 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructTest: Benchmarking LLMs' Reasoning through Compositional Structured Outputs
Dec 23, 2024



The rapid development of large language models (LLMs) necessitates robust, unbiased, and scalable methods for evaluating their capabilities. However, human annotations are expensive to scale, model-based evaluations are prone to biases in answer style, while target-answer-based benchmarks are vulnerable to data contamination and cheating. To address these limitations, we propose StructTest, a novel benchmark that evaluates LLMs on their ability to produce compositionally specified structured outputs as an unbiased, cheap-to-run and difficult-to-cheat measure. The evaluation is done deterministically by a rule-based evaluator, which can be easily extended to new tasks. By testing structured outputs across diverse task domains -- including Summarization, Code, HTML and Math -- we demonstrate that StructTest serves as a good proxy for general reasoning abilities, as producing structured outputs often requires internal logical reasoning. We believe that StructTest offers a critical, complementary approach to objective and robust model evaluation.
Deep Temporal Modelling of Clinical Depression through Social Media Text
Oct 28, 2022



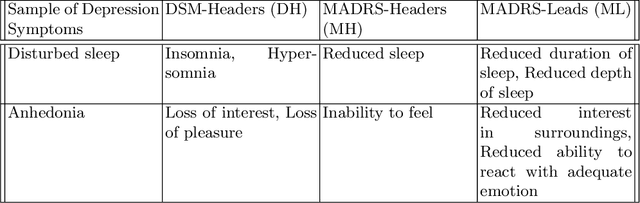
We describe the development of a model to detect user-level clinical depression based on a user's temporal social media posts. Our model uses a Depression Symptoms Detection (DSD) model, which is trained on the largest existing samples of clinician annotated tweets for clinical depression symptoms. We subsequently use our DSD model to extract clinically relevant features, e.g., depression scores and their consequent temporal patterns, as well as user posting activity patterns, e.g., quantifying their ``no activity'' or ``silence.'' Furthermore, to evaluate the efficacy of these extracted features, we create three kinds of datasets including a test dataset, from two existing well-known benchmark datasets for user-level depression detection. We then provide accuracy measures based on single features, baseline features and feature ablation tests, at several different levels of temporal granularity, data distributions, and clinical depression detection related settings to draw a complete picture of the impact of these features across our created datasets. Finally, we show that, in general, only semantic oriented representation models perform well. However, clinical features may enhance overall performance provided that the training and testing distribution is similar, and there is more data in a user's timeline. Further, we show that the predictive capability of depression scores increase significantly while used in a more sensitive clinical depression detection settings.
Depression Symptoms Modelling from Social Media Text: An Active Learning Approach
Sep 08, 2022

