 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustified ANNs Reveal Wormholes Between Human Category Percepts
Aug 14, 2023The visual object category reports of artificial neural networks (ANNs) are notoriously sensitive to tiny, adversarial image perturbations. Because human category reports (aka human percepts) are thought to be insensitive to those same small-norm perturbations -- and locally stable in general -- this argues that ANNs are incomplete scientific models of human visual perception. Consistent with this, we show that when small-norm image perturbations are generated by standard ANN models, human object category percepts are indeed highly stable. However, in this very same "human-presumed-stable" regime, we find that robustified ANNs reliably discover low-norm image perturbations that strongly disrupt human percepts. These previously undetectable human perceptual disruptions are massive in amplitude, approaching the same level of sensitivity seen in robustified ANNs. Further, we show that robustified ANNs support precise perceptual state interventions: they guide the construction of low-norm image perturbations that strongly alter human category percepts toward specific prescribed percepts. These observations suggest that for arbitrary starting points in image space, there exists a set of nearby "wormholes", each leading the subject from their current category perceptual state into a semantically very different state. Moreover, contemporary ANN models of biological visual processing are now accurate enough to consistently guide us to those portals.
Adversarially trained neural representations may already be as robust as corresponding biological neural representations
Jun 19, 2022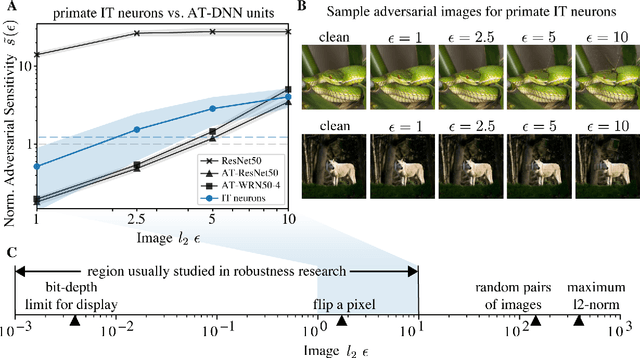
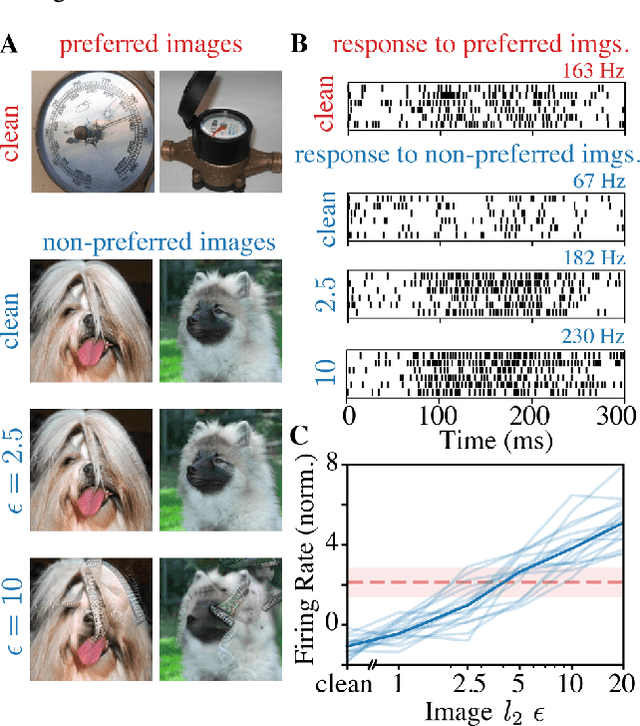
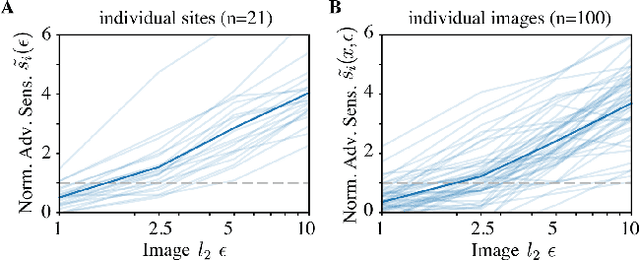
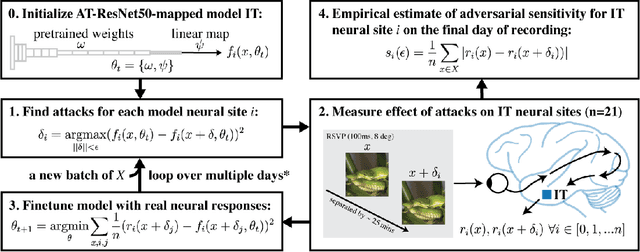
Visual systems of primates are the gold standard of robust perception. There is thus a general belief that mimicking the neural representations that underlie those systems will yield artificial visual systems that are adversarially robust. In this work, we develop a method for performing adversarial visual attacks directly on primate brain activity. We then leverage this method to demonstrate that the above-mentioned belief might not be well founded. Specifically, we report that the biological neurons that make up visual systems of primates exhibit susceptibility to adversarial perturbations that is comparable in magnitude to existing (robustly trained) artificial neural networks.
