 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoninvasive precision modulation of high-level neural population activity via natural vision perturbations
Jun 05, 2025Precise control of neural activity -- modulating target neurons deep in the brain while leaving nearby neurons unaffected -- is an outstanding challenge in neuroscience, generally achieved through invasive techniques. This study investigates the possibility of precisely and noninvasively modulating neural activity in the high-level primate ventral visual stream via perturbations on one's natural visual feed. When tested on macaque inferior temporal (IT) neural populations, we found quantitative agreement between the model-predicted and biologically realized effect: strong modulation concentrated on targeted neural sites. We extended this to demonstrate accurate injection of experimenter-chosen neural population patterns via subtle perturbations applied on the background of typical natural visual feeds. These results highlight that current machine-executable models of the ventral stream can now design noninvasive, visually-delivered, possibly imperceptible neural interventions at the resolution of individual neurons.
L-WISE: Boosting Human Image Category Learning Through Model-Based Image Selection And Enhancement
Dec 12, 2024


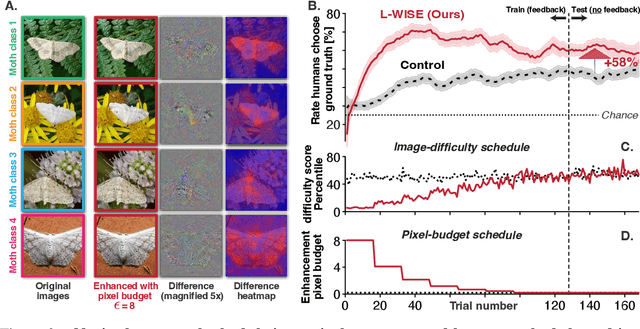
The currently leading artificial neural network (ANN) models of the visual ventral stream -- which are derived from a combination of performance optimization and robustification methods -- have demonstrated a remarkable degree of behavioral alignment with humans on visual categorization tasks. Extending upon previous work, we show that not only can these models guide image perturbations that change the induced human category percepts, but they also can enhance human ability to accurately report the original ground truth. Furthermore, we find that the same models can also be used out-of-the-box to predict the proportion of correct human responses to individual images, providing a simple, human-aligned estimator of the relative difficulty of each image. Motivated by these observations, we propose to augment visual learning in humans in a way that improves human categorization accuracy at test time. Our learning augmentation approach consists of (i) selecting images based on their model-estimated recognition difficulty, and (ii) using image perturbations that aid recognition for novice learners. We find that combining these model-based strategies gives rise to test-time categorization accuracy gains of 33-72% relative to control subjects without these interventions, despite using the same number of training feedback trials. Surprisingly, beyond the accuracy gain, the training time for the augmented learning group was also shorter by 20-23%. We demonstrate the efficacy of our approach in a fine-grained categorization task with natural images, as well as tasks in two clinically relevant image domains -- histology and dermoscopy -- where visual learning is notoriously challenging. To the best of our knowledge, this is the first application of ANNs to increase visual learning performance in humans by enhancing category-specific features.
Robustified ANNs Reveal Wormholes Between Human Category Percepts
Aug 14, 2023The visual object category reports of artificial neural networks (ANNs) are notoriously sensitive to tiny, adversarial image perturbations. Because human category reports (aka human percepts) are thought to be insensitive to those same small-norm perturbations -- and locally stable in general -- this argues that ANNs are incomplete scientific models of human visual perception. Consistent with this, we show that when small-norm image perturbations are generated by standard ANN models, human object category percepts are indeed highly stable. However, in this very same "human-presumed-stable" regime, we find that robustified ANNs reliably discover low-norm image perturbations that strongly disrupt human percepts. These previously undetectable human perceptual disruptions are massive in amplitude, approaching the same level of sensitivity seen in robustified ANNs. Further, we show that robustified ANNs support precise perceptual state interventions: they guide the construction of low-norm image perturbations that strongly alter human category percepts toward specific prescribed percepts. These observations suggest that for arbitrary starting points in image space, there exists a set of nearby "wormholes", each leading the subject from their current category perceptual state into a semantically very different state. Moreover, contemporary ANN models of biological visual processing are now accurate enough to consistently guide us to those portals.
