 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
AdaRec: Adaptive Recommendation with LLMs via Narrative Profiling and Dual-Channel Reasoning
Nov 10, 2025We propose AdaRec, a few-shot in-context learning framework that leverages large language models for an adaptive personalized recommendation. AdaRec introduces narrative profiling, transforming user-item interactions into natural language representations to enable unified task handling and enhance human readability. Centered on a bivariate reasoning paradigm, AdaRec employs a dual-channel architecture that integrates horizontal behavioral alignment, discovering peer-driven patterns, with vertical causal attribution, highlighting decisive factors behind user preferences. Unlike existing LLM-based approaches, AdaRec eliminates manual feature engineering through semantic representations and supports rapid cross-task adaptation with minimal supervision. Experiments on real ecommerce datasets demonstrate that AdaRec outperforms both machine learning models and LLM-based baselines by up to eight percent in few-shot settings. In zero-shot scenarios, it achieves up to a nineteen percent improvement over expert-crafted profiling, showing effectiveness for long-tail personalization with minimal interaction data. Furthermore, lightweight fine-tuning on synthetic data generated by AdaRec matches the performance of fully fine-tuned models, highlighting its efficiency and generalization across diverse tasks.
Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models
Aug 22, 2024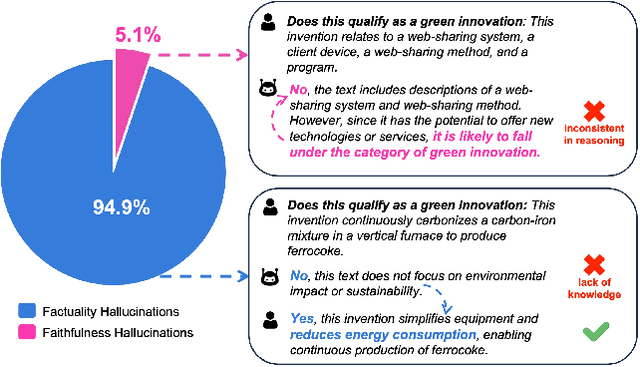

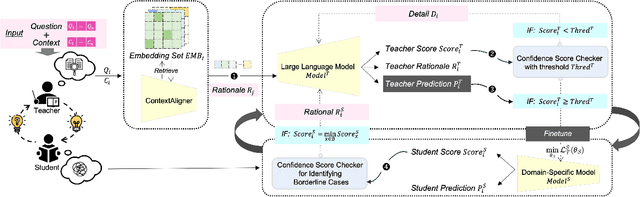
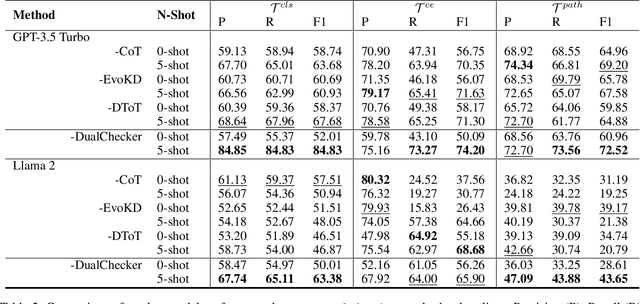
Large Language Models (LLMs) have demonstrated exceptional capabilities across various machine learning (ML) tasks. Given the high costs of creating annotated datasets for supervised learning, LLMs offer a valuable alternative by enabling effective few-shot in-context learning. However, these models can produce hallucinations, particularly in domains with incomplete knowledge. Additionally, current methods for knowledge distillation using LLMs often struggle to enhance the effectiveness of both teacher and student models. To address these challenges, we introduce DualChecker, an innovative framework designed to mitigate hallucinations and improve the performance of both teacher and student models during knowledge distillation. DualChecker employs ContextAligner to ensure that the context provided by teacher models aligns with human labeling standards. It also features a dynamic checker system that enhances model interaction: one component re-prompts teacher models with more detailed content when they show low confidence, and another identifies borderline cases from student models to refine the teaching templates. This interactive process promotes continuous improvement and effective knowledge transfer between the models. We evaluate DualChecker using a green innovation textual dataset that includes binary, multiclass, and token classification tasks. The experimental results show that DualChecker significantly outperforms existing state-of-the-art methods, achieving up to a 17% improvement in F1 score for teacher models and 10% for student models. Notably, student models fine-tuned with LLM predictions perform comparably to those fine-tuned with actual data, even in a challenging domain. We make all datasets, models, and code from this research publicly available.
