 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive DualChecker for Mitigating Hallucinations in Distilling Large Language Models
Paper and Code
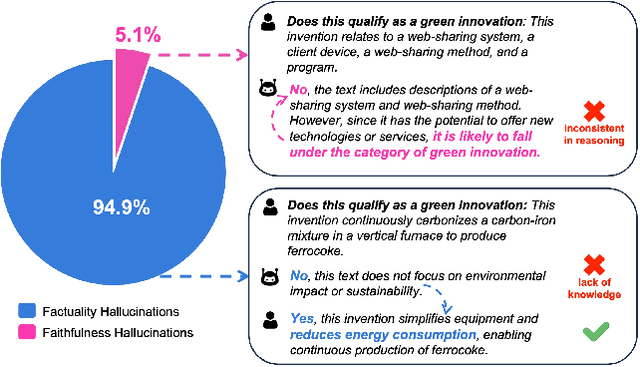

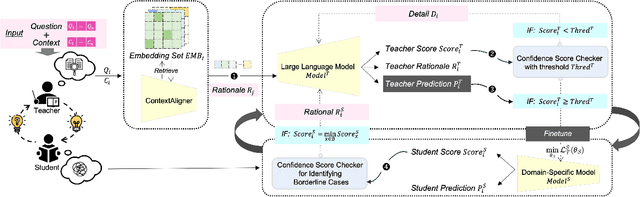
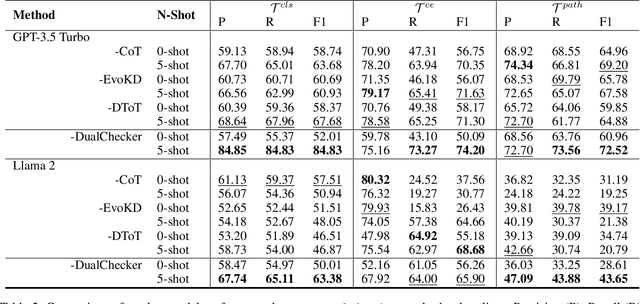
Large Language Models (LLMs) have demonstrated exceptional capabilities across various machine learning (ML) tasks. Given the high costs of creating annotated datasets for supervised learning, LLMs offer a valuable alternative by enabling effective few-shot in-context learning. However, these models can produce hallucinations, particularly in domains with incomplete knowledge. Additionally, current methods for knowledge distillation using LLMs often struggle to enhance the effectiveness of both teacher and student models. To address these challenges, we introduce DualChecker, an innovative framework designed to mitigate hallucinations and improve the performance of both teacher and student models during knowledge distillation. DualChecker employs ContextAligner to ensure that the context provided by teacher models aligns with human labeling standards. It also features a dynamic checker system that enhances model interaction: one component re-prompts teacher models with more detailed content when they show low confidence, and another identifies borderline cases from student models to refine the teaching templates. This interactive process promotes continuous improvement and effective knowledge transfer between the models. We evaluate DualChecker using a green innovation textual dataset that includes binary, multiclass, and token classification tasks. The experimental results show that DualChecker significantly outperforms existing state-of-the-art methods, achieving up to a 17% improvement in F1 score for teacher models and 10% for student models. Notably, student models fine-tuned with LLM predictions perform comparably to those fine-tuned with actual data, even in a challenging domain. We make all datasets, models, and code from this research publicly available.