A Penny for Your Thoughts: Self-Supervised Reconstruction of Natural Movies from Brain Activity
Jun 10, 2022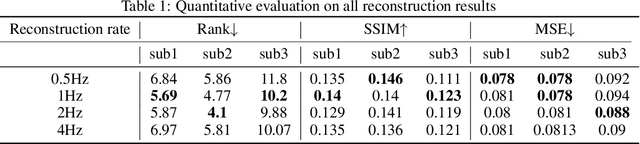
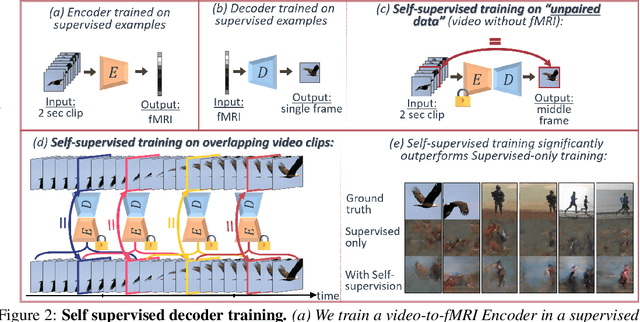


Reconstructing natural videos from fMRI brain recordings is very challenging, for two main reasons: (i) As fMRI data acquisition is difficult, we only have a limited amount of supervised samples, which is not enough to cover the huge space of natural videos; and (ii) The temporal resolution of fMRI recordings is much lower than the frame rate of natural videos. In this paper, we propose a self-supervised approach for natural-movie reconstruction. By employing cycle-consistency over Encoding-Decoding natural videos, we can: (i) exploit the full framerate of the training videos, and not be limited only to clips that correspond to fMRI recordings; (ii) exploit massive amounts of external natural videos which the subjects never saw inside the fMRI machine. These enable increasing the applicable training data by several orders of magnitude, introducing natural video priors to the decoding network, as well as temporal coherence. Our approach significantly outperforms competing methods, since those train only on the limited supervised data. We further introduce a new and simple temporal prior of natural videos, which - when folded into our fMRI decoder further - allows us to reconstruct videos at a higher frame-rate (HFR) of up to x8 of the original fMRI sample rate.
More than meets the eye: Self-supervised depth reconstruction from brain activity
Jun 09, 2021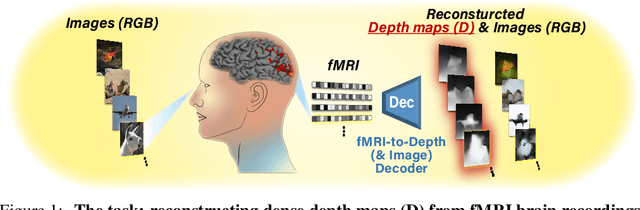
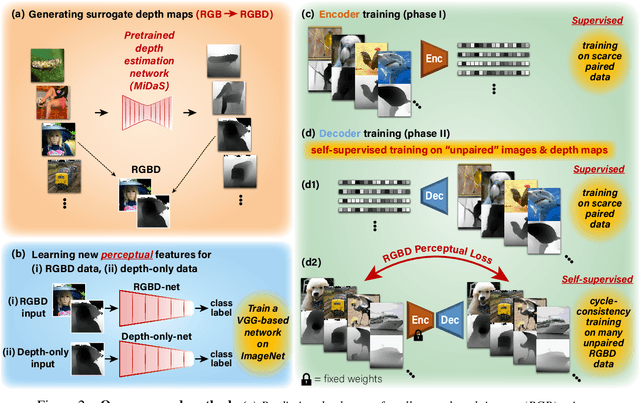

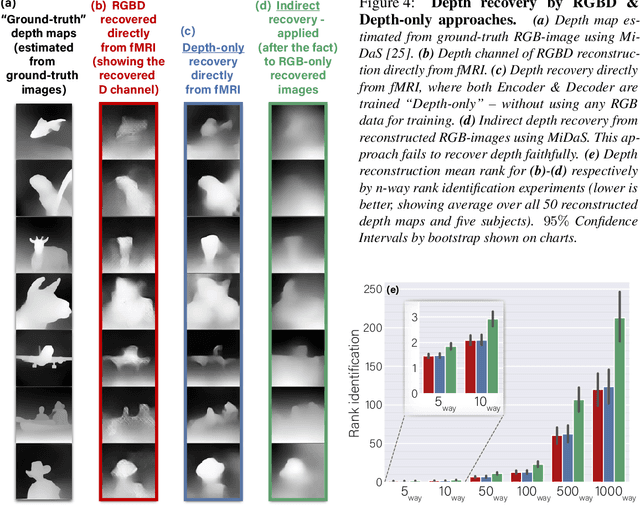
In the past few years, significant advancements were made in reconstruction of observed natural images from fMRI brain recordings using deep-learning tools. Here, for the first time, we show that dense 3D depth maps of observed 2D natural images can also be recovered directly from fMRI brain recordings. We use an off-the-shelf method to estimate the unknown depth maps of natural images. This is applied to both: (i) the small number of images presented to subjects in an fMRI scanner (images for which we have fMRI recordings - referred to as "paired" data), and (ii) a very large number of natural images with no fMRI recordings ("unpaired data"). The estimated depth maps are then used as an auxiliary reconstruction