 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Pathology Foundation Models Encode Disease Progression? A Pseudotime Analysis of Visual Representations
Jan 29, 2026Vision foundation models trained on discretely sampled images achieve strong performance on classification benchmarks, yet whether their representations encode the continuous processes underlying their training data remains unclear. This question is especially pertinent in computational pathology, where we posit that models whose latent representations implicitly capture continuous disease progression may better reflect underlying biology, support more robust generalization, and enable quantitative analyses of features associated with disease transitions. Using diffusion pseudotime, a method developed to infer developmental trajectories from single-cell transcriptomics, we probe whether foundation models organize disease states along coherent progression directions in representation space. Across four cancer progressions and six models, we find that all pathology-specific models recover trajectory orderings significantly exceeding null baselines, with vision-only models achieving the highest fidelities $(τ> 0.78$ on CRC-Serrated). Model rankings by trajectory fidelity on reference diseases strongly predict few-shot classification performance on held-out diseases ($ρ= 0.92$), and exploratory analysis shows cell-type composition varies smoothly along inferred trajectories in patterns consistent with known stromal remodeling. Together, these results demonstrate that vision foundation models can implicitly learn to represent continuous processes from independent static observations, and that trajectory fidelity provides a complementary measure of representation quality beyond downstream performance. While demonstrated in pathology, this framework could be applied to other domains where continuous processes are observed through static snapshots.
Comparing Computational Pathology Foundation Models using Representational Similarity Analysis
Sep 18, 2025Foundation models are increasingly developed in computational pathology (CPath) given their promise in facilitating many downstream tasks. While recent studies have evaluated task performance across models, less is known about the structure and variability of their learned representations. Here, we systematically analyze the representational spaces of six CPath foundation models using techniques popularized in computational neuroscience. The models analyzed span vision-language contrastive learning (CONCH, PLIP, KEEP) and self-distillation (UNI (v2), Virchow (v2), Prov-GigaPath) approaches. Through representational similarity analysis using H&E image patches from TCGA, we find that UNI2 and Virchow2 have the most distinct representational structures, whereas Prov-Gigapath has the highest average similarity across models. Having the same training paradigm (vision-only vs. vision-language) did not guarantee higher representational similarity. The representations of all models showed a high slide-dependence, but relatively low disease-dependence. Stain normalization decreased slide-dependence for all models by a range of 5.5% (CONCH) to 20.5% (PLIP). In terms of intrinsic dimensionality, vision-language models demonstrated relatively compact representations, compared to the more distributed representations of vision-only models. These findings highlight opportunities to improve robustness to slide-specific features, inform model ensembling strategies, and provide insights into how training paradigms shape model representations. Our framework is extendable across medical imaging domains, where probing the internal representations of foundation models can help ensure effective development and deployment.
Simulating Clinical AI Assistance using Multimodal LLMs: A Case Study in Diabetic Retinopathy
Sep 16, 2025Diabetic retinopathy (DR) is a leading cause of blindness worldwide, and AI systems can expand access to fundus photography screening. Current FDA-cleared systems primarily provide binary referral outputs, where this minimal output may limit clinical trust and utility. Yet, determining the most effective output format to enhance clinician-AI performance is an empirical challenge that is difficult to assess at scale. We evaluated multimodal large language models (MLLMs) for DR detection and their ability to simulate clinical AI assistance across different output types. Two models were tested on IDRiD and Messidor-2: GPT-4o, a general-purpose MLLM, and MedGemma, an open-source medical model. Experiments included: (1) baseline evaluation, (2) simulated AI assistance with synthetic predictions, and (3) actual AI-to-AI collaboration where GPT-4o incorporated MedGemma outputs. MedGemma outperformed GPT-4o at baseline, achieving higher sensitivity and AUROC, while GPT-4o showed near-perfect specificity but low sensitivity. Both models adjusted predictions based on simulated AI inputs, but GPT-4o's performance collapsed with incorrect ones, whereas MedGemma remained more stable. In actual collaboration, GPT-4o achieved strong results when guided by MedGemma's descriptive outputs, even without direct image access (AUROC up to 0.96). These findings suggest MLLMs may improve DR screening pipelines and serve as scalable simulators for studying clinical AI assistance across varying output configurations. Open, lightweight models such as MedGemma may be especially valuable in low-resource settings, while descriptive outputs could enhance explainability and clinician trust in clinical workflows.
