDialKG dataset demonstrate that our approach improves LLMs' attachment on external knowledge.
Multilingual Non-Autoregressive Machine Translation without Knowledge Distillation
Feb 06, 2025



Multilingual neural machine translation (MNMT) aims at using one single model for multiple translation directions. Recent work applies non-autoregressive Transformers to improve the efficiency of MNMT, but requires expensive knowledge distillation (KD) processes. To this end, we propose an M-DAT approach to non-autoregressive multilingual machine translation. Our system leverages the recent advance of the directed acyclic Transformer (DAT), which does not require KD. We further propose a pivot back-translation (PivotBT) approach to improve the generalization to unseen translation directions. Experiments show that our M-DAT achieves state-of-the-art performance in non-autoregressive MNMT.
A Decoding Algorithm for Length-Control Summarization Based on Directed Acyclic Transformers
Feb 06, 2025Length-control summarization aims to condense long texts into a short one within a certain length limit. Previous approaches often use autoregressive (AR) models and treat the length requirement as a soft constraint, which may not always be satisfied. In this study, we propose a novel length-control decoding algorithm based on the Directed Acyclic Transformer (DAT). Our approach allows for multiple plausible sequence fragments and predicts a \emph{path} to connect them. In addition, we propose a Sequence Maximum a Posteriori (SeqMAP) decoding algorithm that marginalizes different possible paths and finds the most probable summary satisfying the length budget. Our algorithm is based on beam search, which further facilitates a reranker for performance improvement. Experimental results on the Gigaword and DUC2004 datasets demonstrate our state-of-the-art performance for length-control summarization.
TLXML: Task-Level Explanation of Meta-Learning via Influence Functions
Jan 24, 2025



The scheme of adaptation via meta-learning is seen as an ingredient for solving the problem of data shortage or distribution shift in real-world applications, but it also brings the new risk of inappropriate updates of the model in the user environment, which increases the demand for explainability. Among the various types of XAI methods, establishing a method of explanation based on past experience in meta-learning requires special consideration due to its bi-level structure of training, which has been left unexplored. In this work, we propose influence functions for explaining meta-learning that measure the sensitivities of training tasks to adaptation and inference. We also argue that the approximation of the Hessian using the Gauss-Newton matrix resolves computational barriers peculiar to meta-learning. We demonstrate the adequacy of the method through experiments on task distinction and task distribution distinction using image classification tasks with MAML and Prototypical Network.
Deep Temporal Modelling of Clinical Depression through Social Media Text
Oct 28, 2022



We describe the development of a model to detect user-level clinical depression based on a user's temporal social media posts. Our model uses a Depression Symptoms Detection (DSD) model, which is trained on the largest existing samples of clinician annotated tweets for clinical depression symptoms. We subsequently use our DSD model to extract clinically relevant features, e.g., depression scores and their consequent temporal patterns, as well as user posting activity patterns, e.g., quantifying their ``no activity'' or ``silence.'' Furthermore, to evaluate the efficacy of these extracted features, we create three kinds of datasets including a test dataset, from two existing well-known benchmark datasets for user-level depression detection. We then provide accuracy measures based on single features, baseline features and feature ablation tests, at several different levels of temporal granularity, data distributions, and clinical depression detection related settings to draw a complete picture of the impact of these features across our created datasets. Finally, we show that, in general, only semantic oriented representation models perform well. However, clinical features may enhance overall performance provided that the training and testing distribution is similar, and there is more data in a user's timeline. Further, we show that the predictive capability of depression scores increase significantly while used in a more sensitive clinical depression detection settings.