criterion to train for depth reconstruction directly from fMRI. We propose two main approaches: Depth-only recovery and joint image-depth RGBD recovery. Because the number of available "paired" training data (images with fMRI) is small, we enrich the training data via self-supervised cycle-consistent training on many "unpaired" data (natural images & depth maps without fMRI). This is achieved using our newly defined and trained Depth-based Perceptual Similarity metric as a reconstruction criterion. We show that predicting the depth map directly from fMRI outperforms its indirect sequential recovery from the reconstructed images. We further show that activations from early cortical visual areas dominate our depth reconstruction results, and propose means to characterize fMRI voxels by their degree of depth-information tuning. This work adds an important layer of decoded information, extending the current envelope of visual brain decoding capabilities.
Learning to aggregate feature representations
Jul 04, 2019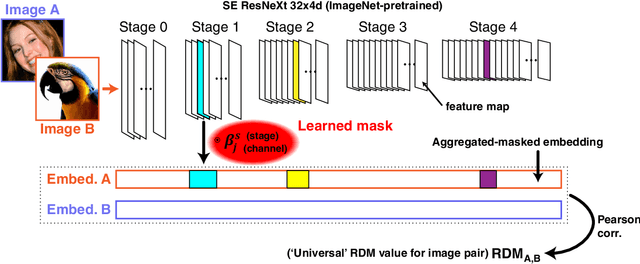


The Algonauts challenge requires to construct a multi-subject encoder of images to brain activity. Deep networks such as ResNet-50 and AlexNet trained for image classification are known to produce feature representations along their intermediate stages which closely mimic the visual hierarchy. However the challenges introduced in the Algonauts project, including combining data from multiple subjects, relying on very few similarity data points, solving for various ROIs, and multi-modality, require devising a flexible framework which can efficiently accommodate them. Here we build upon a recent state-of-the-art classification network (SE-ResNeXt-50) and construct an adaptive combination of its intermediate representations. While the pretrained network serves as a backbone of our model, we learn how to aggregate feature representations along five stages of the network. During learning, our method enables to modulate and screen outputs from each stage along the network as governed by the optimized objective. We applied our method to the Algonauts2019 fMRI and MEG challenges. Using the combined fMRI and MEG data, our approach was rated among the leading five for both challenges. Surprisingly we find that for both the lower and higher order areas (EVC and IT) the adaptive aggregation favors features stemming at later stages of the network.
