 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling the geometry of visual relational reasoning
Feb 24, 2025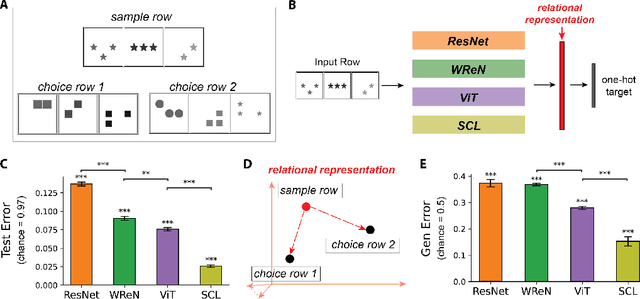

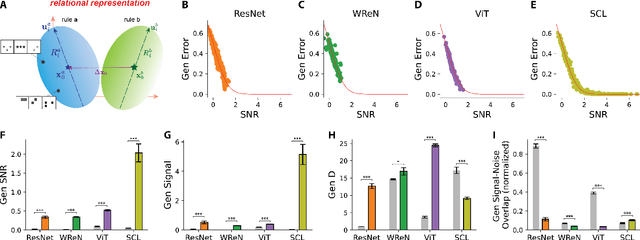
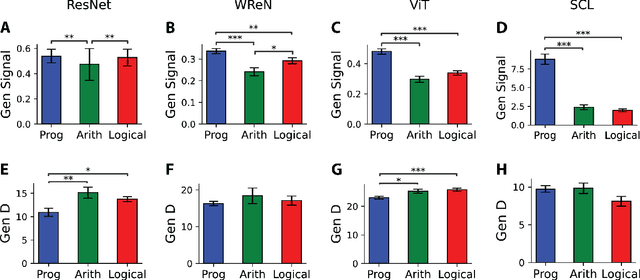
Humans and other animals readily generalize abstract relations, such as recognizing constant in shape or color, whereas neural networks struggle. To investigate how neural networks generalize abstract relations, we introduce SimplifiedRPM, a novel benchmark for systematic evaluation. In parallel, we conduct human experiments to benchmark relational difficulty, enabling direct model-human comparisons. Testing four architectures--ResNet-50, Vision Transformer, Wild Relation Network, and Scattering Compositional Learner (SCL)--we find that SCL best aligns with human behavior and generalizes best. Building on a geometric theory of neural representations, we show representational geometries that predict generalization. Layer-wise analysis reveals distinct relational reasoning strategies across models and suggests a trade-off where unseen rule representations compress into training-shaped subspaces. Guided by our geometric perspective, we propose and evaluate SNRloss, a novel objective balancing representation geometry. Our findings offer geometric insights into how neural networks generalize abstract relations, paving the way for more human-like visual reasoning in AI.
L-WISE: Boosting Human Image Category Learning Through Model-Based Image Selection And Enhancement
Dec 12, 2024


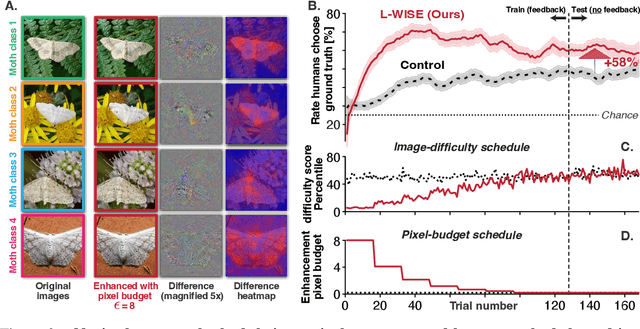
The currently leading artificial neural network (ANN) models of the visual ventral stream -- which are derived from a combination of performance optimization and robustification methods -- have demonstrated a remarkable degree of behavioral alignment with humans on visual categorization tasks. Extending upon previous work, we show that not only can these models guide image perturbations that change the induced human category percepts, but they also can enhance human ability to accurately report the original ground truth. Furthermore, we find that the same models can also be used out-of-the-box to predict the proportion of correct human responses to individual images, providing a simple, human-aligned estimator of the relative difficulty of each image. Motivated by these observations, we propose to augment visual learning in humans in a way that improves