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
Oct 14, 2021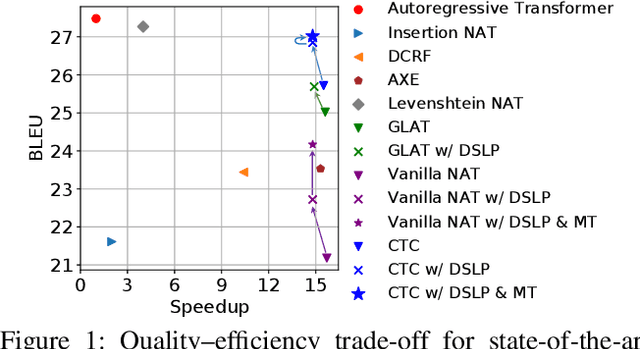
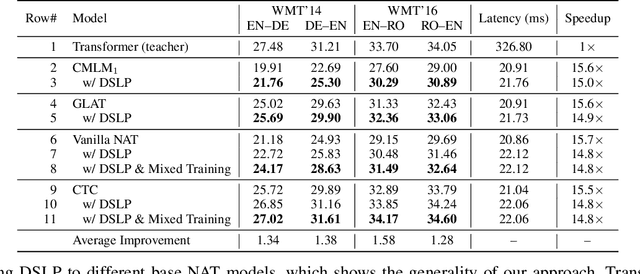
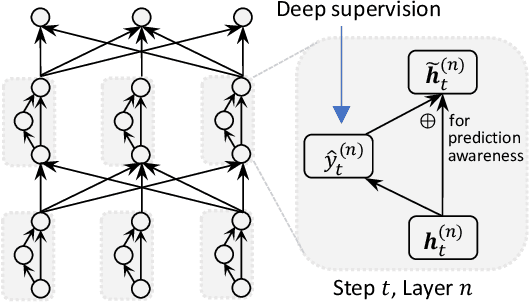
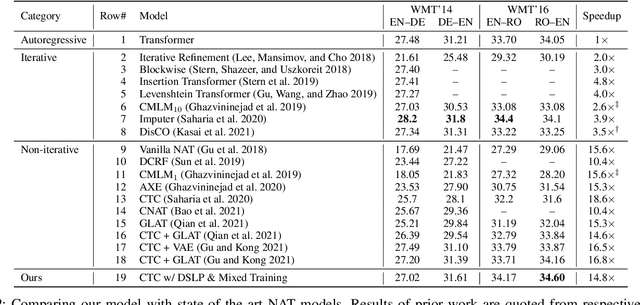
How do we perform efficient inference while retaining high translation quality? Existing neural machine translation models, such as Transformer, achieve high performance, but they decode words one by one, which is inefficient. Recent non-autoregressive translation models speed up the inference, but their quality is still inferior. In this work, we propose DSLP, a highly efficient and high-performance model for machine translation. The key insight is to train a non-autoregressive Transformer with Deep Supervision and feed additional Layer-wise Predictions. We conducted extensive experiments on four translation tasks (both directions of WMT'14 EN-DE and WMT'16 EN-RO). Results show that our approach consistently improves the BLEU scores compared with respective base models. Specifically, our best variant outperforms the autoregressive model on three translation tasks, while being 14.8 times more efficient in inference.
ANA at SemEval-2020 Task 4: mUlti-task learNIng for cOmmonsense reasoNing
Jun 29, 2020In this paper, we describe our mUlti-task learNIng for cOmmonsense reasoNing (UNION) system submitted for Task C of the SemEval2020 Task 4, which is to generate a reason explaining why a given false statement is non-sensical. However, we found in the early experiments that simple adaptations such as fine-tuning GPT2 often yield dull and non-informative generations (e.g. simple negations). In order to generate more meaningful explanations, we propose UNION, a unified end-to-end framework, to utilize several existing commonsense datasets so that it allows a model to learn more dynamics under the scope of commonsense reasoning. In order to perform model selection efficiently, accurately and promptly, we also propose a couple of auxiliary automatic evaluation metrics so that we can extensively compare the models from different perspectives. Our submitted system not only results in a good performance in the proposed metrics but also outperforms its competitors with the highest achieved score of 2.10 for human evaluation while remaining a BLEU score of 15.7. Our code is made publicly available at GitHub.
