 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from A Rationalist: Distilling Intermediate Interpretable Rationales
Jan 30, 2026Because of the pervasive use of deep neural networks (DNNs), especially in high-stakes domains, the interpretability of DNNs has received increased attention. The general idea of rationale extraction (RE) is to provide an interpretable-by-design framework for DNNs via a select-predict architecture where two neural networks learn jointly to perform feature selection and prediction, respectively. Given only the remote supervision from the final task prediction, the process of learning to select subsets of features (or \emph{rationales}) requires searching in the space of all possible feature combinations, which is computationally challenging and even harder when the base neural networks are not sufficiently capable. To improve the predictive performance of RE models that are based on less capable or smaller neural networks (i.e., the students), we propose \textbf{REKD} (\textbf{R}ationale \textbf{E}xtraction with \textbf{K}nowledge \textbf{D}istillation) where a student RE model learns from the rationales and predictions of a teacher (i.e., a \emph{rationalist}) in addition to the student's own RE optimization. This structural adjustment to RE aligns well with how humans could learn effectively from interpretable and verifiable knowledge. Because of the neural-model agnostic nature of the method, any black-box neural network could be integrated as a backbone model. To demonstrate the viability of REKD, we conduct experiments with multiple variants of BERT and vision transformer (ViT) models. Our experiments across language and vision classification datasets (i.e., IMDB movie reviews, CIFAR 10 and CIFAR 100) show that REKD significantly improves the predictive performance of the student RE models.
Reason2Decide: Rationale-Driven Multi-Task Learning
Dec 23, 2025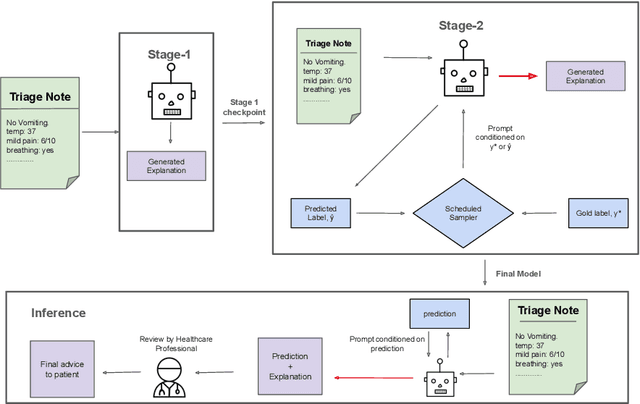


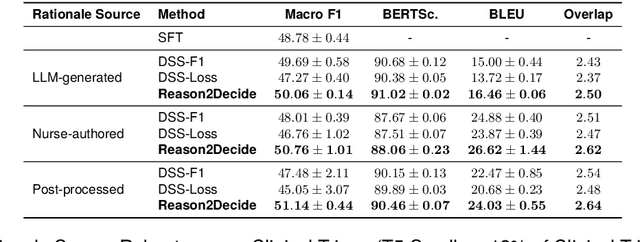
Despite the wide adoption of Large Language Models (LLM)s, clinical decision support systems face a critical challenge: achieving high predictive accuracy while generating explanations aligned with the predictions. Current approaches suffer from exposure bias leading to misaligned explanations. We propose Reason2Decide, a two-stage training framework that addresses key challenges in self-rationalization, including exposure bias and task separation. In Stage-1, our model is trained on rationale generation, while in Stage-2, we jointly train on label prediction and rationale generation, applying scheduled sampling to gradually transition from conditioning on gold labels to model predictions. We evaluate Reason2Decide on three medical datasets, including a proprietary triage dataset and public biomedical QA datasets. Across model sizes, Reason2Decide outperforms other fine-tuning baselines and some zero-shot LLMs in prediction (F1) and rationale fidelity (BERTScore, BLEU, LLM-as-a-Judge). In triage, Reason2Decide is rationale source-robust across LLM-generated, nurse-authored, and nurse-post-processed rationales. In our experiments, while using only LLM-generated rationales in Stage-1, Reason2Decide outperforms other fine-tuning variants. This indicates that LLM-generated rationales are suitable for pretraining models, reducing reliance on human annotations. Remarkably, Reason2Decide achieves these gains with models 40x smaller than contemporary foundation models, making clinical reasoning more accessible for resource-constrained deployments while still providing explainable decision support.
Metadata-based Data Exploration with Retrieval-Augmented Generation for Large Language Models
Oct 05, 2024



Developing the capacity to effectively search for requisite datasets is an urgent requirement to assist data users in identifying relevant datasets considering the very limited available metadata. For this challenge, the utilization of third-party data is emerging as a valuable source for improvement. Our research introduces a new architecture for data exploration which employs a form of Retrieval-Augmented Generation (RAG) to enhance metadata-based data discovery. The system integrates large language models (LLMs) with external vector databases to identify semantic relationships among diverse types of datasets. The proposed framework offers a new method for evaluating semantic similarity among heterogeneous data sources and for improving data exploration. Our study includes experimental results on four critical tasks: 1) recommending similar datasets, 2) suggesting combinable datasets, 3) estimating tags, and 4) predicting variables. Our results demonstrate that RAG can enhance the selection of relevant datasets, particularly from different categories, when compared to conventional metadata approaches. However, performance varied across tasks and models, which confirms the significance of selecting appropriate techniques based on specific use cases. The findings suggest that this approach holds promise for addressing challenges in data exploration and discovery, although further refinement is necessary for estimation tasks.