AdvDINO: Domain-Adversarial Self-Supervised Representation Learning for Spatial Proteomics
Aug 07, 2025Self-supervised learning (SSL) has emerged as a powerful approach for learning visual representations without manual annotations. However, the robustness of standard SSL methods to domain shift -- systematic differences across data sources -- remains uncertain, posing an especially critical challenge in biomedical imaging where batch effects can obscure true biological signals. We present AdvDINO, a domain-adversarial self-supervised learning framework that integrates a gradient reversal layer into the DINOv2 architecture to promote domain-invariant feature learning. Applied to a real-world cohort of six-channel multiplex immunofluorescence (mIF) whole slide images from non-small cell lung cancer patients, AdvDINO mitigates slide-specific biases to learn more robust and biologically meaningful representations than non-adversarial baselines. Across $>5.46$ million mIF image tiles, the model uncovers phenotype clusters with distinct proteomic profiles and prognostic significance, and improves survival prediction in attention-based multiple instance learning. While demonstrated on mIF data, AdvDINO is broadly applicable to other imaging domains -- including radiology, remote sensing, and autonomous driving -- where domain shift and limited annotated data hinder model generalization and interpretability.
Fluoroformer: Scaling multiple instance learning to multiplexed images via attention-based channel fusion
Nov 13, 2024
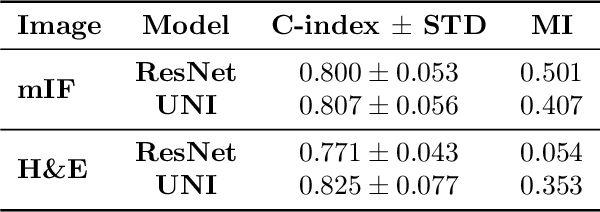

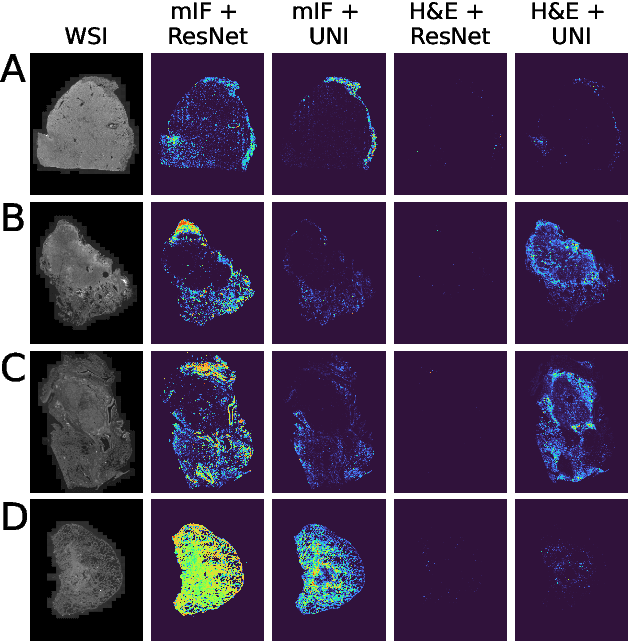
Though multiple instance learning (MIL) has been a foundational strategy in computational pathology for processing whole slide images (WSIs), current approaches are designed for traditional hematoxylin and eosin (H&E) slides rather than emerging multiplexed technologies. Here, we present an MIL strategy, the Fluoroformer module, that is specifically tailored to multiplexed WSIs by leveraging scaled dot-product attention (SDPA) to interpretably fuse information across disparate channels. On a cohort of 434 non-small cell lung cancer (NSCLC) samples, we show that the Fluoroformer both obtains strong prognostic performance and recapitulates immuno-oncological hallmarks of NSCLC. Our technique thereby provides a path for adapting state-of-the-art AI techniques to emerging spatial biology assays.
Representing visual classification as a linear combination of words
Nov 18, 2023



Explainability is a longstanding challenge in deep learning, especially in high-stakes domains like healthcare. Common explainability methods highlight image regions that drive an AI model's decision. Humans, however, heavily rely on language to convey explanations of not only "where" but "what". Additionally, most explainability approaches focus on explaining individual AI predictions, rather than describing the features used by an AI model in general. The latter would be especially useful for model and dataset auditing, and potentially even knowledge generation as AI is increasingly being used in novel tasks. Here, we present an explainability strategy that uses a vision-language model to identify language-based descriptors of a visual classification task. By leveraging a pre-trained joint embedding space between images and text, our approach estimates a new classification task as a linear combination of words, resulting in a weight for each word that indicates its alignment with the vision-based classifier. We assess our approach using two medical imaging classification tasks, where we find that the resulting descriptors largely align with clinical knowledge despite a lack of domain-specific language training. However, our approach also identifies the potential for 'shortcut connections' in the public datasets used. Towards a functional measure of explainability, we perform a pilot reader study where we find that the AI-identified words can enable non-expert humans to perform a specialized medical task at a non-trivial level. Altogether, our results emphasize the potential of using multimodal foundational models to deliver intuitive, language-based explanations of visual tasks.