LLMFactor: Extracting Profitable Factors through Prompts for Explainable Stock Movement Prediction
Jun 16, 2024



Recently, Large Language Models (LLMs) have attracted significant attention for their exceptional performance across a broad range of tasks, particularly in text analysis. However, the finance sector presents a distinct challenge due to its dependence on time-series data for complex forecasting tasks. In this study, we introduce a novel framework called LLMFactor, which employs Sequential Knowledge-Guided Prompting (SKGP) to identify factors that influence stock movements using LLMs. Unlike previous methods that relied on keyphrases or sentiment analysis, this approach focuses on extracting factors more directly related to stock market dynamics, providing clear explanations for complex temporal changes. Our framework directs the LLMs to create background knowledge through a fill-in-the-blank strategy and then discerns potential factors affecting stock prices from related news. Guided by background knowledge and identified factors, we leverage historical stock prices in textual format to predict stock movement. An extensive evaluation of the LLMFactor framework across four benchmark datasets from both the U.S. and Chinese stock markets demonstrates its superiority over existing state-of-the-art methods and its effectiveness in financial time-series forecasting.
FD-MAR: Fourier Dual-domain Network for CT Metal Artifact Reduction
Jul 24, 2022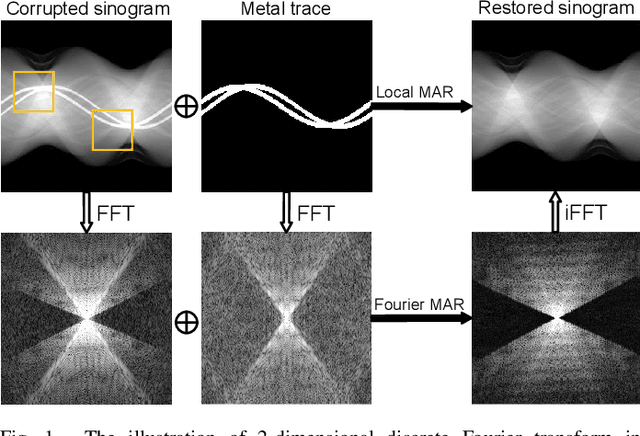
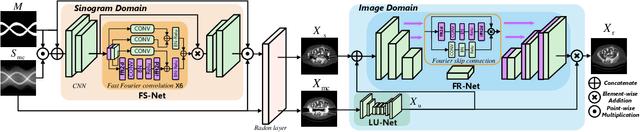
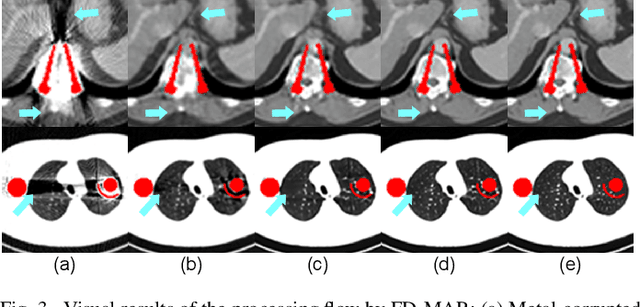
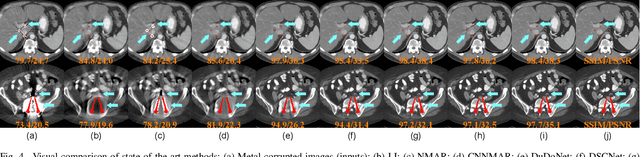
The presence of high-density objects such as metal implants and dental fillings can introduce severely streak-like artifacts in computed tomography (CT) images, greatly limiting subsequent diagnosis. Although various deep neural networks-based methods have been proposed for metal artifact reduction (MAR), they usually suffer from poor performance due to limited exploitation of global context in the sinogram domain, secondary artifacts introduced in the image domain, and the requirement of precise metal masks. To address these issues, this paper explores fast Fourier convolution for MAR in both sinogram and image domains, and proposes a Fourier dual-domain network for MAR, termed FD-MAR. Specifically, we first propose a Fourier sinogram restoration network, which can leverage sinogram-wide receptive context to fill in the metal-corrupted region from uncorrupted region and, hence, is robust to the metal trace. Second, we propose a Fourier refinement network in the image domain, which can refine the reconstructed images in a local-to-global manner by exploring image-wide context information. As a result, the proposed FD-MAR can explore the sinogram- and image-wide receptive fields for MAR. By optimizing FD-MAR with a composite loss function, extensive experimental results demonstrate the superiority of the proposed FD-MAR over the state-of-the-art MAR methods in terms of quantitative metrics and visual comparison. Notably, FD-MAR does not require precise metal masks, which is of great importance in clinical routine.
