 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF-Mamba: Rethinking State Space Model for Vision
Mar 17, 2026The realm of Mamba for vision has been advanced in recent years to strike for the alternatives of Vision Transformers (ViTs) that suffer from the quadratic complexity. While the recurrent scanning mechanism of Mamba offers computational efficiency, it inherently limits non-causal interactions between image patches. Prior works have attempted to address this limitation through various multi-scan strategies; however, these approaches suffer from inefficiencies due to suboptimal scan designs and frequent data rearrangement. Moreover, Mamba exhibits relatively slow computational speed under short token lengths, commonly used in visual tasks. In pursuit of a truly efficient vision encoder, we rethink the scan operation for vision and the computational efficiency of Mamba. To this end, we propose SF-Mamba, a novel visual Mamba with two key proposals: auxiliary patch swapping for encoding bidirectional information flow under an unidirectional scan and batch folding with periodic state reset for advanced GPU parallelism. Extensive experiments on image classification, object detection, and instance and semantic segmentation consistently demonstrate that our proposed SF-Mamba significantly outperforms state-of-the-art baselines while improving throughput across different model sizes. We will release the source code after publication.
MambaPEFT: Exploring Parameter-Efficient Fine-Tuning for Mamba
Nov 06, 2024An ecosystem of Transformer-based models has been established by building large models with extensive data. Parameter-efficient fine-tuning (PEFT) is a crucial technology for deploying these models to downstream tasks with minimal cost while achieving effective performance. Recently, Mamba, a State Space Model (SSM)-based model, has attracted attention as a potential alternative to Transformers. While many large-scale Mamba-based models have been proposed, efficiently adapting pre-trained Mamba-based models to downstream tasks remains unexplored. In this paper, we conduct an exploratory analysis of PEFT methods for Mamba. We investigate the effectiveness of existing PEFT methods for Transformers when applied to Mamba. We also modify these methods to better align with the Mamba architecture. Additionally, we propose new Mamba-specific PEFT methods that leverage the distinctive structure of Mamba. Our experiments indicate that PEFT performs more effectively for Mamba than Transformers. Lastly, we demonstrate how to effectively combine multiple PEFT methods and provide a framework that outperforms previous works. To ensure reproducibility, we will release the code after publication.
Metadata-based Data Exploration with Retrieval-Augmented Generation for Large Language Models
Oct 05, 2024



Developing the capacity to effectively search for requisite datasets is an urgent requirement to assist data users in identifying relevant datasets considering the very limited available metadata. For this challenge, the utilization of third-party data is emerging as a valuable source for improvement. Our research introduces a new architecture for data exploration which employs a form of Retrieval-Augmented Generation (RAG) to enhance metadata-based data discovery. The system integrates large language models (LLMs) with external vector databases to identify semantic relationships among diverse types of datasets. The proposed framework offers a new method for evaluating semantic similarity among heterogeneous data sources and for improving data exploration. Our study includes experimental results on four critical tasks: 1) recommending similar datasets, 2) suggesting combinable datasets, 3) estimating tags, and 4) predicting variables. Our results demonstrate that RAG can enhance the selection of relevant datasets, particularly from different categories, when compared to conventional metadata approaches. However, performance varied across tasks and models, which confirms the significance of selecting appropriate techniques based on specific use cases. The findings suggest that this approach holds promise for addressing challenges in data exploration and discovery, although further refinement is necessary for estimation tasks.
Extraction of Constituent Factors of Digestion Efficiency in Information Transfer by Media Composed of Texts and Images
Feb 17, 2023The development and spread of information and communication technologies have increased and diversified information. However, the increase in the volume and the selection of information does not necessarily promote understanding. In addition, conventional evaluations of information transfer have focused only on the arrival of information to the receivers. They need to sufficiently take into account the receivers' understanding of the information after it has been acquired, which is the original purpose of the evaluation. In this study, we propose the concept of "information digestion," which refers to the receivers' correct understanding of the acquired information, its contents, and its purpose. In the experiment, we proposed an evaluation model of information digestibility using hierarchical factor analysis and extracted factors that constitute digestibility by four types of media.