Synthesizing lesions using contextual GANs improves breast cancer classification on mammograms
May 29, 2020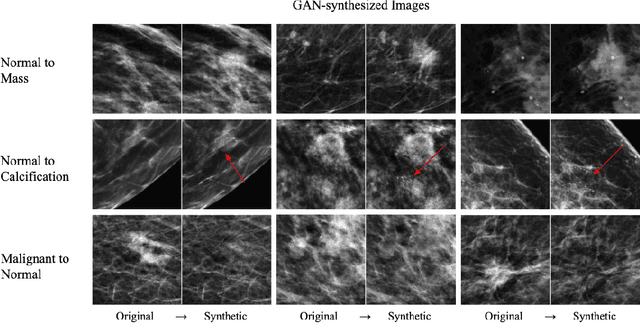
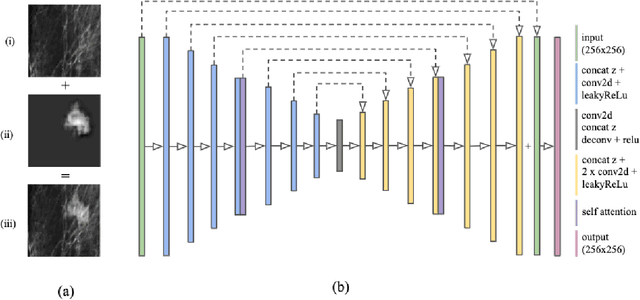
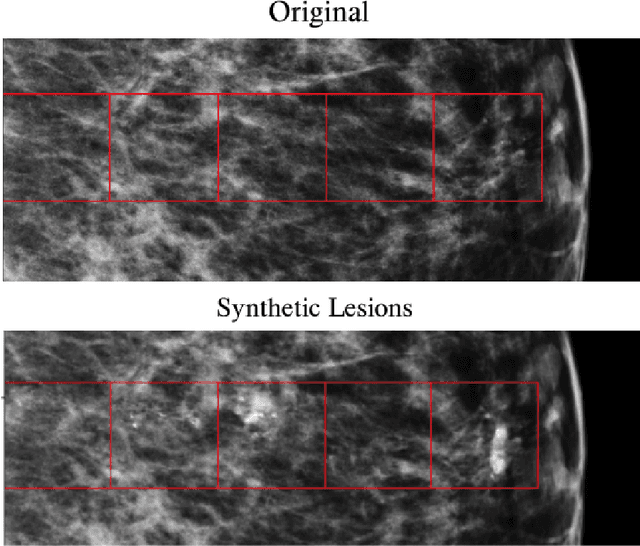
Data scarcity and class imbalance are two fundamental challenges in many machine learning applications to healthcare. Breast cancer classification in mammography exemplifies these challenges, with a malignancy rate of around 0.5% in a screening population, which is compounded by the relatively small size of lesions (~1% of the image) in malignant cases. Simultaneously, the prevalence of screening mammography creates a potential abundance of non-cancer exams to use for training. Altogether, these characteristics lead to overfitting on cancer cases, while under-utilizing non-cancer data. Here, we present a novel generative adversarial network (GAN) model for data augmentation that can realistically synthesize and remove lesions on mammograms. With self-attention and semi-supervised learning components, the U-net-based architecture can generate high resolution (256x256px) outputs, as necessary for mammography. When augmenting the original training set with the GAN-generated samples, we find a significant improvement in malignancy classification performance on a test set of real mammogram patches. Overall, the empirical results of our algorithm and the relevance to other medical imaging paradigms point to potentially fruitful further applications.