human categorization accuracy at test time. Our learning augmentation approach consists of (i) selecting images based on their model-estimated recognition difficulty, and (ii) using image perturbations that aid recognition for novice learners. We find that combining these model-based strategies gives rise to test-time categorization accuracy gains of 33-72% relative to control subjects without these interventions, despite using the same number of training feedback trials. Surprisingly, beyond the accuracy gain, the training time for the augmented learning group was also shorter by 20-23%. We demonstrate the efficacy of our approach in a fine-grained categorization task with natural images, as well as tasks in two clinically relevant image domains -- histology and dermoscopy -- where visual learning is notoriously challenging. To the best of our knowledge, this is the first application of ANNs to increase visual learning performance in humans by enhancing category-specific features.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Jun 20, 2024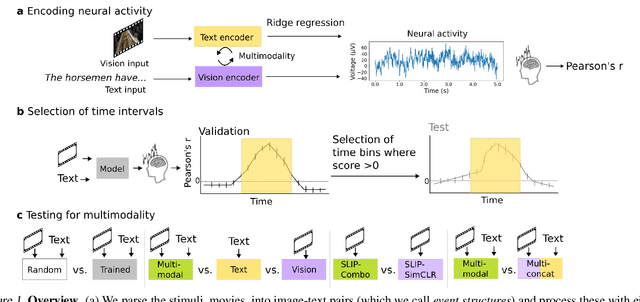

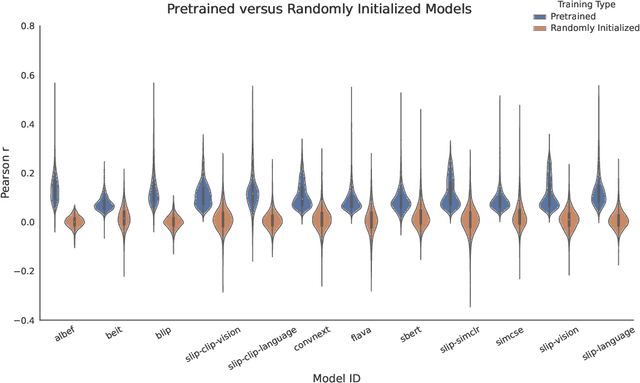
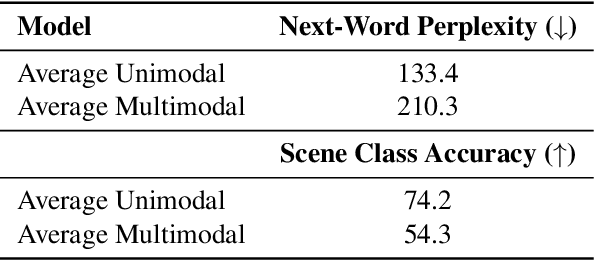
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Is AI fun? HumorDB: a curated dataset and benchmark to investigate graphical humor
Jun 19, 2024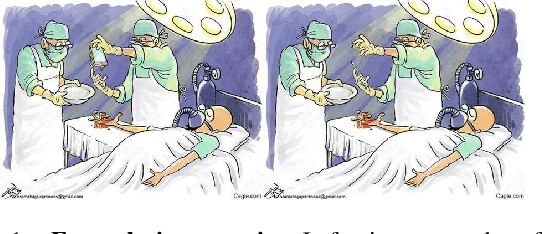
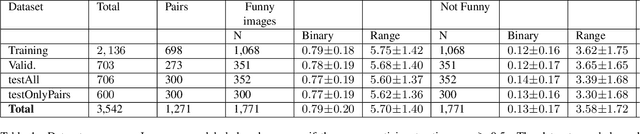
Despite significant advancements in computer vision, understanding complex scenes, particularly those involving humor, remains a substantial challenge. This paper introduces HumorDB, a novel image-only dataset specifically designed to advance visual humor understanding. HumorDB consists of meticulously curated image pairs with contrasting humor ratings, emphasizing subtle visual cues that trigger humor and mitigating potential biases. The dataset enables evaluation through binary classification(Funny or Not Funny), range regression(funniness on a scale from 1 to 10), and pairwise comparison tasks(Which Image is Funnier?), effectively capturing the subjective nature of humor perception. Initial experiments reveal that while vision-only models struggle, vision-language models, particularly those leveraging large language models, show promising results. HumorDB also shows potential as a valuable zero-shot benchmark for powerful large multimodal models. We open-source both the dataset and code under the CC BY 4.0 license.
Benchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the Ventral Visual Cortex
Jun 16, 2024



We characterized the generalization capabilities of DNN-based encoding models when predicting neuronal responses from the visual cortex. We collected \textit{MacaqueITBench}, a large-scale dataset of neural population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using \textit{MacaqueITBench}, we investigated the impact of distribution shifts on models predicting neural activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included several different image-computable types including image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images -- the conventional way these models have been evaluated -- models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20\%$ of the performance on in-distribution test images. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric -- the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neural predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and computational benchmarks are hosted publicly at: https://bit.ly/3zeutVd.
Look Around! Unexpected gains from training on environments in the vicinity of the target
Jan 29, 2024



Solutions to Markov Decision Processes (MDP) are often very sensitive to state transition probabilities. As the estimation of these probabilities is often inaccurate in practice, it is important to understand when and how Reinforcement Learning (RL) agents generalize when transition probabilities change. Here we present a new methodology to evaluate such generalization of RL agents under small shifts in the transition probabilities. Specifically, we evaluate agents in new environments (MDPs) in the vicinity of the training MDP created by adding quantifiable, parametric noise into the transition function of the training MDP. We refer to this process as Noise Injection, and the resulting environments as $\delta$-environments. This process allows us to create controlled variations of the same environment with the level of the noise serving as a metric of distance between environments. Conventional wisdom suggests that training and testing on the same MDP should yield the best results. However, we report several cases of the opposite -- when targeting a specific environment, training the agent in an alternative noise setting can yield superior outcomes. We showcase this phenomenon across $60$ different variations of ATARI games, including PacMan, Pong, and Breakout.
Sparse Distributed Memory is a Continual Learner
Mar 20, 2023Continual learning is a problem for artificial neural networks that their biological counterparts are adept at solving. Building on work using Sparse Distributed Memory (SDM) to connect a core neural circuit with the powerful Transformer model, we create a modified Multi-Layered Perceptron (MLP) that is a strong continual learner. We find that every component of our MLP variant translated from biology is necessary for continual learning. Our solution is also free from any memory replay or task information, and introduces novel methods to train sparse networks that may be broadly applicable.
