 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrologMCP: A Standardized Prolog Tool Interface for LLM Agents
Jun 12, 2026Frontier reasoning-tuned language models still fail on deductive tasks at depth, and the cost of improved performance through extended internal reasoning scales poorly. Symbolic delegation offers a complementary route: a language model translates the problem, while a solver performs the inference. However, current autoformalization pipelines for logic programming are typically bespoke integrations tied to particular tasks or agents. We introduce PrologMCP, a task-agnostic, open-source server that exposes Prolog as a stateful tool through the Model Context Protocol (MCP). Its compact tool interface, structured error reporting, and per-session isolation make the translate-run-inspect-repair loop a reusable primitive for MCP-capable agents. We evaluate a formalizer agent enhanced with PrologMCP against standard and reasoning LLMs (Claude Sonnet 4.6, GPT-4.1, and o4-mini) on two subsets of PARARULE-Plus: a general-purpose sample and a more challenging one targeting a specific failure mode of natural-language reasoning. On the general sample, the formalizer matches or exceeds reasoning LLMs (accuracy 1.00 vs.\ 1.00 / 0.998), with the largest gains over standard models (0.762 for GPT-4.1). On the challenging subset, the formalizer remains near-perfect (1.00 / 0.99) while reasoning LLMs drop to 0.95 / 0.94. These results suggest that delegating inference to Prolog via MCP is a robust and inspectable alternative to extended natural-language reasoning.
The Influence of Human-inspired Agentic Sophistication in LLM-driven Strategic Reasoners
May 14, 2025The rapid rise of large language models (LLMs) has shifted artificial intelligence (AI) research toward agentic systems, motivating the use of weaker and more flexible notions of agency. However, this shift raises key questions about the extent to which LLM-based agents replicate human strategic reasoning, particularly in game-theoretic settings. In this context, we examine the role of agentic sophistication in shaping artificial reasoners' performance by evaluating three agent designs: a simple game-theoretic model, an unstructured LLM-as-agent model, and an LLM integrated into a traditional agentic framework. Using guessing games as a testbed, we benchmarked these agents against human participants across general reasoning patterns and individual role-based objectives. Furthermore, we introduced obfuscated game scenarios to assess agents' ability to generalise beyond training distributions. Our analysis, covering over 2000 reasoning samples across 25 agent configurations, shows that human-inspired cognitive structures can enhance LLM agents' alignment with human strategic behaviour. Still, the relationship between agentic design complexity and human-likeness is non-linear, highlighting a critical dependence on underlying LLM capabilities and suggesting limits to simple architectural augmentation.
Approximating Human Strategic Reasoning with LLM-Enhanced Recursive Reasoners Leveraging Multi-agent Hypergames
Feb 11, 2025LLM-driven multi-agent-based simulations have been gaining traction with applications in game-theoretic and social simulations. While most implementations seek to exploit or evaluate LLM-agentic reasoning, they often do so with a weak notion of agency and simplified architectures. We implement a role-based multi-agent strategic interaction framework tailored to sophisticated recursive reasoners, providing the means for systematic in-depth development and evaluation of strategic reasoning. Our game environment is governed by the umpire responsible for facilitating games, from matchmaking through move validation to environment management. Players incorporate state-of-the-art LLMs in their decision mechanism, relying on a formal hypergame-based model of hierarchical beliefs. We use one-shot, 2-player beauty contests to evaluate the recursive reasoning capabilities of the latest LLMs, providing a comparison to an established baseline model from economics and data from human experiments. Furthermore, we introduce the foundations of an alternative semantic measure of reasoning to the k-level theory. Our experiments show that artificial reasoners can outperform the baseline model in terms of both approximating human behaviour and reaching the optimal solution.
Autoformalizing and Simulating Game-Theoretic Scenarios using LLM-augmented Agents
Dec 11, 2024



Game-theoretic simulations are a versatile tool for exploring interactions of both natural and artificial agents. However, modelling real-world scenarios and developing simulations often require substantial human expertise and effort. To streamline this process, we present a framework that enables the autoformalization of game-theoretic scenarios using agents augmented by large language models (LLMs). In this approach, LLM-augmented agents translate natural language scenario descriptions into executable logic programs that define the rules of each game, validating these programs for syntactic accuracy. A tournament simulation is then conducted, during which the agents test the functionality of the generated games by playing them. When a ground truth payoff matrix is available, an exact semantic validation can also be performed. The validated games can then be used in further simulations to assess the effectiveness of different strategies. We evaluate our approach on a diverse set of 55 natural language descriptions across five well-known 2x2 simultaneous-move games, demonstrating 96% syntactic and 87% semantic correctness in the generated game rules. Additionally, we assess the LLM-augmented agents' capability to autoformalize strategies for gameplay.
Logic-Enhanced Language Model Agents for Trustworthy Social Simulations
Aug 28, 2024


