 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Incident Causal Factors and Preventive Measures Generation Using Tag-based Example Selection in Few-shot Learning
May 11, 2026In high-stakes domains such as healthcare, the reliability of Large Language Models (LLMs) is critical, particularly when generating clinical insights from incident reports. This study proposes a tag-based few-shot example selection method for prompting LLMs to generate background/causal factors and preventive measures from details of the medical incidents. For our experiments, we use the Japanese Medical Incident Dataset (JMID), a structured dataset of 3,884 real-world medical accident and near-miss reports. These reports are variably annotated with a wide range of tags--some include descriptive information (e.g., "medications," "blood transfusion therapy"). We compare three few-shot example selection strategies--random sampling, cosine similarity-based selection, and our proposed tag-based method--using GPT-4o and LLaMA 3.3. Results show that the tag-based approach achieves the highest precision and most stable generation behavior, while similarity-based selection often leads to unintended outputs and safety filter activation. These findings suggest that selecting examples based on human-interpretable dataset tags can improve generation precision and stability in clinical LLM applications.
Indexing Economic Fluctuation Narratives from Keiki Watchers Survey
Dec 02, 2024



In this paper, we design indices of economic fluctuation narratives derived from economic surveys. Companies, governments, and investors rely on key metrics like GDP and industrial production indices to predict economic trends. However, they have yet to effectively leverage the wealth of information contained in economic text, such as causal relationships, in their economic forecasting. Therefore, we design indices of economic fluctuation from economic surveys by using our previously proposed narrative framework. From the evaluation results, it is observed that the proposed indices had a stronger correlation with cumulative lagging diffusion index than other types of diffusion indices.
Knowledge Management for Automobile Failure Analysis Using Graph RAG
Nov 29, 2024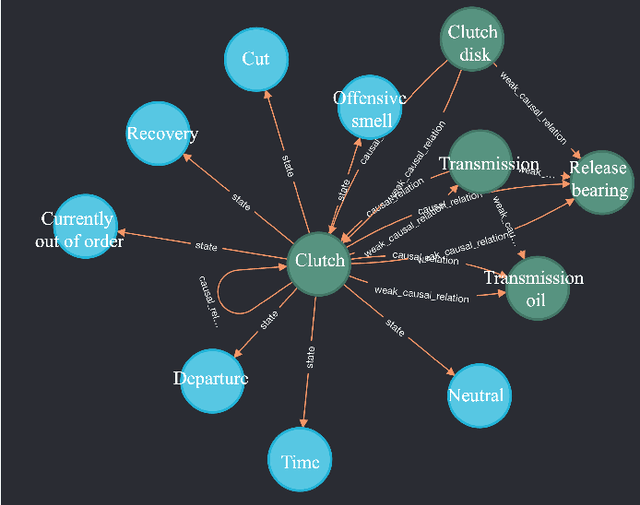
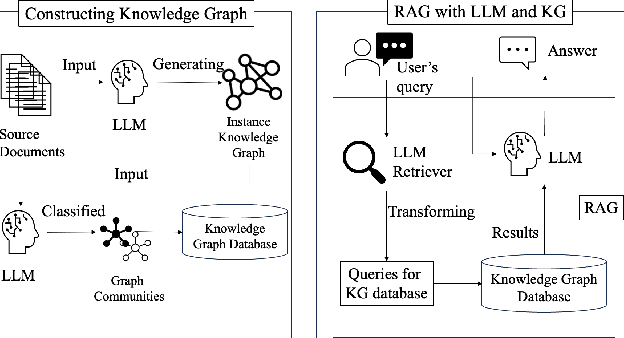
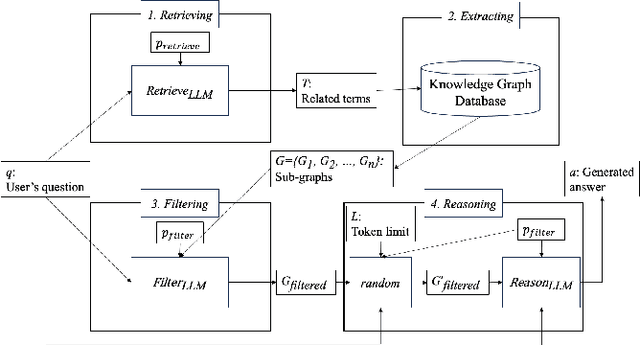
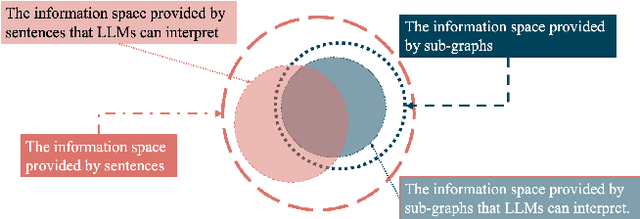
This paper presents a knowledge management system for automobile failure analysis using retrieval-augmented generation (RAG) with large language models (LLMs) and knowledge graphs (KGs). In the automotive industry, there is a growing demand for knowledge transfer of failure analysis from experienced engineers to young engineers. However, failure events are phenomena that occur in a chain reaction, making them difficult for beginners to analyze them. While knowledge graphs, which can describe semantic relationships and structure information is effective in representing failure events, due to their capability of representing the relationships between components, there is much information in KGs, so it is challenging for young engineers to extract and understand sub-graphs from the KG. On the other hand, there is increasing interest in the use of Graph RAG, a type of RAG that combines LLMs and KGs for knowledge management. However, when using the current Graph RAG framework with an existing knowledge graph for automobile failures, several issues arise because it is difficult to generate executable queries for a knowledge graph database which is not constructed by LLMs. To address this, we focused on optimizing the Graph RAG pipeline for existing knowledge graphs. Using an original Q&A dataset, the ROUGE F1 score of the sentences generated by the proposed method showed an average improvement of 157.6% compared to the current method. This highlights the effectiveness of the proposed method for automobile failure analysis.
Refined and Segmented Price Sentiment Indices from Survey Comments
Nov 15, 2024