* 9 Pages. ICLR Acceptance
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023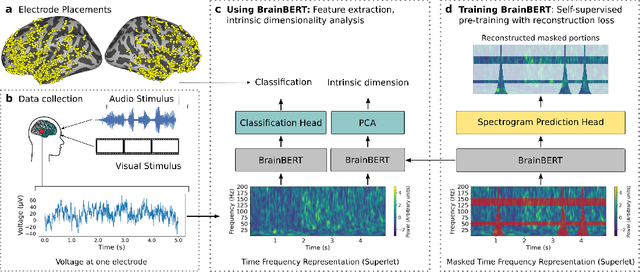
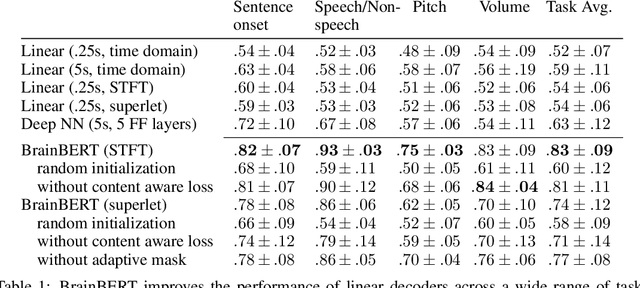
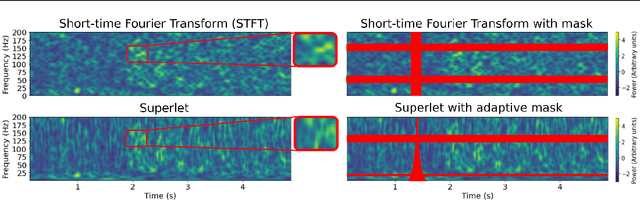
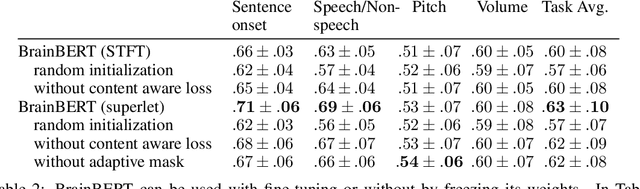
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization
Feb 10, 2023



"Forward-only" algorithms, which train neural networks while avoiding a backward pass, have recently gained attention as a way of solving the biologically unrealistic aspects of backpropagation. Here, we first discuss the similarities between two "forward-only" algorithms, the Forward-Forward and PEPITA frameworks, and demonstrate that PEPITA is equivalent to a Forward-Forward with top-down feedback connections. Then, we focus on PEPITA to address compelling challenges related to the "forward-only" rules, which include providing an analytical understanding of their dynamics and reducing the gap between their performance and that of backpropagation. We propose a theoretical analysis of the dynamics of PEPITA. In particular, we show that PEPITA is well-approximated by an "adaptive-feedback-alignment" algorithm and we analytically track its performance during learning in a prototype high-dimensional setting. Finally, we develop a strategy to apply the weight mirroring algorithm on "forward-only" algorithms with top-down feedback and we show how it impacts PEPITA's accuracy and convergence rate.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022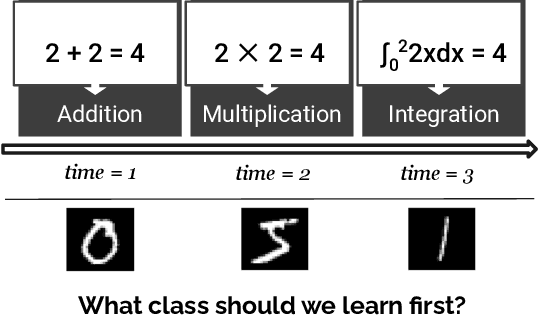
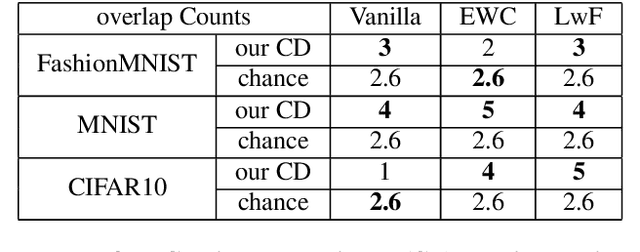
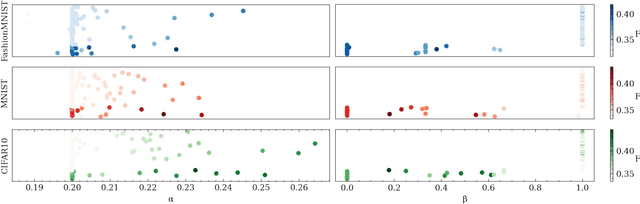
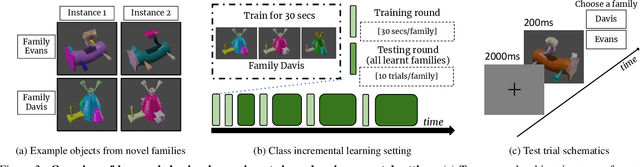
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.