Seq2Emo for Multi-label Emotion Classification Based on Latent Variable Chains Transformation
Nov 08, 2019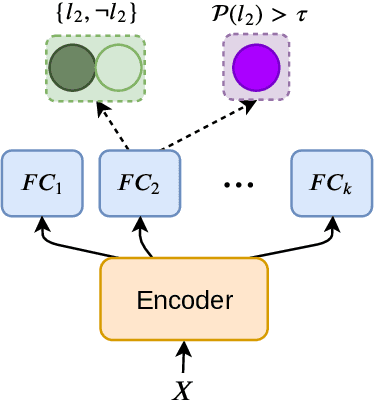


Emotion detection in text is an important task in NLP and is essential in many applications. Most of the existing methods treat this task as a problem of single-label multi-class text classification. To predict multiple emotions for one instance, most of the existing works regard it as a general Multi-label Classification (MLC) problem, where they usually either apply a manually determined threshold on the last output layer of their neural network models or train multiple binary classifiers and make predictions in the fashion of one-vs-all. However, compared to labels in the general MLC datasets, the number of emotion categories are much fewer (less than 10). Additionally, emotions tend to have more correlations with each other. For example, the human usually does not express "joy" and "anger" at the same time, but it is very likely to have "joy" and "love" expressed together. Given this intuition, in this paper, we propose a Latent Variable Chain (LVC) transformation and a tailored model -- Seq2Emo model that not only naturally predicts multiple emotion labels but also takes into consideration their correlations. We perform the experiments on the existing multi-label emotion datasets as well as on our newly collected datasets. The results show that our model compares favorably with existing state-of-the-art methods.
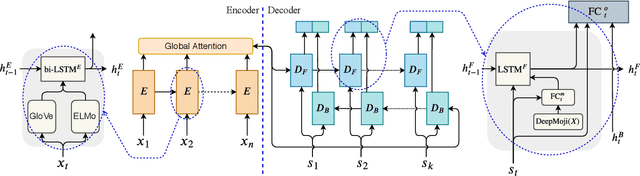
ANA at SemEval-2019 Task 3: Contextual Emotion detection in Conversations through hierarchical LSTMs and BERT
Mar 30, 2019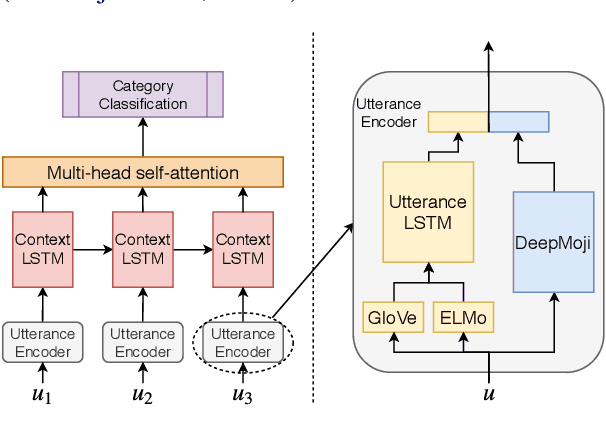
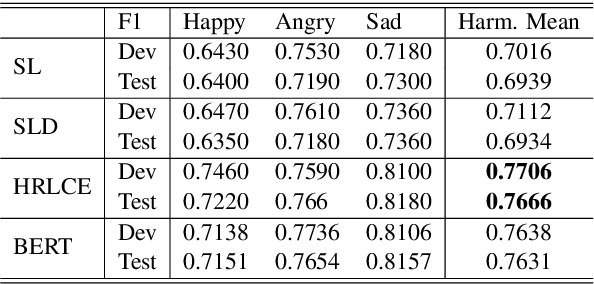
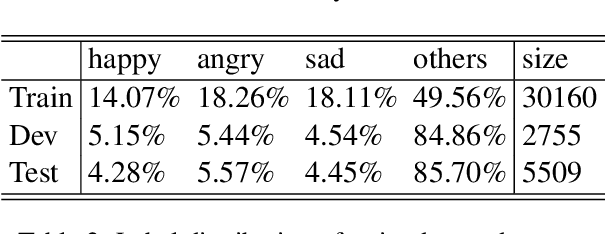
This paper describes the system submitted by ANA Team for the SemEval-2019 Task 3: EmoContext. We propose a novel Hierarchical LSTMs for Contextual Emotion Detection (HRLCE) model. It classifies the emotion of an utterance given its conversational context. The results show that, in this task, our HRCLE outperforms the most recent state-of-the-art text classification framework: BERT. We combine the results generated by BERT and HRCLE to achieve an overall score of 0.7709 which ranked 5th on the final leader board of the competition among 165 Teams.