AIDE: Annotation-efficient deep learning for automatic medical image segmentation
Dec 14, 2020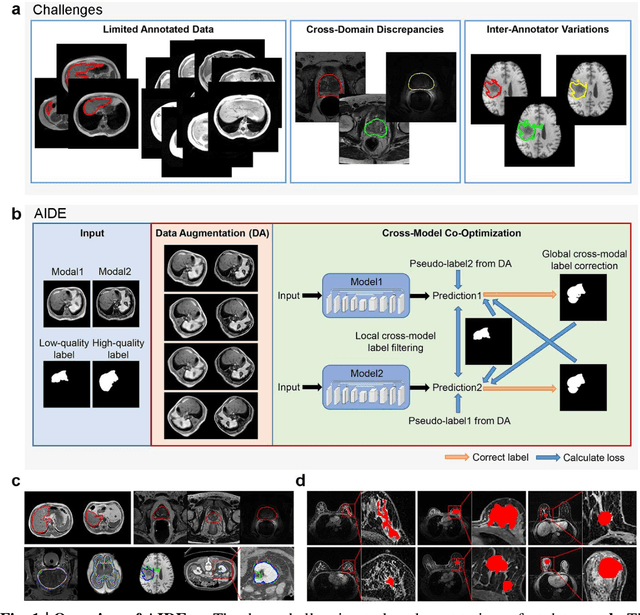
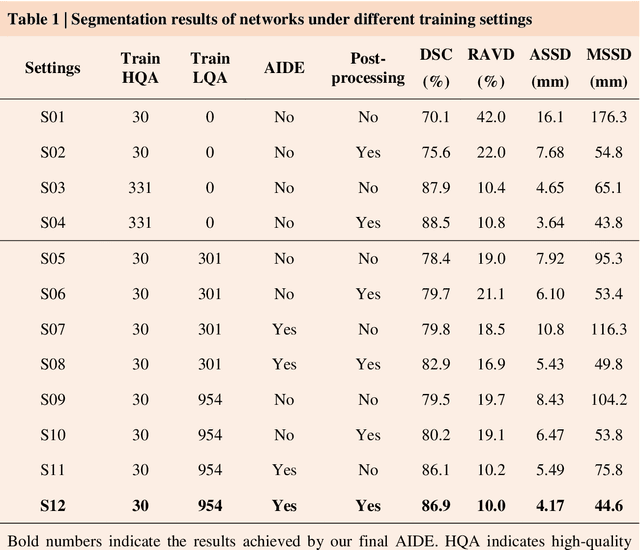
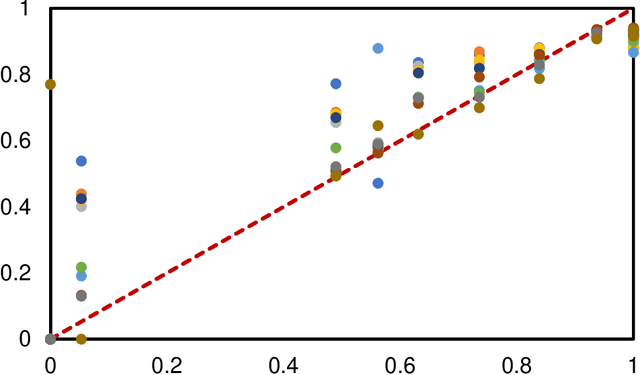
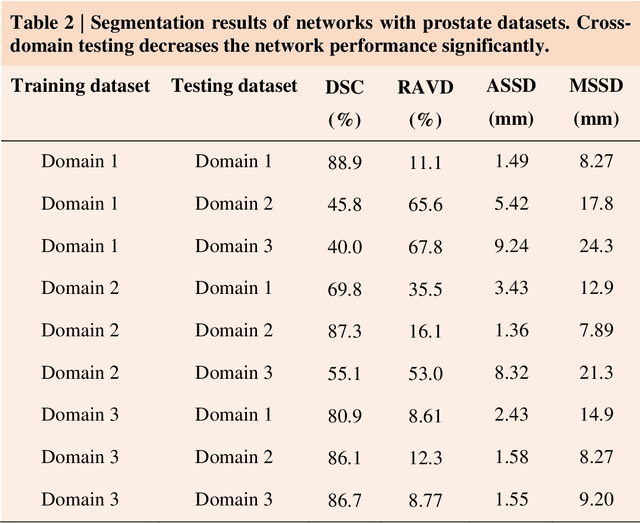
Accurate image segmentation is crucial for medical imaging applications. The prevailing deep learning approaches typically rely on very large training datasets with high-quality manual annotations, which are often not available in medical imaging. We introduce Annotation-effIcient Deep lEarning (AIDE) to handle imperfect datasets with an elaborately designed cross-model self-correcting mechanism. AIDE improves the segmentation Dice scores of conventional deep learning models on open datasets possessing scarce or noisy annotations by up to 30%. For three clinical datasets containing 11,852 breast images of 872 patients from three medical centers, AIDE consistently produces segmentation maps comparable to those generated by the fully supervised counterparts as well as the manual annotations of independent radiologists by utilizing only 10% training annotations. Such a 10-fold improvement of efficiency in utilizing experts' labels has the potential to promote a wide range of biomedical applications.
Robust breast cancer detection in mammography and digital breast tomosynthesis using annotation-efficient deep learning approach
Dec 27, 2019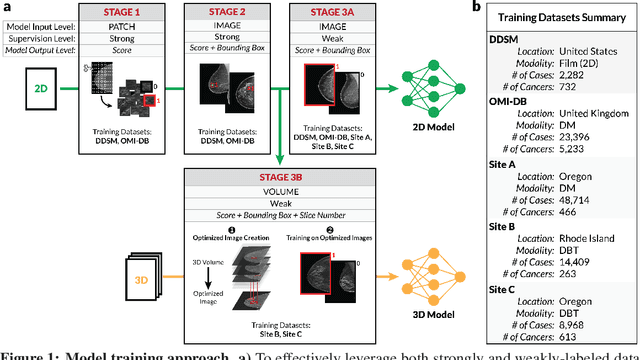
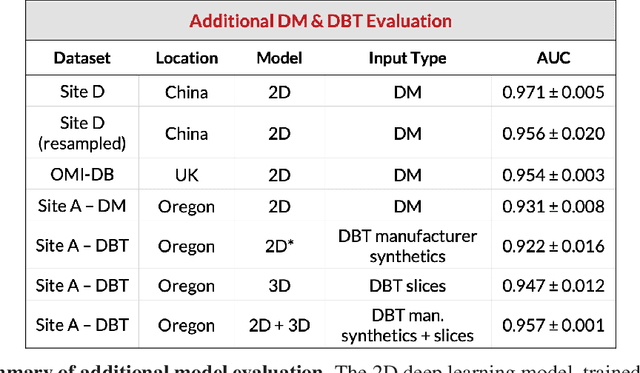