Predicting Abandonment in Online Coding Tutorials
Jul 13, 2017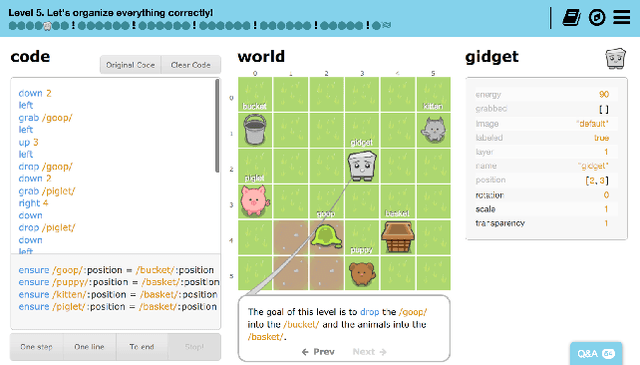
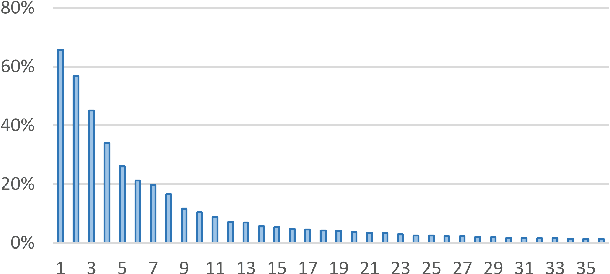
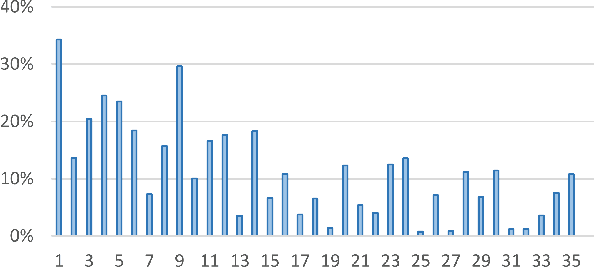
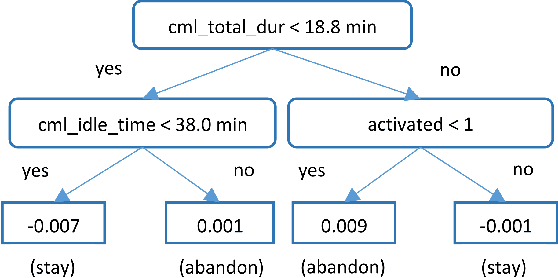
Learners regularly abandon online coding tutorials when they get bored or frustrated, but there are few techniques for anticipating this abandonment to intervene. In this paper, we examine the feasibility of predicting abandonment with machine-learned classifiers. Using interaction logs from an online programming game, we extracted a collection of features that are potentially related to learner abandonment and engagement, then developed classifiers for each level. Across the first five levels of the game, our classifiers successfully predicted 61% to 76% of learners who did not complete the next level, achieving an average AUC of 0.68. In these classifiers, features negatively associated with abandonment included account activation and help-seeking behaviors, whereas features positively associated with abandonment included features indicating difficulty and disengagement. These findings highlight the feasibility of providing timely intervention to learners likely to quit.