Feature Concepts for Data Federative Innovations
Nov 05, 2021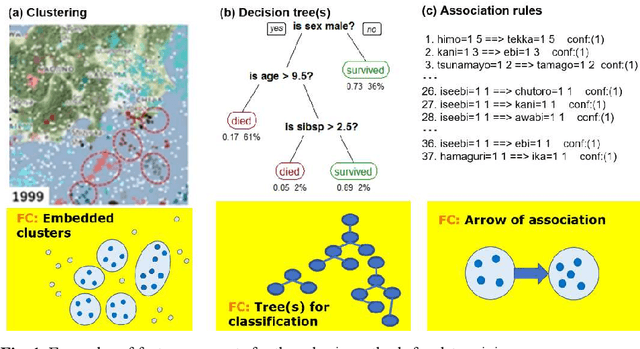
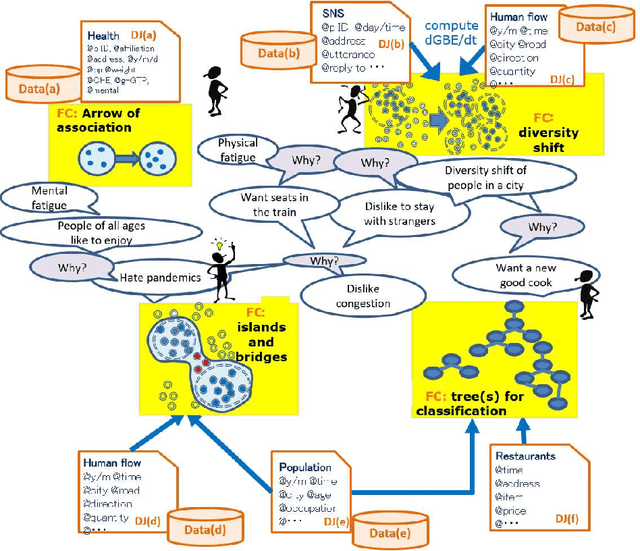
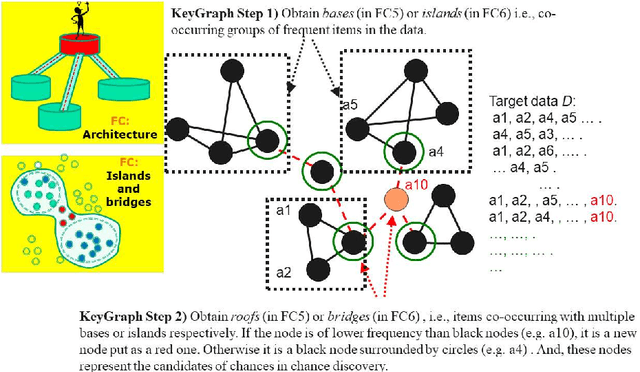
A feature concept, the essence of the data-federative innovation process, is presented as a model of the concept to be acquired from data. A feature concept may be a simple feature, such as a single variable, but is more likely to be a conceptual illustration of the abstract information to be obtained from the data. For example, trees and clusters are feature concepts for decision tree learning and clustering, respectively. Useful feature concepts for satis-fying the requirements of users of data have been elicited so far via creative communication among stakeholders in the market of data. In this short paper, such a creative communication is reviewed, showing a couple of appli-cations, for example, change explanation in markets and earthquakes, and highlight the feature concepts elicited in these cases.