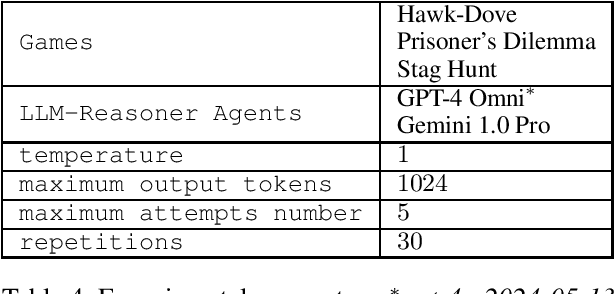
We introduce the Logic-Enhanced Language Model Agents (LELMA) framework, a novel approach to enhance the trustworthiness of social simulations that utilize large language models (LLMs). While LLMs have gained attention as agents for simulating human behaviour, their applicability in this role is limited by issues such as inherent hallucinations and logical inconsistencies. LELMA addresses these challenges by integrating LLMs with symbolic AI, enabling logical verification of the reasoning generated by LLMs. This verification process provides corrective feedback, refining the reasoning output. The framework consists of three main components: an LLM-Reasoner for producing strategic reasoning, an LLM-Translator for mapping natural language reasoning to logic queries, and a Solver for evaluating these queries. This study focuses on decision-making in game-theoretic scenarios as a model of human interaction. Experiments involving the Hawk-Dove game, Prisoner's Dilemma, and Stag Hunt highlight the limitations of state-of-the-art LLMs, GPT-4 Omni and Gemini 1.0 Pro, in producing correct reasoning in these contexts. LELMA demonstrates high accuracy in error detection and improves the reasoning correctness of LLMs via self-refinement, particularly in GPT-4 Omni.
Towards Explainable Strategy Templates using NLP Transformers
Nov 23, 2023This paper bridges the gap between mathematical heuristic strategies learned from Deep Reinforcement Learning (DRL) in automated agent negotiation, and comprehensible, natural language explanations. Our aim is to make these strategies more accessible to non-experts. By leveraging traditional Natural Language Processing (NLP) techniques and Large Language Models (LLMs) equipped with Transformers, we outline how parts of DRL strategies composed of parts within strategy templates can be transformed into user-friendly, human-like English narratives. To achieve this, we present a top-level algorithm that involves parsing mathematical expressions of strategy templates, semantically interpreting variables and structures, generating rule-based primary explanations, and utilizing a Generative Pre-trained Transformer (GPT) model to refine and contextualize these explanations. Subsequent customization for varied audiences and meticulous validation processes in an example illustrate the applicability and potential of this approach.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023



The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.
A negation detection assessment of GPTs: analysis with the xNot360 dataset
Jun 29, 2023



Negation is a fundamental aspect of natural language, playing a critical role in communication and comprehension. Our study assesses the negation detection performance of Generative Pre-trained Transformer (GPT) models, specifically GPT-2, GPT-3, GPT-3.5, and GPT-4. We focus on the identification of negation in natural language using a zero-shot prediction approach applied to our custom xNot360 dataset. Our approach examines sentence pairs labeled to indicate whether the second sentence negates the first. Our findings expose a considerable performance disparity among the GPT models, with GPT-4 surpassing its counterparts and GPT-3.5 displaying a marked performance reduction. The overall proficiency of the GPT models in negation detection remains relatively modest, indicating that this task pushes the boundaries of their natural language understanding capabilities. We not only highlight the constraints of GPT models in handling negation but also emphasize the importance of logical reliability in high-stakes domains such as healthcare, science, and law.
World of Bugs: A Platform for Automated Bug Detection in 3D Video Games
Jun 21, 2022

We present World of Bugs (WOB), an open platform that aims to support Automated Bug Detection (ABD) research in video games. We discuss some open problems in ABD and how they relate to the platform's design, arguing that learning-based solutions are required if further progress is to be made. The platform's key feature is a growing collection of common video game bugs that may be used for training and evaluating ABD approaches.
Learning to Identify Perceptual Bugs in 3D Video Games
Feb 25, 2022
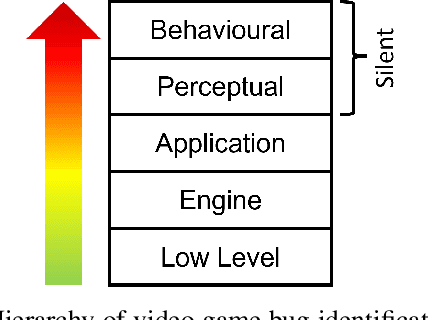


Automated Bug Detection (ABD) in video games is composed of two distinct but complementary problems: automated game exploration and bug identification. Automated game exploration has received much recent attention, spurred on by developments in fields such as reinforcement learning. The complementary problem of identifying the bugs present in a player's experience has for the most part relied on the manual specification of rules. Although it is widely recognised that many bugs of interest cannot be identified with such methods, little progress has been made in this direction. In this work we show that it is possible to identify a range of perceptual bugs using learning-based methods by making use of only the rendered game screen as seen by the player. To support our work, we have developed World of Bugs (WOB) an open platform for testing ABD methods in 3D game environments.