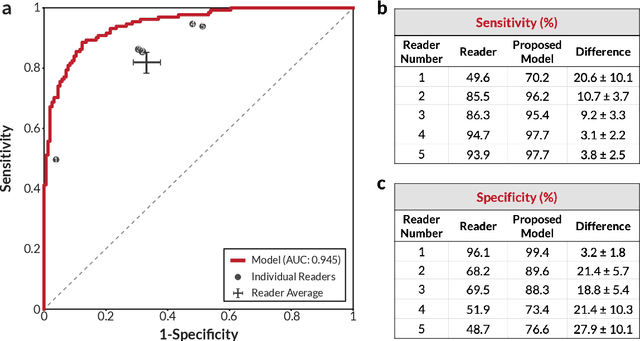
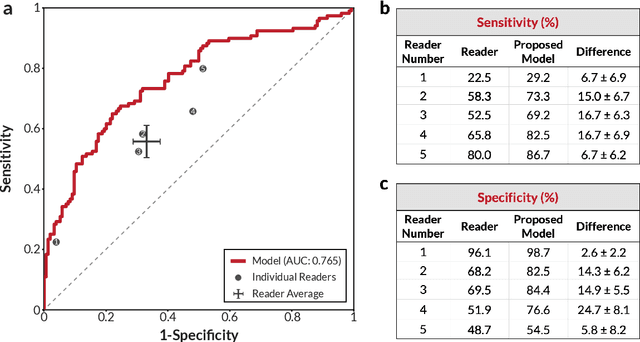
Breast cancer remains a global challenge, causing over 1 million deaths globally in 2018. To achieve earlier breast cancer detection, screening x-ray mammography is recommended by health organizations worldwide and has been estimated to decrease breast cancer mortality by 20-40%. Nevertheless, significant false positive and false negative rates, as well as high interpretation costs, leave opportunities for improving quality and access. To address these limitations, there has been much recent interest in applying deep learning to mammography; however, obtaining large amounts of annotated data poses a challenge for training deep learning models for this purpose, as does ensuring generalization beyond the populations represented in the training dataset. Here, we present an annotation-efficient deep learning approach that 1) achieves state-of-the-art performance in mammogram classification, 2) successfully extends to digital breast tomosynthesis (DBT; "3D mammography"), 3) detects cancers in clinically-negative prior mammograms of cancer patients, 4) generalizes well to a population with low screening rates, and 5) outperforms five-out-of-five full-time breast imaging specialists by improving absolute sensitivity by an average of 14%. Our results demonstrate promise towards software that can improve the accuracy of and access to screening mammography worldwide.