We aim to enhance a price sentiment index and to more precisely understand price trends from the perspective of not only consumers but also businesses. We extract comments related to prices from the Economy Watchers Survey conducted by the Cabinet Office of Japan and classify price trends using a large language model (LLM). We classify whether the survey sample reflects the perspective of consumers or businesses, and whether the comments pertain to goods or services by utilizing information on the fields of comments and the industries of respondents included in the Economy Watchers Survey. From these classified price-related comments, we construct price sentiment indices not only for a general purpose but also for more specific objectives by combining perspectives on consumers and prices, as well as goods and services. It becomes possible to achieve a more accurate classification of price directions by employing a LLM for classification. Furthermore, integrating the outputs of multiple LLMs suggests the potential for the better performance of the classification. The use of more accurately classified comments allows for the construction of an index with a higher correlation to existing indices than previous studies. We demonstrate that the correlation of the price index for consumers, which has a larger sample size, is further enhanced by selecting comments for aggregation based on the industry of the survey respondents.
Enhancing Financial Domain Adaptation of Language Models via Model Augmentation
Nov 14, 2024


The domain adaptation of language models, including large language models (LLMs), has become increasingly important as the use of such models continues to expand. This study demonstrates the effectiveness of Composition to Augment Language Models (CALM) in adapting to the financial domain. CALM is a model to extend the capabilities of existing models by introducing cross-attention between two LLMs with different functions. In our experiments, we developed a CALM to enhance the financial performance of an LLM with strong response capabilities by leveraging a financial-specialized LLM. Notably, the CALM was trained using a financial dataset different from the one used to train the financial-specialized LLM, confirming CALM's ability to adapt to various datasets. The models were evaluated through quantitative Japanese financial benchmarks and qualitative response comparisons, demonstrating that CALM enables superior responses with higher scores than the original models and baselines. Additionally, comparative experiments on connection points revealed that connecting the middle layers of the models is most effective in facilitating adaptation to the financial domain. These findings confirm that CALM is a practical approach for adapting LLMs to the financial domain.
Metadata-based Data Exploration with Retrieval-Augmented Generation for Large Language Models
Oct 05, 2024



Developing the capacity to effectively search for requisite datasets is an urgent requirement to assist data users in identifying relevant datasets considering the very limited available metadata. For this challenge, the utilization of third-party data is emerging as a valuable source for improvement. Our research introduces a new architecture for data exploration which employs a form of Retrieval-Augmented Generation (RAG) to enhance metadata-based data discovery. The system integrates large language models (LLMs) with external vector databases to identify semantic relationships among diverse types of datasets. The proposed framework offers a new method for evaluating semantic similarity among heterogeneous data sources and for improving data exploration. Our study includes experimental results on four critical tasks: 1) recommending similar datasets, 2) suggesting combinable datasets, 3) estimating tags, and 4) predicting variables. Our results demonstrate that RAG can enhance the selection of relevant datasets, particularly from different categories, when compared to conventional metadata approaches. However, performance varied across tasks and models, which confirms the significance of selecting appropriate techniques based on specific use cases. The findings suggest that this approach holds promise for addressing challenges in data exploration and discovery, although further refinement is necessary for estimation tasks.
Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models
Aug 22, 2024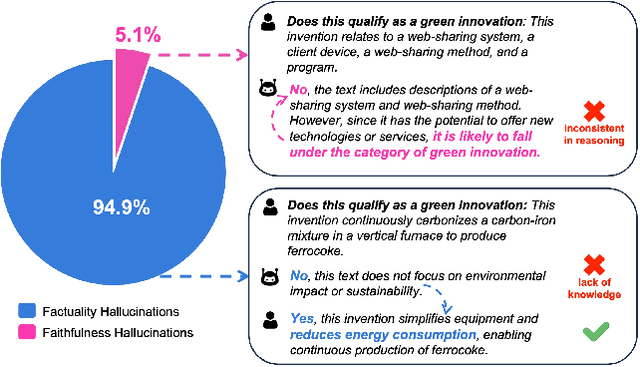

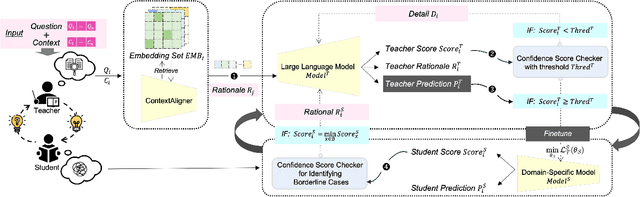
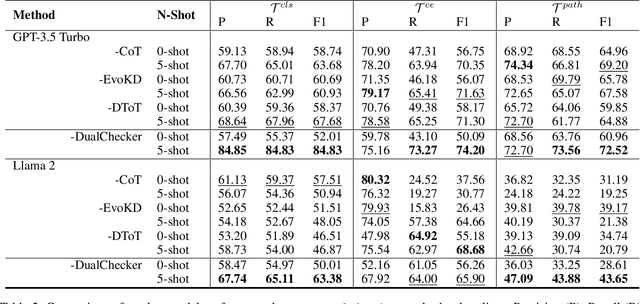
Large Language Models (LLMs) have demonstrated exceptional capabilities across various machine learning (ML) tasks. Given the high costs of creating annotated datasets for supervised learning, LLMs offer a valuable alternative by enabling effective few-shot in-context learning. However, these models can produce hallucinations, particularly in domains with incomplete knowledge. Additionally, current methods for knowledge distillation using LLMs often struggle to enhance the effectiveness of both teacher and student models. To address these challenges, we introduce DualChecker, an innovative framework designed to mitigate hallucinations and improve the performance of both teacher and student models during knowledge distillation. DualChecker employs ContextAligner to ensure that the context provided by teacher models aligns with human labeling standards. It also features a dynamic checker system that enhances model interaction: one component re-prompts teacher models with more detailed content when they show low confidence, and another identifies borderline cases from student models to refine the teaching templates. This interactive process promotes continuous improvement and effective knowledge transfer between the models. We evaluate DualChecker using a green innovation textual dataset that includes binary, multiclass, and token classification tasks. The experimental results show that DualChecker significantly outperforms existing state-of-the-art methods, achieving up to a 17% improvement in F1 score for teacher models and 10% for student models. Notably, student models fine-tuned with LLM predictions perform comparably to those fine-tuned with actual data, even in a challenging domain. We make all datasets, models, and code from this research publicly available.
