 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Temporal Modelling of Clinical Depression through Social Media Text
Oct 28, 2022



We describe the development of a model to detect user-level clinical depression based on a user's temporal social media posts. Our model uses a Depression Symptoms Detection (DSD) model, which is trained on the largest existing samples of clinician annotated tweets for clinical depression symptoms. We subsequently use our DSD model to extract clinically relevant features, e.g., depression scores and their consequent temporal patterns, as well as user posting activity patterns, e.g., quantifying their ``no activity'' or ``silence.'' Furthermore, to evaluate the efficacy of these extracted features, we create three kinds of datasets including a test dataset, from two existing well-known benchmark datasets for user-level depression detection. We then provide accuracy measures based on single features, baseline features and feature ablation tests, at several different levels of temporal granularity, data distributions, and clinical depression detection related settings to draw a complete picture of the impact of these features across our created datasets. Finally, we show that, in general, only semantic oriented representation models perform well. However, clinical features may enhance overall performance provided that the training and testing distribution is similar, and there is more data in a user's timeline. Further, we show that the predictive capability of depression scores increase significantly while used in a more sensitive clinical depression detection settings.
Depression Symptoms Modelling from Social Media Text: An Active Learning Approach
Sep 08, 2022

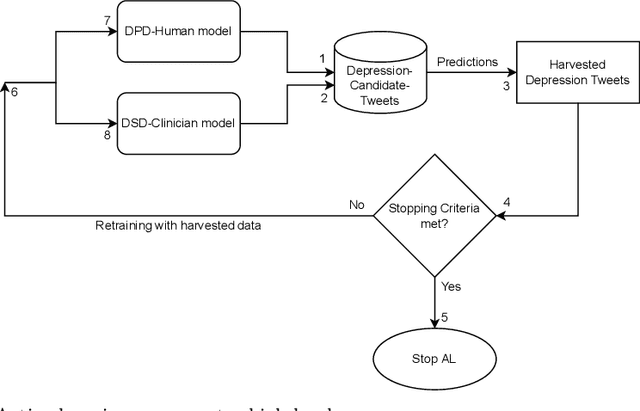
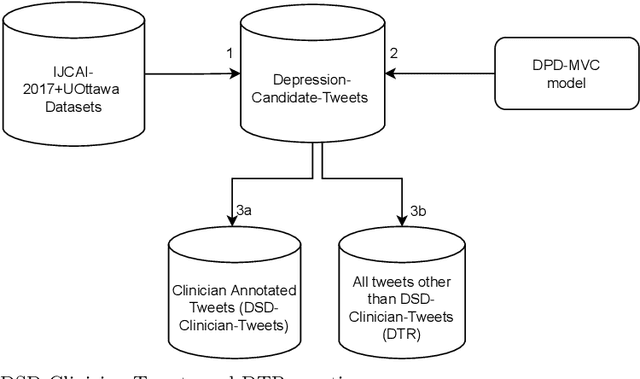
A fundamental component of user-level social media language based clinical depression modelling is depression symptoms detection (DSD). Unfortunately, there does not exist any DSD dataset that reflects both the clinical insights and the distribution of depression symptoms from the samples of self-disclosed depressed population. In our work, we describe an Active Learning (AL) framework which uses an initial supervised learning model that leverages 1) a state-of-the-art large mental health forum text pre-trained language model further fine-tuned on a clinician annotated DSD dataset, 2) a Zero-Shot learning model for DSD, and couples them together to harvest depression symptoms related samples from our large self-curated Depression Tweets Repository (DTR). Our clinician annotated dataset is the largest of its kind. Furthermore, DTR is created from the samples of tweets in self-disclosed depressed users Twitter timeline from two datasets, including one of the largest benchmark datasets for user-level depression detection from Twitter. This further helps preserve the depression symptoms distribution of self-disclosed Twitter users tweets. Subsequently, we iteratively retrain our initial DSD model with the harvested data. We discuss the stopping criteria and limitations of this AL process, and elaborate the underlying constructs which play a vital role in the overall AL process. We show that we can produce a final dataset which is the largest of its kind. Furthermore, a DSD and a Depression Post Detection (DPD) model trained on it achieves significantly better accuracy than their initial version.
STEP-EZ: Syntax Tree guided semantic ExPlanation for Explainable Zero-shot modeling of clinical depression symptoms from text
Jun 23, 2021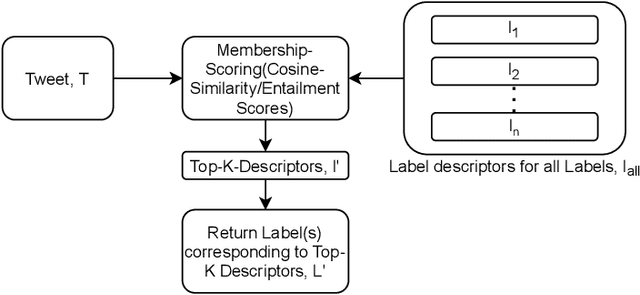
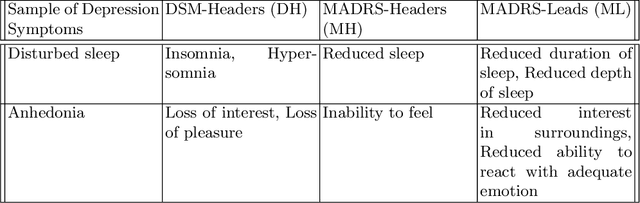


We focus on exploring various approaches of Zero-Shot Learning (ZSL) and their explainability for a challenging yet important supervised learning task notorious for training data scarcity, i.e. Depression Symptoms Detection (DSD) from text. We start with a comprehensive synthesis of different components of our ZSL modeling and analysis of our ground truth samples and Depression symptom clues curation process with the help of a practicing clinician. We next analyze the accuracy of various state-of-the-art ZSL models and their potential enhancements for our task. Further, we sketch a framework for the use of ZSL for hierarchical text-based explanation mechanism, which we call, Syntax Tree-Guided Semantic Explanation (STEP). Finally, we summarize experiments from which we conclude that we can use ZSL models and achieve reasonable accuracy and explainability, measured by a proposed Explainability Index (EI). This work is, to our knowledge, the first work to exhaustively explore the efficacy of ZSL models for DSD task, both in terms of accuracy and explainability.