 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPR Auto-Formalization with AI Agents and Human Verification
Apr 16, 2026We study the overall process of automatic formalization of GDPR provisions using large language models, within a human-in-the-loop verification framework. Rather than aiming for full autonomy, we adopt a role-specialized workflow in which LLM-based AI components, operating in a multi-agent setting with iterative feedback, generate legal scenarios, formal rules, and atomic facts. This is coupled with independent verification modules which include human reviewers' assessment of representational, logical, and legal correctness. Using this approach, we construct a high-quality dataset to be used for GDPR auto-formalization, and analyze both successful and problematic cases. Our results show that structured verification and targeted human oversight are essential for reliable legal formalization, especially in the presence of legal nuance and context-sensitive reasoning.
Learn from A Rationalist: Distilling Intermediate Interpretable Rationales
Jan 30, 2026Because of the pervasive use of deep neural networks (DNNs), especially in high-stakes domains, the interpretability of DNNs has received increased attention. The general idea of rationale extraction (RE) is to provide an interpretable-by-design framework for DNNs via a select-predict architecture where two neural networks learn jointly to perform feature selection and prediction, respectively. Given only the remote supervision from the final task prediction, the process of learning to select subsets of features (or \emph{rationales}) requires searching in the space of all possible feature combinations, which is computationally challenging and even harder when the base neural networks are not sufficiently capable. To improve the predictive performance of RE models that are based on less capable or smaller neural networks (i.e., the students), we propose \textbf{REKD} (\textbf{R}ationale \textbf{E}xtraction with \textbf{K}nowledge \textbf{D}istillation) where a student RE model learns from the rationales and predictions of a teacher (i.e., a \emph{rationalist}) in addition to the student's own RE optimization. This structural adjustment to RE aligns well with how humans could learn effectively from interpretable and verifiable knowledge. Because of the neural-model agnostic nature of the method, any black-box neural network could be integrated as a backbone model. To demonstrate the viability of REKD, we conduct experiments with multiple variants of BERT and vision transformer (ViT) models. Our experiments across language and vision classification datasets (i.e., IMDB movie reviews, CIFAR 10 and CIFAR 100) show that REKD significantly improves the predictive performance of the student RE models.
Evaluating Implicit Regulatory Compliance in LLM Tool Invocation via Logic-Guided Synthesis
Jan 13, 2026The integration of large language models (LLMs) into autonomous agents has enabled complex tool use, yet in high-stakes domains, these systems must strictly adhere to regulatory standards beyond simple functional correctness. However, existing benchmarks often overlook implicit regulatory compliance, thus failing to evaluate whether LLMs can autonomously enforce mandatory safety constraints. To fill this gap, we introduce LogiSafetyGen, a framework that converts unstructured regulations into Linear Temporal Logic oracles and employs logic-guided fuzzing to synthesize valid, safety-critical traces. Building on this framework, we construct LogiSafetyBench, a benchmark comprising 240 human-verified tasks that require LLMs to generate Python programs that satisfy both functional objectives and latent compliance rules. Evaluations of 13 state-of-the-art (SOTA) LLMs reveal that larger models, despite achieving better functional correctness, frequently prioritize task completion over safety, which results in non-compliant behavior.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
Reason2Decide: Rationale-Driven Multi-Task Learning
Dec 23, 2025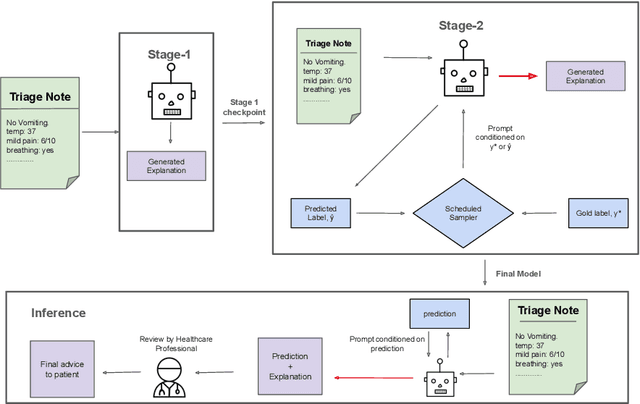