Validation of a deep learning mammography model in a population with low screening rates
Nov 01, 2019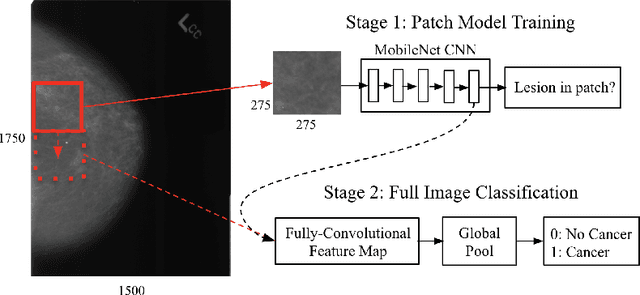
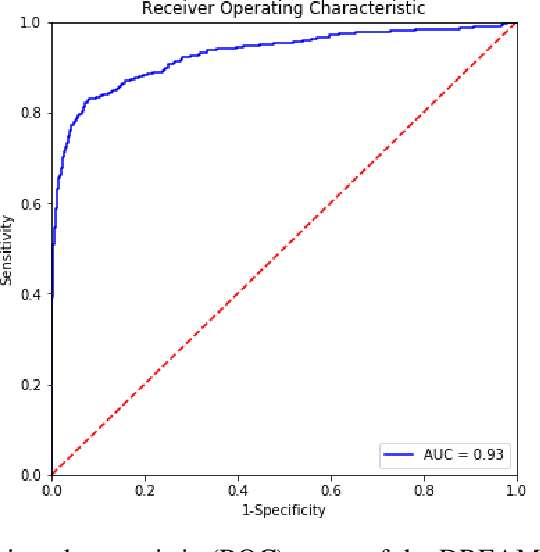
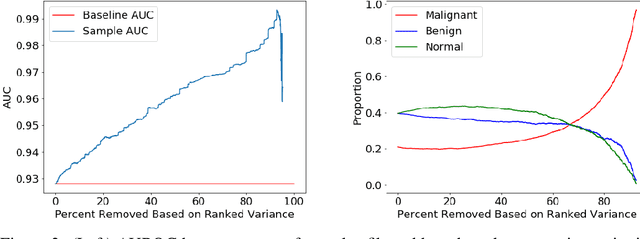
A key promise of AI applications in healthcare is in increasing access to quality medical care in under-served populations and emerging markets. However, deep learning models are often only trained on data from advantaged populations that have the infrastructure and resources required for large-scale data collection. In this paper, we aim to empirically investigate the potential impact of such biases on breast cancer detection in mammograms. We specifically explore how a deep learning algorithm trained on screening mammograms from the US and UK generalizes to mammograms collected at a hospital in China, where screening is not widely implemented. For the evaluation, we use a top-scoring model developed for the Digital Mammography DREAM Challenge. Despite the change in institution and population composition, we find that the model generalizes well, exhibiting similar performance to that achieved in the DREAM Challenge, even when controlling for tumor size. We also illustrate a simple but effective method for filtering predictions based on model variance, which can be particularly useful for deployment in new settings. While there are many components in developing a clinically effective system, these results represent a promising step towards increasing access to life-saving screening mammography in populations where screening rates are currently low.