Generating Responses Expressing Emotion in an Open-domain Dialogue System
Nov 15, 2018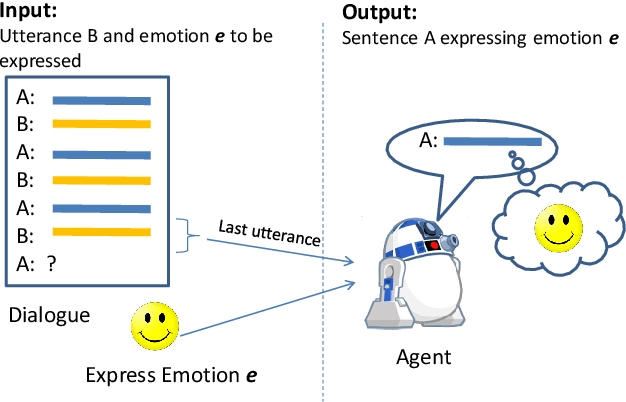
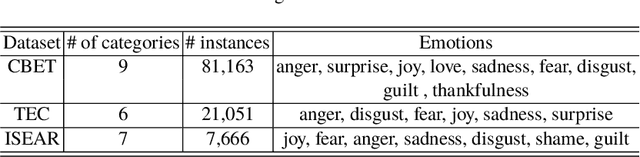
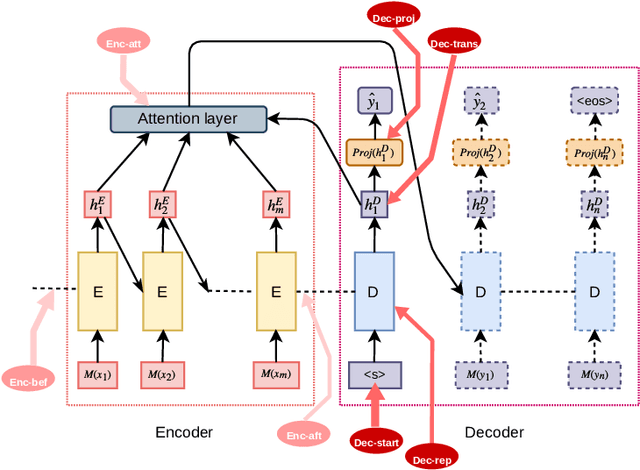
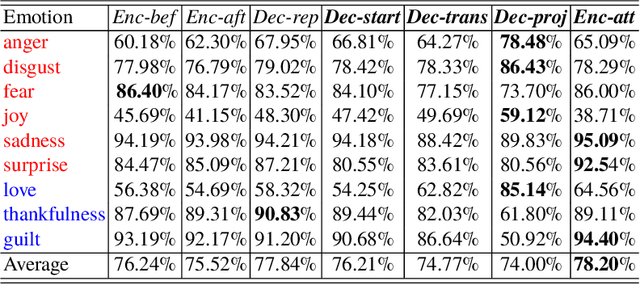
Neural network-based Open-ended conversational agents automatically generate responses based on predictive models learned from a large number of pairs of utterances. The generated responses are typically acceptable as a sentence but are often dull, generic, and certainly devoid of any emotion. In this paper, we present neural models that learn to express a given emotion in the generated response. We propose four models and evaluate them against 3 baselines. An encoder-decoder framework-based model with multiple attention layers provides the best overall performance in terms of expressing the required emotion. While it does not outperform other models on all emotions, it presents promising results in most cases.