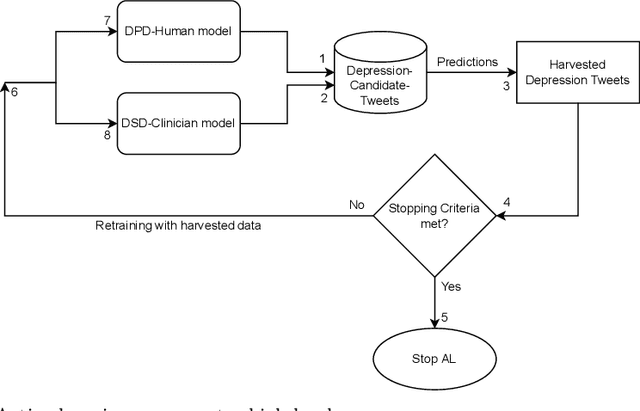
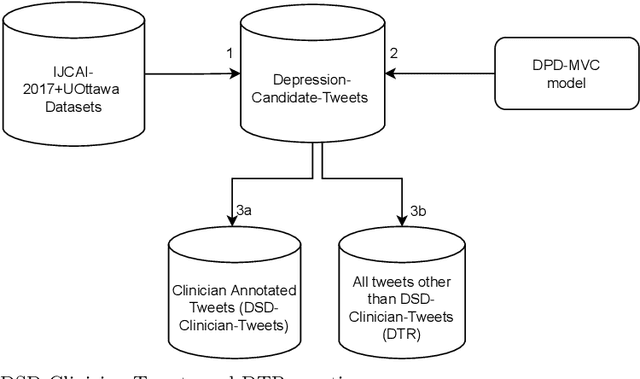
A fundamental component of user-level social media language based clinical depression modelling is depression symptoms detection (DSD). Unfortunately, there does not exist any DSD dataset that reflects both the clinical insights and the distribution of depression symptoms from the samples of self-disclosed depressed population. In our work, we describe an Active Learning (AL) framework which uses an initial supervised learning model that leverages 1) a state-of-the-art large mental health forum text pre-trained language model further fine-tuned on a clinician annotated DSD dataset, 2) a Zero-Shot learning model for DSD, and couples them together to harvest depression symptoms related samples from our large self-curated Depression Tweets Repository (DTR). Our clinician annotated dataset is the largest of its kind. Furthermore, DTR is created from the samples of tweets in self-disclosed depressed users Twitter timeline from two datasets, including one of the largest benchmark datasets for user-level depression detection from Twitter. This further helps preserve the depression symptoms distribution of self-disclosed Twitter users tweets. Subsequently, we iteratively retrain our initial DSD model with the harvested data. We discuss the stopping criteria and limitations of this AL process, and elaborate the underlying constructs which play a vital role in the overall AL process. We show that we can produce a final dataset which is the largest of its kind. Furthermore, a DSD and a Depression Post Detection (DPD) model trained on it achieves significantly better accuracy than their initial version.
A comprehensive empirical analysis on cross-domain semantic enrichment for detection of depressive language
Jun 24, 2021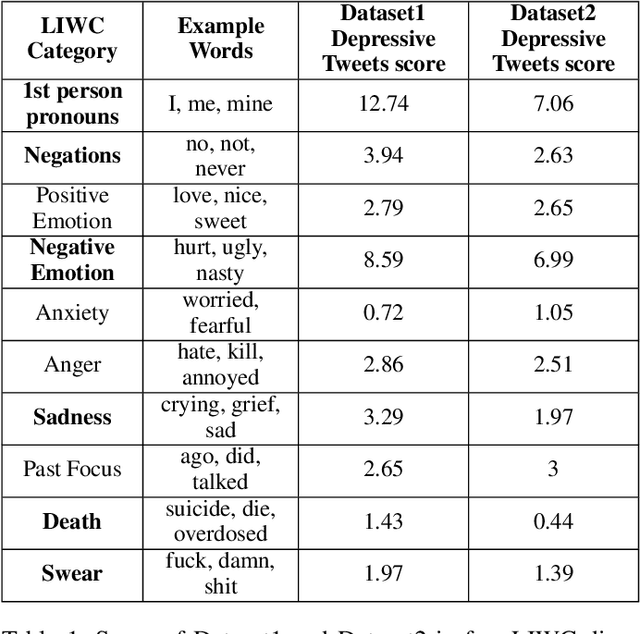

We analyze the process of creating word embedding feature representations designed for a learning task when annotated data is scarce, for example, in depressive language detection from Tweets. We start with a rich word embedding pre-trained from a large general dataset, which is then augmented with embeddings learned from a much smaller and more specific domain dataset through a simple non-linear mapping mechanism. We also experimented with several other more sophisticated methods of such mapping including, several auto-encoder based and custom loss-function based methods that learn embedding representations through gradually learning to be close to the words of similar semantics and distant to dissimilar semantics. Our strengthened representations better capture the semantics of the depression domain, as it combines the semantics learned from the specific domain coupled with word coverage from the general language. We also present a comparative performance analyses of our word embedding representations with a simple bag-of-words model, well known sentiment and psycholinguistic lexicons, and a general pre-trained word embedding. When used as feature representations for several different machine learning methods, including deep learning models in a depressive Tweets identification task, we show that our augmented word embedding representations achieve a significantly better F1 score than the others, specially when applied to a high quality dataset. Also, we present several data ablation tests which confirm the efficacy of our augmentation techniques.
STEP-EZ: Syntax Tree guided semantic ExPlanation for Explainable Zero-shot modeling of clinical depression symptoms from text
Jun 23, 2021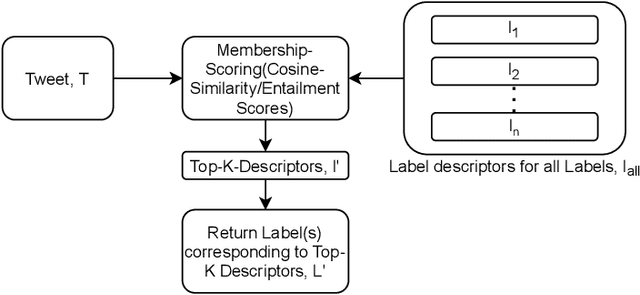