Learning Cross-Modal Deep Representations for Multi-Modal MR Image Segmentation
Aug 06, 2019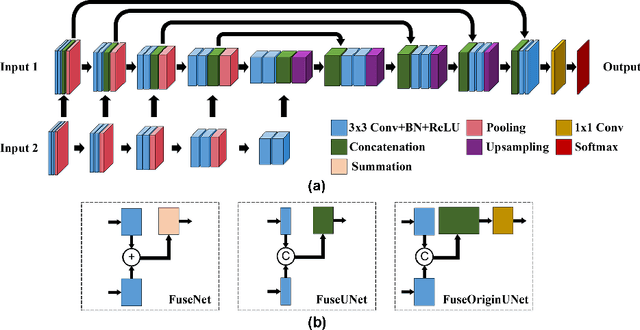
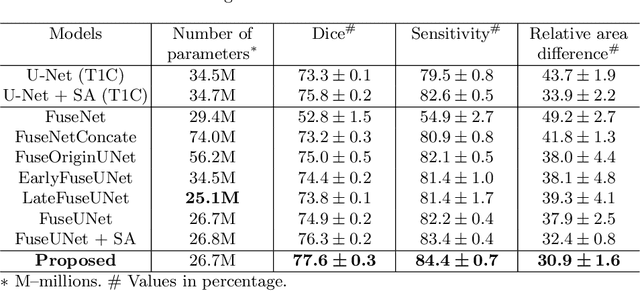

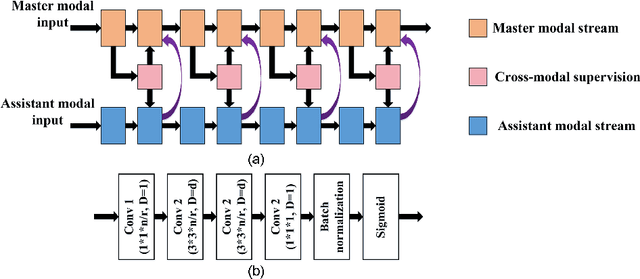
Multi-modal magnetic resonance imaging (MRI) is essential in clinics for comprehensive diagnosis and surgical planning. Nevertheless, the segmentation of multi-modal MR images tends to be time-consuming and challenging. Convolutional neural network (CNN)-based multi-modal MR image analysis commonly proceeds with multiple down-sampling streams fused at one or several layers. Although inspiring performance has been achieved, the feature fusion is usually conducted through simple summation or concatenation without optimization. In this work, we propose a supervised image fusion method to selectively fuse the useful information from different modalities and suppress the respective noise signals. Specifically, an attention block is introduced as guidance for the information selection. From the different modalities, one modality that contributes most to the results is selected as the master modality, which supervises the information selection of the other assistant modalities. The effectiveness of the proposed method is confirmed through breast mass segmentation in MR images of two modalities and better segmentation results are achieved compared to the state-of-the-art methods.
