 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception
Paper and Code
May 30, 2018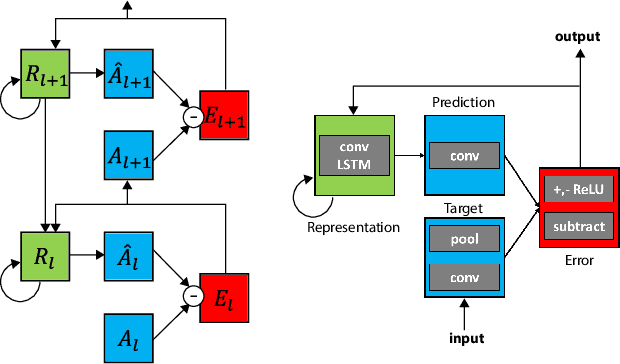

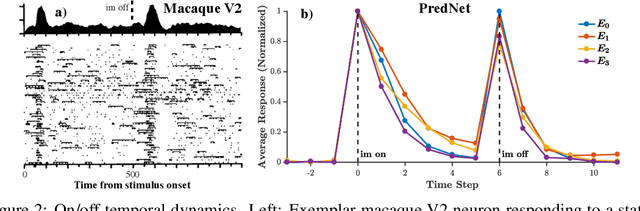

While deep neural networks take loose inspiration from neuroscience, it is an open question how seriously to take the analogies between artificial deep networks and biological neuronal systems. Interestingly, recent work has shown that deep convolutional neural networks (CNNs) trained on large-scale image recognition tasks can serve as strikingly good models for predicting the responses of neurons in visual cortex to visual stimuli, suggesting that analogies between artificial and biological neural networks may be more than superficial. However, while CNNs capture key properties of the average responses of cortical neurons, they fail to explain other properties of these neurons. For one, CNNs typically require large quantities of labeled input data for training. Our own brains, in contrast, rarely have access to this kind of supervision, so to the extent that representations are similar between CNNs and brains, this similarity must arise via different training paths. In addition, neurons in visual cortex produce complex time-varying responses even to static inputs, and they dynamically tune themselves to temporal regularities in the visual environment. We argue that these differences are clues to fundamental differences between the computations performed in the brain and in deep networks. To begin to close the gap, here we study the emergent properties of a previously-described recurrent generative network that is trained to predict future video frames in a self-supervised manner. Remarkably, the model is able to capture a wide variety of seemingly disparate phenomena observed in visual cortex, ranging from single unit response dynamics to complex perceptual motion illusions. These results suggest potentially deep connections between recurrent predictive neural network models and the brain, providing new leads that can enrich both fields.