Hierarchical entropy and domain interaction to understand the structure in an image
Apr 20, 2021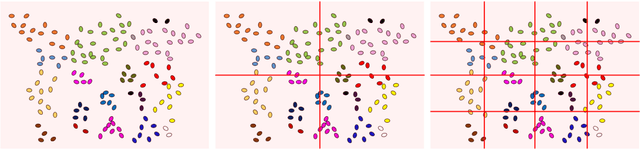
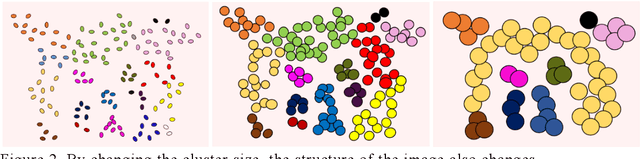
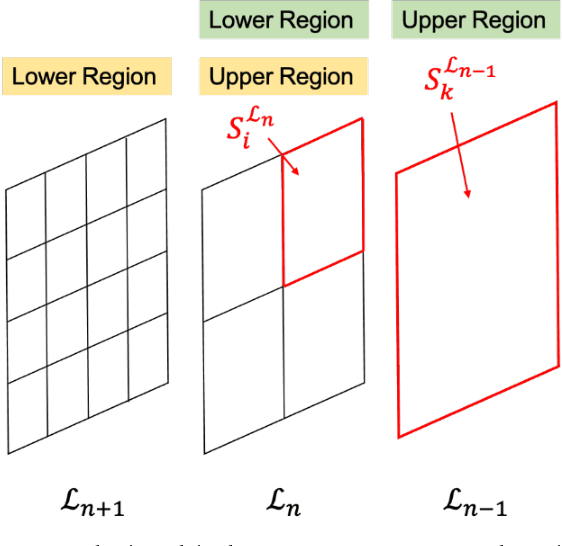
In this study, we devise a model that introduces two hierarchies into information entropy. The two hierarchies are the size of the region for which entropy is calculated and the size of the component that determines whether the structures in the image are integrated or not. And this model uses two indicators, hierarchical entropy and domain interaction. Both indicators increase or decrease due to the integration or fragmentation of the structure in the image. It aims to help people interpret and explain what the structure in an image looks like from two indicators that change with the size of the region and the component. First, we conduct experiments using images and qualitatively evaluate how the two indicators change. Next, we explain the relationship with the hidden structure of Vermeer's girl with a pearl earring using the change of hierarchical entropy. Finally, we clarify the relationship between the change of domain interaction and the appropriate segment result of the image by an experiment using a questionnaire.