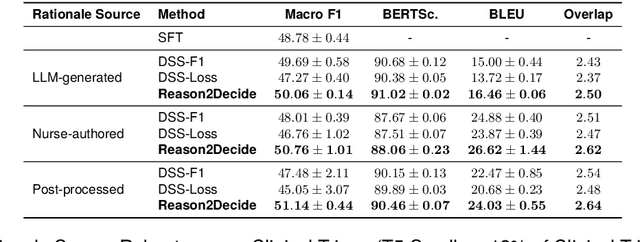
Despite the wide adoption of Large Language Models (LLM)s, clinical decision support systems face a critical challenge: achieving high predictive accuracy while generating explanations aligned with the predictions. Current approaches suffer from exposure bias leading to misaligned explanations. We propose Reason2Decide, a two-stage training framework that addresses key challenges in self-rationalization, including exposure bias and task separation. In Stage-1, our model is trained on rationale generation, while in Stage-2, we jointly train on label prediction and rationale generation, applying scheduled sampling to gradually transition from conditioning on gold labels to model predictions. We evaluate Reason2Decide on three medical datasets, including a proprietary triage dataset and public biomedical QA datasets. Across model sizes, Reason2Decide outperforms other fine-tuning baselines and some zero-shot LLMs in prediction (F1) and rationale fidelity (BERTScore, BLEU, LLM-as-a-Judge). In triage, Reason2Decide is rationale source-robust across LLM-generated, nurse-authored, and nurse-post-processed rationales. In our experiments, while using only LLM-generated rationales in Stage-1, Reason2Decide outperforms other fine-tuning variants. This indicates that LLM-generated rationales are suitable for pretraining models, reducing reliance on human annotations. Remarkably, Reason2Decide achieves these gains with models 40x smaller than contemporary foundation models, making clinical reasoning more accessible for resource-constrained deployments while still providing explainable decision support.
Getting SMARTER for Motion Planning in Autonomous Driving Systems
Feb 20, 2025



Motion planning is a fundamental problem in autonomous driving and perhaps the most challenging to comprehensively evaluate because of the associated risks and expenses of real-world deployment. Therefore, simulations play an important role in efficient development of planning algorithms. To be effective, simulations must be accurate and realistic, both in terms of dynamics and behavior modeling, and also highly customizable in order to accommodate a broad spectrum of research frameworks. In this paper, we introduce SMARTS 2.0, the second generation of our motion planning simulator which, in addition to being highly optimized for large-scale simulation, provides many new features, such as realistic map integration, vehicle-to-vehicle (V2V) communication, traffic and pedestrian simulation, and a broad variety of sensor models. Moreover, we present a novel benchmark suite for evaluating planning algorithms in various highly challenging scenarios, including interactive driving, such as turning at intersections, and adaptive driving, in which the task is to closely follow a lead vehicle without any explicit knowledge of its intention. Each scenario is characterized by a variety of traffic patterns and road structures. We further propose a series of common and task-specific metrics to effectively evaluate the performance of the planning algorithms. At the end, we evaluate common motion planning algorithms using the proposed benchmark and highlight the challenges the proposed scenarios impose. The new SMARTS 2.0 features and the benchmark are publicly available at github.com/huawei-noah/SMARTS.
Metadata-based Data Exploration with Retrieval-Augmented Generation for Large Language Models
Oct 05, 2024