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI
Jul 03, 2019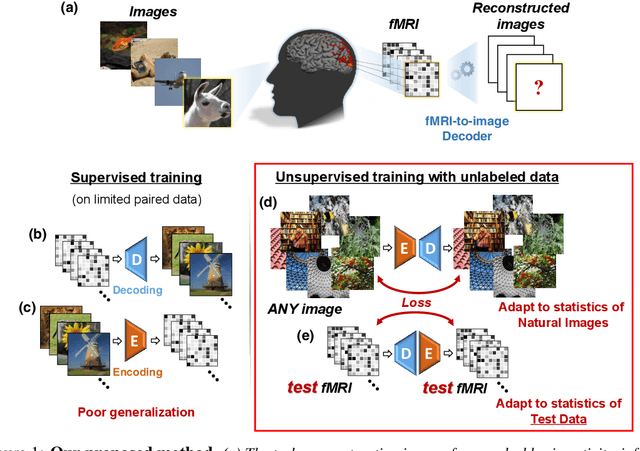
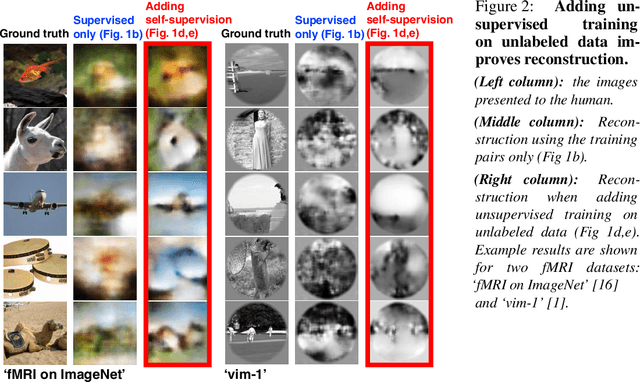
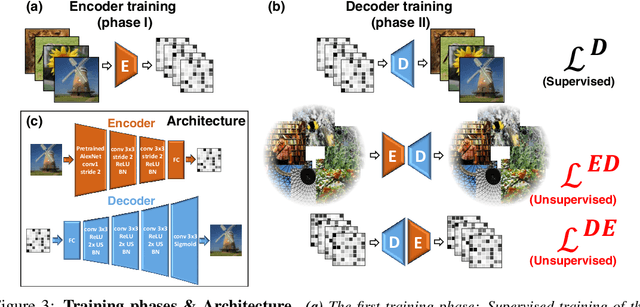
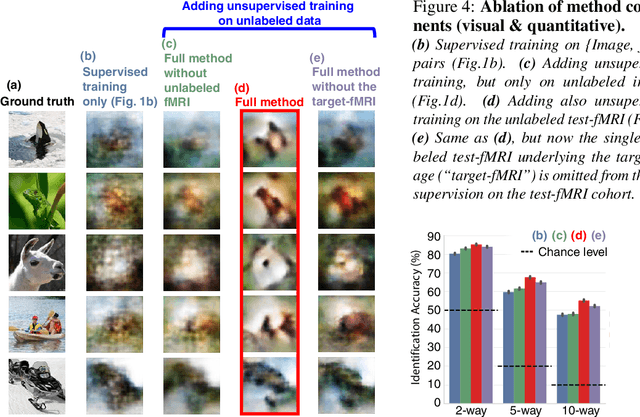
Reconstructing observed images from fMRI brain recordings is challenging. Unfortunately, acquiring sufficient "labeled" pairs of {Image, fMRI} (i.e., images with their corresponding fMRI responses) to span the huge space of natural images is prohibitive for many reasons. We present a novel approach which, in addition to the scarce labeled data (training pairs), allows to train fMRI-to-image reconstruction networks also on "unlabeled" data (i.e., images without fMRI recording, and fMRI recording without images). The proposed model utilizes both an Encoder network (image-to-fMRI) and a Decoder network (fMRI-to-image). Concatenating these two networks back-to-back (Encoder-Decoder & Decoder-Encoder) allows augmenting the training with both types of unlabeled data. Importantly, it allows training on the unlabeled test-fMRI data. This self-supervision adapts the reconstruction network to the new input test-data, despite its deviation from the statistics of the scarce training data.