Extracting and Validating Explanatory Word Archipelagoes using Dual Entropy
Feb 22, 2020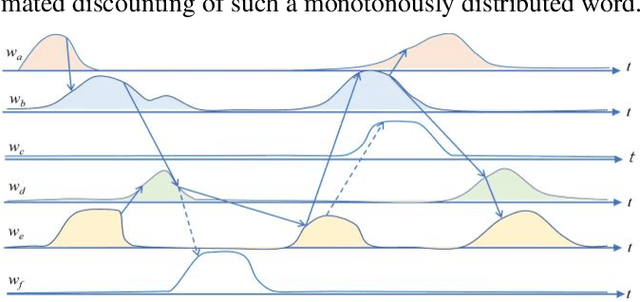
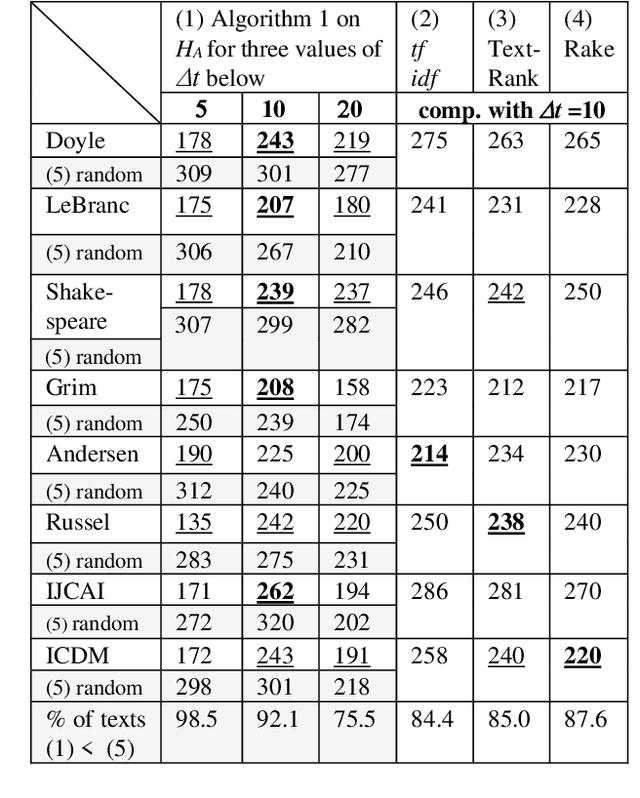
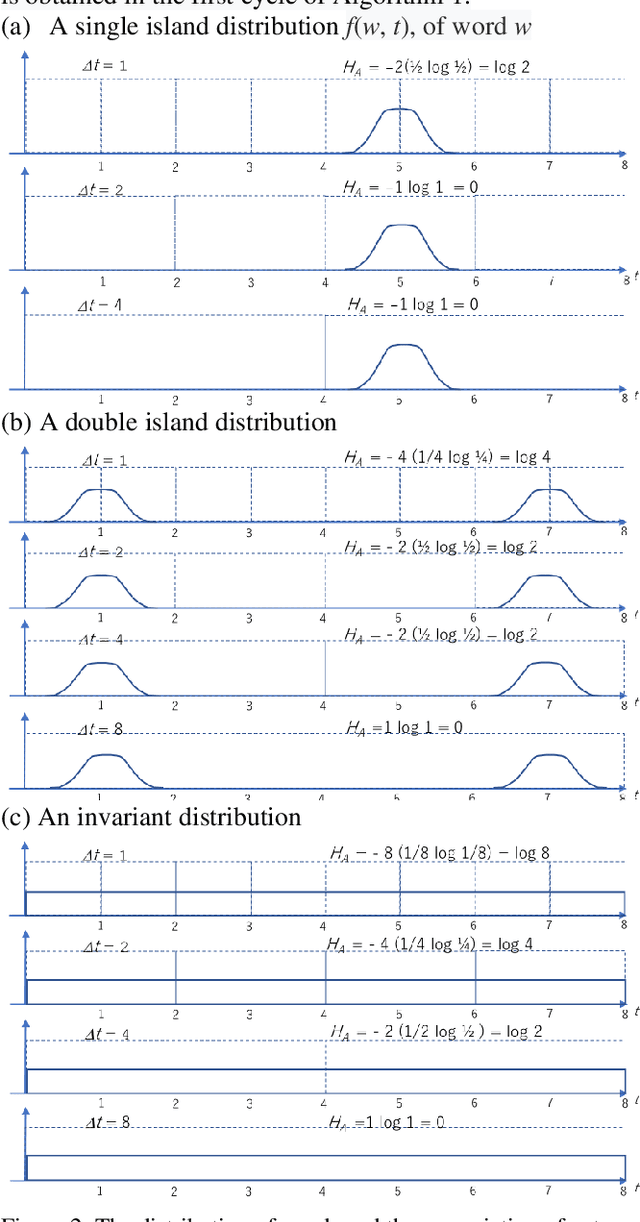
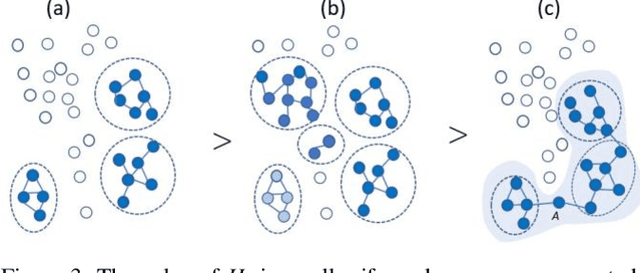
The logical connectivity of text is represented by the connectivity of words that form archipelagoes. Here, each archipelago is a sequence of islands of the occurrences of a certain word. An island here means the local sequence of sentences where the word is emphasized, and an archipelago of a length comparable to the target text is extracted using the co-variation of entropy A (the window-based entropy) on the distribution of the word's occurrences with the width of each time window. Then, the logical connectivity of text is evaluated on entropy B (the graph-based entropy) computed on the distribution of sentences to connected word-clusters obtained on the co-occurrence of words. The results show the parts of the target text with words forming archipelagoes extracted on entropy A, without learned or prepared knowledge, form an explanatory part of the text that is of smaller entropy B than the parts extracted by the baseline methods.