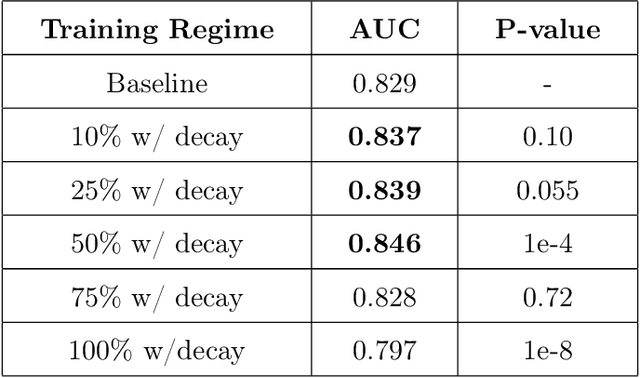
Robust breast cancer detection in mammography and digital breast tomosynthesis using annotation-efficient deep learning approach
Dec 27, 2019
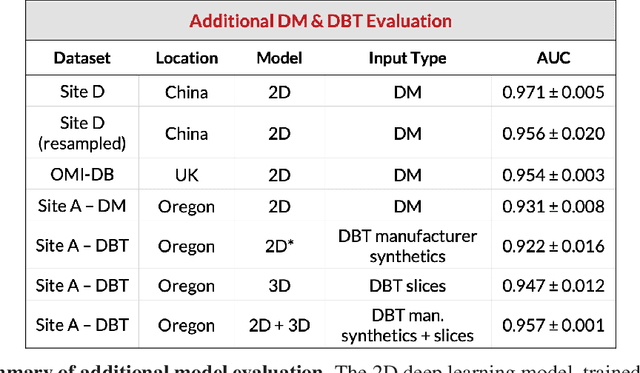
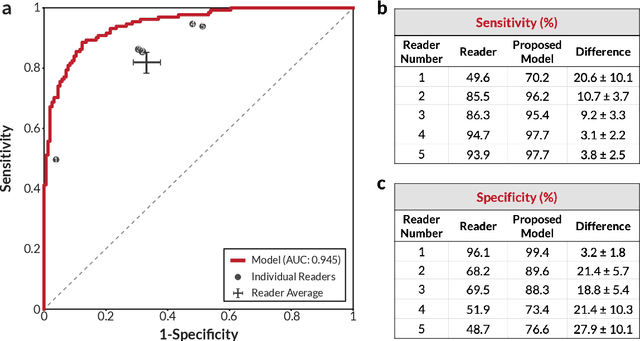
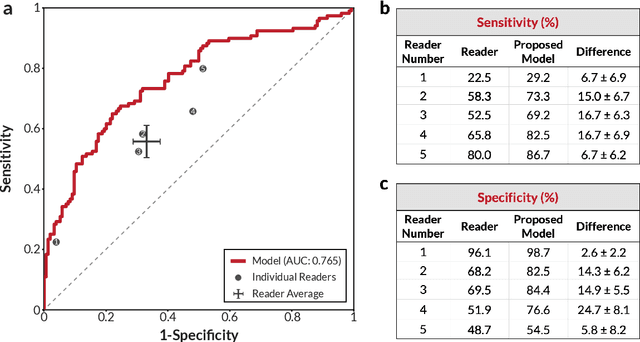
Breast cancer remains a global challenge, causing over 1 million deaths globally in 2018. To achieve earlier breast cancer detection, screening x-ray mammography is recommended by health organizations worldwide and has been estimated to decrease breast cancer mortality by 20-40%. Nevertheless, significant false positive and false negative rates, as well as high interpretation costs, leave opportunities for improving quality and access. To address these limitations, there has been much recent interest in applying deep learning to mammography; however, obtaining large amounts of annotated data poses a challenge for training deep learning models for this purpose, as does ensuring generalization beyond the populations represented in the training dataset. Here, we present an annotation-efficient deep learning approach that 1) achieves state-of-the-art performance in mammogram classification, 2) successfully extends to digital breast tomosynthesis (DBT; "3D mammography"), 3) detects cancers in clinically-negative prior mammograms of cancer patients, 4) generalizes well to a population with low screening rates, and 5) outperforms five-out-of-five full-time breast imaging specialists by improving absolute sensitivity by an average of 14%. Our results demonstrate promise towards software that can improve the accuracy of and access to screening mammography worldwide.