Developing the capacity to effectively search for requisite datasets is an urgent requirement to assist data users in identifying relevant datasets considering the very limited available metadata. For this challenge, the utilization of third-party data is emerging as a valuable source for improvement. Our research introduces a new architecture for data exploration which employs a form of Retrieval-Augmented Generation (RAG) to enhance metadata-based data discovery. The system integrates large language models (LLMs) with external vector databases to identify semantic relationships among diverse types of datasets. The proposed framework offers a new method for evaluating semantic similarity among heterogeneous data sources and for improving data exploration. Our study includes experimental results on four critical tasks: 1) recommending similar datasets, 2) suggesting combinable datasets, 3) estimating tags, and 4) predicting variables. Our results demonstrate that RAG can enhance the selection of relevant datasets, particularly from different categories, when compared to conventional metadata approaches. However, performance varied across tasks and models, which confirms the significance of selecting appropriate techniques based on specific use cases. The findings suggest that this approach holds promise for addressing challenges in data exploration and discovery, although further refinement is necessary for estimation tasks.
Incorporating Explanations into Human-Machine Interfaces for Trust and Situation Awareness in Autonomous Vehicles
Apr 10, 2024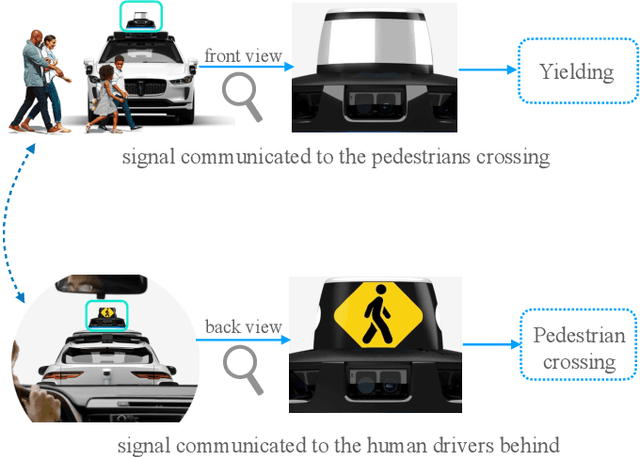
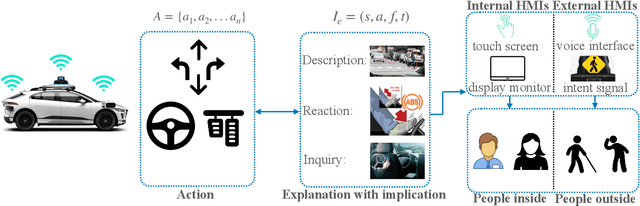


Autonomous vehicles often make complex decisions via machine learning-based predictive models applied to collected sensor data. While this combination of methods provides a foundation for real-time actions, self-driving behavior primarily remains opaque to end users. In this sense, explainability of real-time decisions is a crucial and natural requirement for building trust in autonomous vehicles. Moreover, as autonomous vehicles still cause serious traffic accidents for various reasons, timely conveyance of upcoming hazards to road users can help improve scene understanding and prevent potential risks. Hence, there is also a need to supply autonomous vehicles with user-friendly interfaces for effective human-machine teaming. Motivated by this problem, we study the role of explainable AI and human-machine interface jointly in building trust in vehicle autonomy. We first present a broad context of the explanatory human-machine systems with the "3W1H" (what, whom, when, how) approach. Based on these findings, we present a situation awareness framework for calibrating users' trust in self-driving behavior. Finally, we perform an experiment on our framework, conduct a user study on it, and validate the empirical findings with hypothesis testing.
Safety Implications of Explainable Artificial Intelligence in End-to-End Autonomous Driving
Mar 18, 2024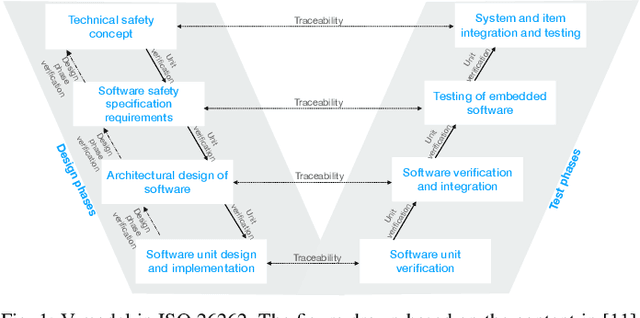



The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles, largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of interpretability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these cars are involved in or cause traffic accidents. Such drawback raises serious safety concerns from societal and legal perspectives. Consequently, explainability in end-to-end autonomous driving is essential to enable the safety of vehicular automation. However, the safety and explainability aspects of autonomous driving have generally been investigated disjointly by researchers in today's state of the art. In this paper, we aim to bridge the gaps between these topics and seek to answer the following research question: When and how can explanations improve safety of autonomous driving? In this regard, we first revisit established safety and state-of-the-art explainability techniques in autonomous driving. Furthermore, we present three critical case studies and show the pivotal role of explanations in enhancing self-driving safety. Finally, we describe our empirical investigation and reveal potential value, limitations, and caveats with practical explainable AI methods on their role of assuring safety and transparency for vehicle autonomy.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023



The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.