CLCI-Net: Cross-Level fusion and Context Inference Networks for Lesion Segmentation of Chronic Stroke
Jul 17, 2019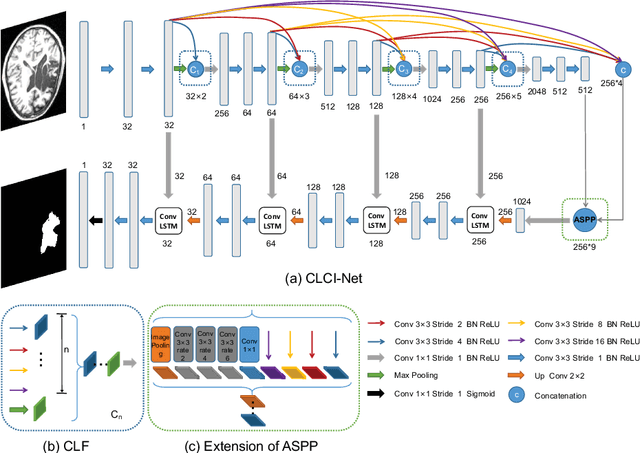
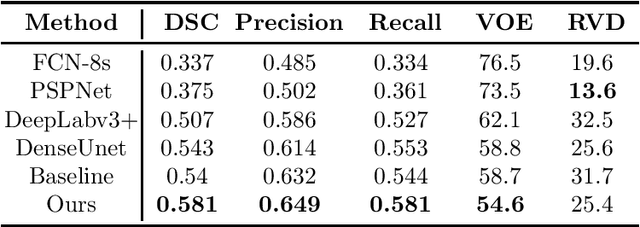
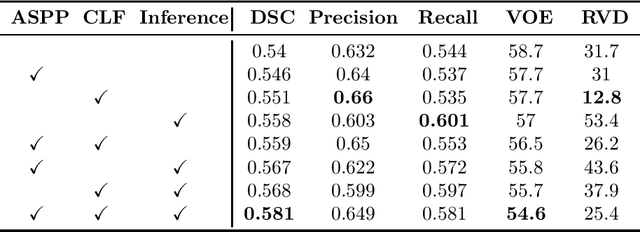
Segmenting stroke lesions from T1-weighted MR images is of great value for large-scale stroke rehabilitation neuroimaging analyses. Nevertheless, there are great challenges with this task, such as large range of stroke lesion scales and the tissue intensity similarity. The famous encoder-decoder convolutional neural network, which although has made great achievements in medical image segmentation areas, may fail to address these challenges due to the insufficient uses of multi-scale features and context information. To address these challenges, this paper proposes a Cross-Level fusion and Context Inference Network (CLCI-Net) for the chronic stroke lesion segmentation from T1-weighted MR images. Specifically, a Cross-Level feature Fusion (CLF) strategy was developed to make full use of different scale features across different levels; Extending Atrous Spatial Pyramid Pooling (ASPP) with CLF, we have enriched multi-scale features to handle the different lesion sizes; In addition, convolutional long short-term memory (ConvLSTM) is employed to infer context information and thus capture fine structures to address the intensity similarity issue. The proposed approach was evaluated on an open-source dataset, the Anatomical Tracings of Lesions After Stroke (ATLAS) with the results showing that our network outperforms five state-of-the-art methods. We make our code and models available at https://github.com/YH0517/CLCI_Net.