SETN: Stock Embedding Enhanced with Textual and Network Information
Aug 06, 2024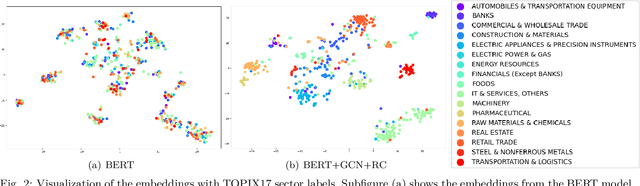
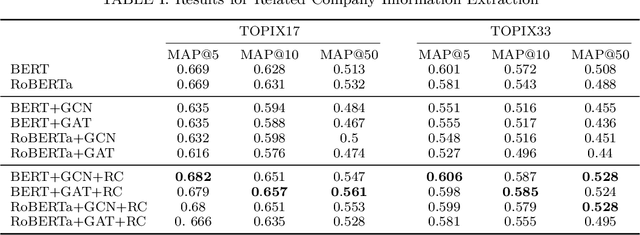
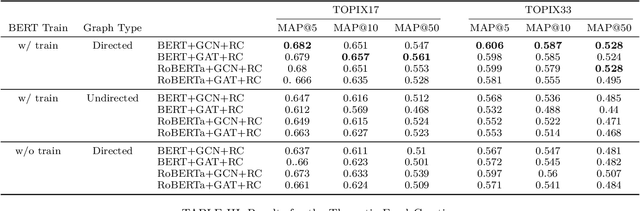
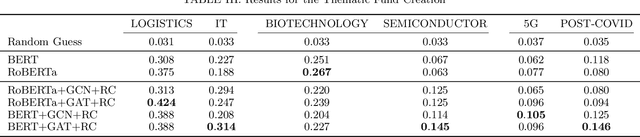
Stock embedding is a method for vector representation of stocks. There is a growing demand for vector representations of stock, i.e., stock embedding, in wealth management sectors, and the method has been applied to various tasks such as stock price prediction, portfolio optimization, and similar fund identifications. Stock embeddings have the advantage of enabling the quantification of relative relationships between stocks, and they can extract useful information from unstructured data such as text and network data. In this study, we propose stock embedding enhanced with textual and network information (SETN) using a domain-adaptive pre-trained transformer-based model to embed textual information and a graph neural network model to grasp network information. We evaluate the performance of our proposed model on related company information extraction tasks. We also demonstrate that stock embeddings obtained from the proposed model perform better in creating thematic funds than those obtained from baseline methods, providing a promising pathway for various applications in the wealth management industry.
Summarization of Investment Reports Using Pre-trained Model
Aug 03, 2024
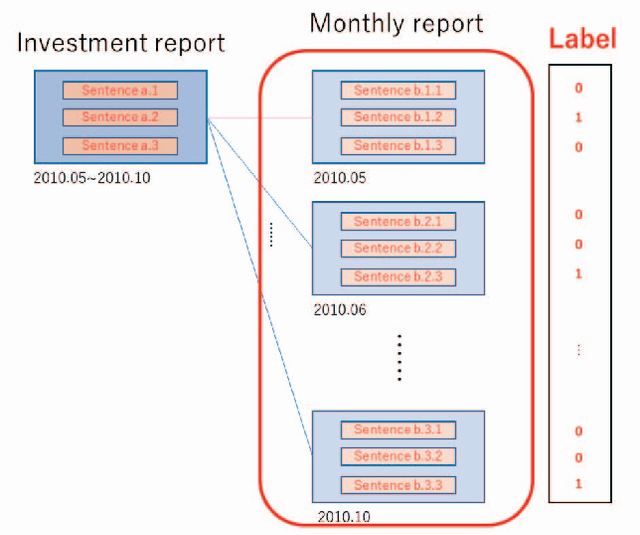
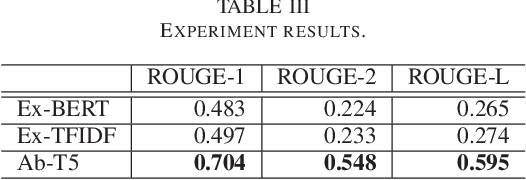

In this paper, we attempt to summarize monthly reports as investment reports. Fund managers have a wide range of tasks, one of which is the preparation of investment reports. In addition to preparing monthly reports on fund management, fund managers prepare management reports that summarize these monthly reports every six months or once a year. The preparation of fund reports is a labor-intensive and time-consuming task. Therefore, in this paper, we tackle investment summarization from monthly reports using transformer-based models. There are two main types of summarization methods: extractive summarization and abstractive summarization, and this study constructs both methods and examines which is more useful in summarizing investment reports.
Indexing and Visualization of Climate Change Narratives Using BERT and Causal Extraction
Aug 03, 2024In this study, we propose a methodology to extract, index, and visualize ``climate change narratives'' (stories about the connection between causal and consequential events related to climate change). We use two natural language processing methods, BERT (Bidirectional Encoder Representations from Transformers) and causal extraction, to textually analyze newspaper articles on climate change to extract ``climate change narratives.'' The novelty of the methodology could extract and quantify the causal relationships assumed by the newspaper's writers. Looking at the extracted climate change narratives over time, we find that since 2018, an increasing number of narratives suggest the impact of the development of climate change policy discussion and the implementation of climate change-related policies on corporate behaviors, macroeconomics, and price dynamics. We also observed the recent emergence of narratives focusing on the linkages between climate change-related policies and monetary policy. Furthermore, there is a growing awareness of the negative impacts of natural disasters (e.g., abnormal weather and severe floods) related to climate change on economic activities, and this issue might be perceived as a new challenge for companies and governments. The methodology of this study is expected to be applied to a wide range of fields, as it can analyze causal relationships among various economic topics, including analysis of inflation expectation or monetary policy communication strategy.