We focus on exploring various approaches of Zero-Shot Learning (ZSL) and their explainability for a challenging yet important supervised learning task notorious for training data scarcity, i.e. Depression Symptoms Detection (DSD) from text. We start with a comprehensive synthesis of different components of our ZSL modeling and analysis of our ground truth samples and Depression symptom clues curation process with the help of a practicing clinician. We next analyze the accuracy of various state-of-the-art ZSL models and their potential enhancements for our task. Further, we sketch a framework for the use of ZSL for hierarchical text-based explanation mechanism, which we call, Syntax Tree-Guided Semantic Explanation (STEP). Finally, we summarize experiments from which we conclude that we can use ZSL models and achieve reasonable accuracy and explainability, measured by a proposed Explainability Index (EI). This work is, to our knowledge, the first work to exhaustively explore the efficacy of ZSL models for DSD task, both in terms of accuracy and explainability.
Basic and Depression Specific Emotion Identification in Tweets: Multi-label Classification Experiments
May 26, 2021
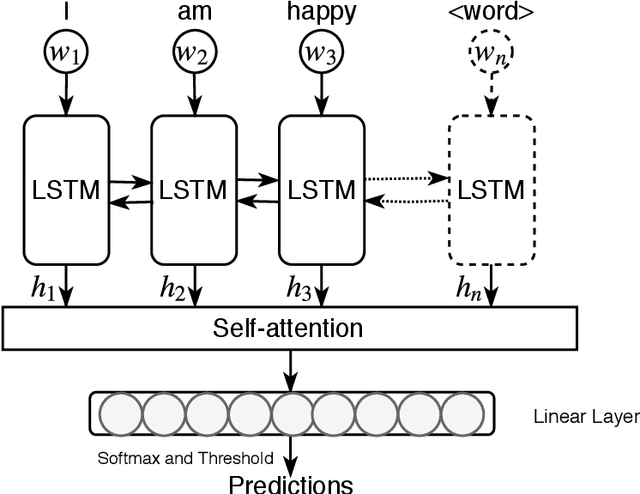

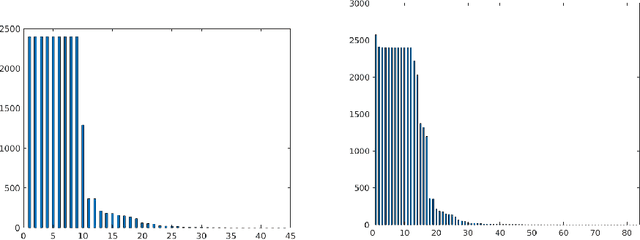
In this paper, we present empirical analysis on basic and depression specific multi-emotion mining in Tweets with the help of state of the art multi-label classifiers. We choose our basic emotions from a hybrid emotion model consisting of the common emotions from four highly regarded psychological models of emotions. Moreover, we augment that emotion model with new emotion categories because of their importance in the analysis of depression. Most of those additional emotions have not been used in previous emotion mining research. Our experimental analyses show that a cost sensitive RankSVM algorithm and a Deep Learning model are both robust, measured by both Macro F-measures and Micro F-measures. This suggests that these algorithms are superior in addressing the widely known data imbalance problem in multi-label learning. Moreover, our application of Deep Learning performs the best, giving it an edge in modeling deep semantic features of our extended emotional categories.
Seq2Emo for Multi-label Emotion Classification Based on Latent Variable Chains Transformation
Nov 08, 2019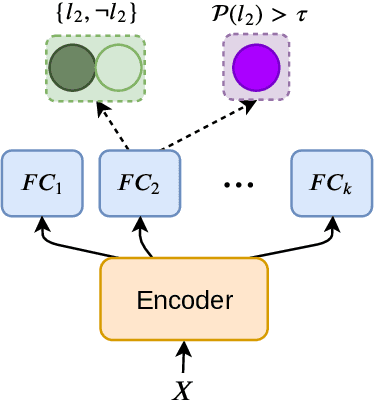

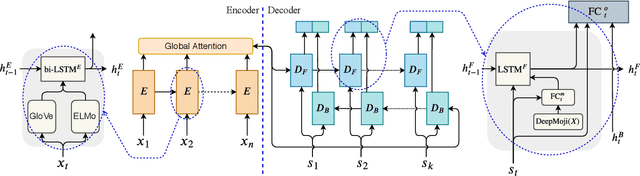

Emotion detection in text is an important task in NLP and is essential in many applications. Most of the existing methods treat this task as a problem of single-label multi-class text classification. To predict multiple emotions for one instance, most of the existing works regard it as a general Multi-label Classification (MLC) problem, where they usually either apply a manually determined threshold on the last output layer of their neural network models or train multiple binary classifiers and make predictions in the fashion of one-vs-all. However, compared to labels in the general MLC datasets, the number of emotion categories are much fewer (less than 10). Additionally, emotions tend to have more correlations with each other. For example, the human usually does not express "joy" and "anger" at the same time, but it is very likely to have "joy" and "love" expressed together. Given this intuition, in this paper, we propose a Latent Variable Chain (LVC) transformation and a tailored model -- Seq2Emo model that not only naturally predicts multiple emotion labels but also takes into consideration their correlations. We perform the experiments on the existing multi-label emotion datasets as well as on our newly collected datasets. The results show that our model compares favorably with existing state-of-the-art methods.