Conditional Infilling GANs for Data Augmentation in Mammogram Classification
Aug 24, 2018
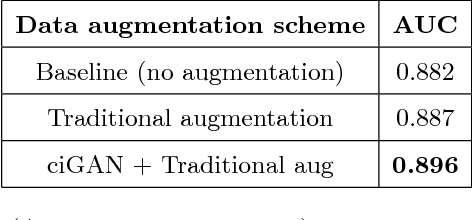
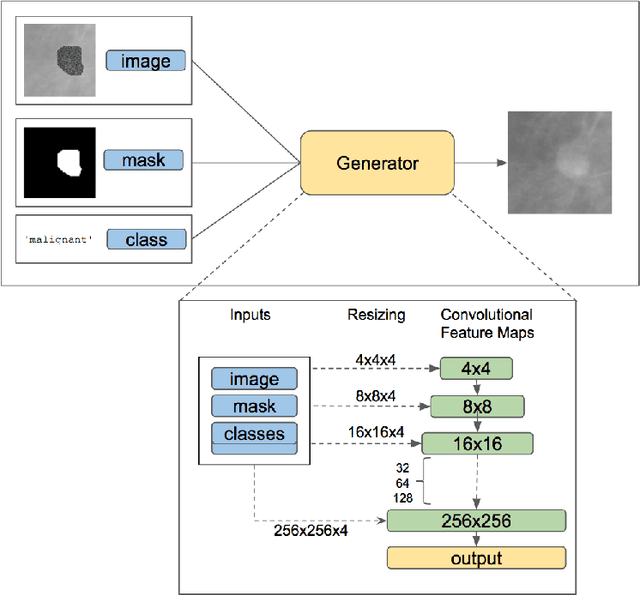
Deep learning approaches to breast cancer detection in mammograms have recently shown promising results. However, such models are constrained by the limited size of publicly available mammography datasets, in large part due to privacy concerns and the high cost of generating expert annotations. Limited dataset size is further exacerbated by substantial class imbalance since "normal" images dramatically outnumber those with findings. Given the rapid progress of generative models in synthesizing realistic images, and the known effectiveness of simple data augmentation techniques (e.g. horizontal flipping), we ask if it is possible to synthetically augment mammogram datasets using generative adversarial networks (GANs). We train a class-conditional GAN to perform contextual in-filling, which we then use to synthesize lesions onto healthy screening mammograms. First, we show that GANs are capable of generating high-resolution synthetic mammogram patches. Next, we experimentally evaluate using the augmented dataset to improve breast cancer classification performance. We observe that a ResNet-50 classifier trained with GAN-augmented training data produces a higher AUROC compared to the same model trained only on traditionally augmented data, demonstrating the potential of our approach.
A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception
May 30, 2018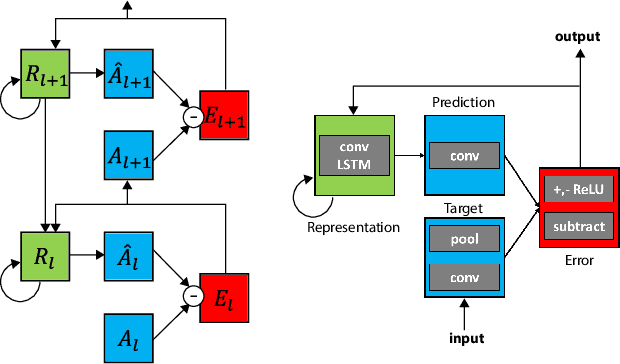

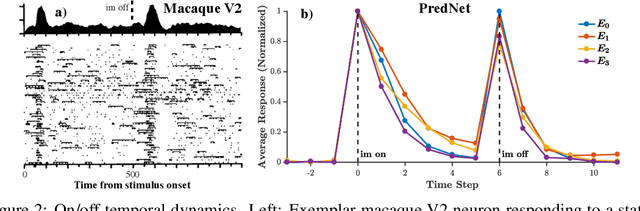

While deep neural networks take loose inspiration from neuroscience, it is an open question how seriously to take the analogies between artificial deep networks and biological neuronal systems. Interestingly, recent work has shown that deep convolutional neural networks (CNNs) trained on large-scale image recognition tasks can serve as strikingly good models for predicting the responses of neurons in visual cortex to visual stimuli, suggesting that analogies between artificial and biological neural networks may be more than superficial. However, while CNNs capture key properties of the average responses of cortical neurons, they fail to explain other properties of these neurons. For one, CNNs typically require large quantities of labeled input data for training. Our own brains, in contrast, rarely have access to this kind of supervision, so to the extent that representations are similar between CNNs and brains, this similarity must arise via different training paths. In addition, neurons in visual cortex produce complex time-varying responses even to static inputs, and they dynamically tune themselves to temporal regularities in the visual environment. We argue that these differences are clues to fundamental differences between the computations performed in the brain and in deep networks. To begin to close the gap, here we study the emergent properties of a previously-described recurrent generative network that is trained to predict future video frames in a self-supervised manner. Remarkably, the model is able to capture a wide variety of seemingly disparate phenomena observed in visual cortex, ranging from single unit response dynamics to complex perceptual motion illusions. These results suggest potentially deep connections between recurrent predictive neural network models and the brain, providing new leads that can enrich both fields.