 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Strategy Templates using NLP Transformers
Nov 23, 2023This paper bridges the gap between mathematical heuristic strategies learned from Deep Reinforcement Learning (DRL) in automated agent negotiation, and comprehensible, natural language explanations. Our aim is to make these strategies more accessible to non-experts. By leveraging traditional Natural Language Processing (NLP) techniques and Large Language Models (LLMs) equipped with Transformers, we outline how parts of DRL strategies composed of parts within strategy templates can be transformed into user-friendly, human-like English narratives. To achieve this, we present a top-level algorithm that involves parsing mathematical expressions of strategy templates, semantically interpreting variables and structures, generating rule-based primary explanations, and utilizing a Generative Pre-trained Transformer (GPT) model to refine and contextualize these explanations. Subsequent customization for varied audiences and meticulous validation processes in an example illustrate the applicability and potential of this approach.
Learnable Strategies for Bilateral Agent Negotiation over Multiple Issues
Sep 17, 2020
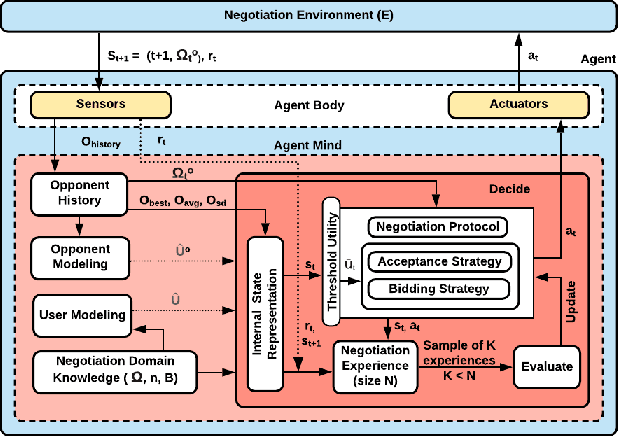
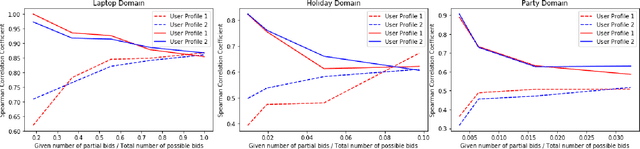
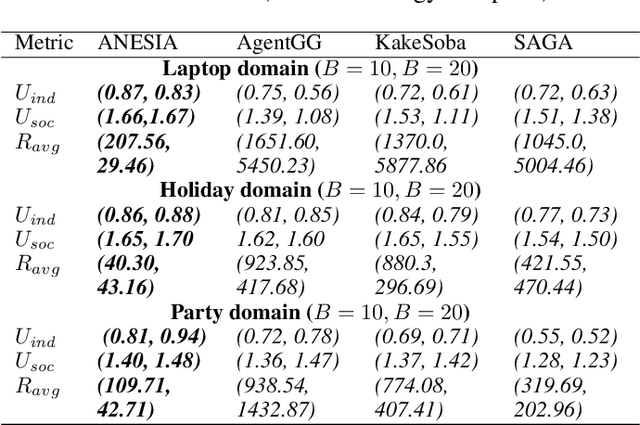
We present a novel bilateral negotiation model that allows a self-interested agent to learn how to negotiate over multiple issues in the presence of user preference uncertainty. The model relies upon interpretable strategy templates representing the tactics the agent should employ during the negotiation and learns template parameters to maximize the average utility received over multiple negotiations, thus resulting in optimal bid acceptance and generation. Our model also uses deep reinforcement learning to evaluate threshold utility values, for those tactics that require them, thereby deriving optimal utilities for every environment state. To handle user preference uncertainty, the model relies on a stochastic search to find user model that best agrees with a given partial preference profile. Multi-objective optimization and multi-criteria decision-making methods are applied at negotiation time to generate Pareto-optimal outcomes thereby increasing the number of successful (win-win) negotiations. Rigorous experimental evaluations show that the agent employing our model outperforms the winning agents of the 10th Automated Negotiating Agents Competition (ANAC'19) in terms of individual as well as social-welfare utilities.
A Deep Reinforcement Learning Approach to Concurrent Bilateral Negotiation
Feb 03, 2020
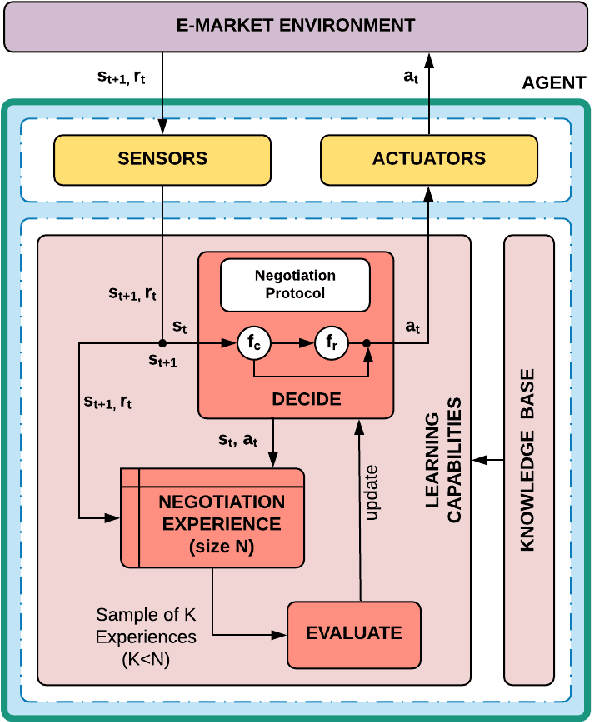

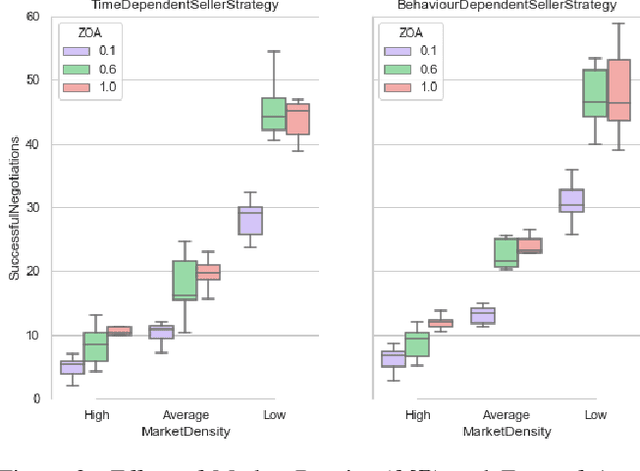
We present a novel negotiation model that allows an agent to learn how to negotiate during concurrent bilateral negotiations in unknown and dynamic e-markets. The agent uses an actor-critic architecture with model-free reinforcement learning to learn a strategy expressed as a deep neural network. We pre-train the strategy by supervision from synthetic market data, thereby decreasing the exploration time required for learning during negotiation. As a result, we can build automated agents for concurrent negotiations that can adapt to different e-market settings without the need to be pre-programmed. Our experimental evaluation shows that our deep reinforcement learning-based agents outperform two existing well-known negotiation strategies in one-to-many concurrent bilateral negotiations for a range of e-market settings.