 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Biological and Artificial Neural Networks with Task-dependent Neural Manifolds
Dec 21, 2023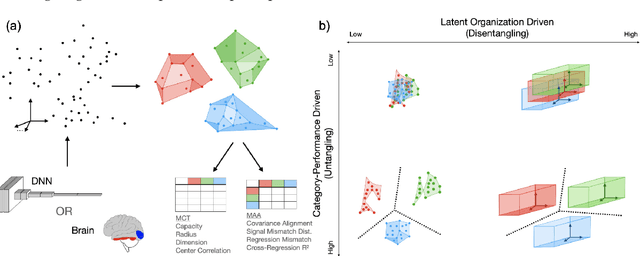
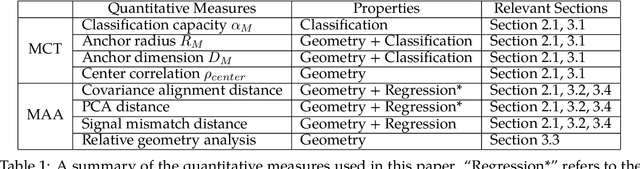
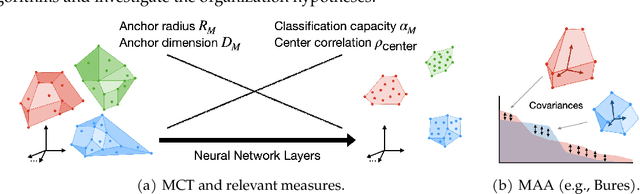

Recently, growth in our understanding of the computations performed in both biological and artificial neural networks has largely been driven by either low-level mechanistic studies or global normative approaches. However, concrete methodologies for bridging the gap between these levels of abstraction remain elusive. In this work, we investigate the internal mechanisms of neural networks through the lens of neural population geometry, aiming to provide understanding at an intermediate level of abstraction, as a way to bridge that gap. Utilizing manifold capacity theory (MCT) from statistical physics and manifold alignment analysis (MAA) from high-dimensional statistics, we probe the underlying organization of task-dependent manifolds in deep neural networks and macaque neural recordings. Specifically, we quantitatively characterize how different learning objectives lead to differences in the organizational strategies of these models and demonstrate how these geometric analyses are connected to the decodability of task-relevant information. These analyses present a strong direction for bridging mechanistic and normative theories in neural networks through neural population geometry, potentially opening up many future research avenues in both machine learning and neuroscience.
Adversarially trained neural representations may already be as robust as corresponding biological neural representations
Jun 19, 2022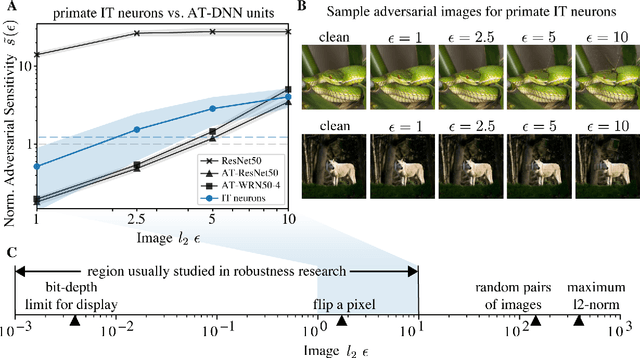
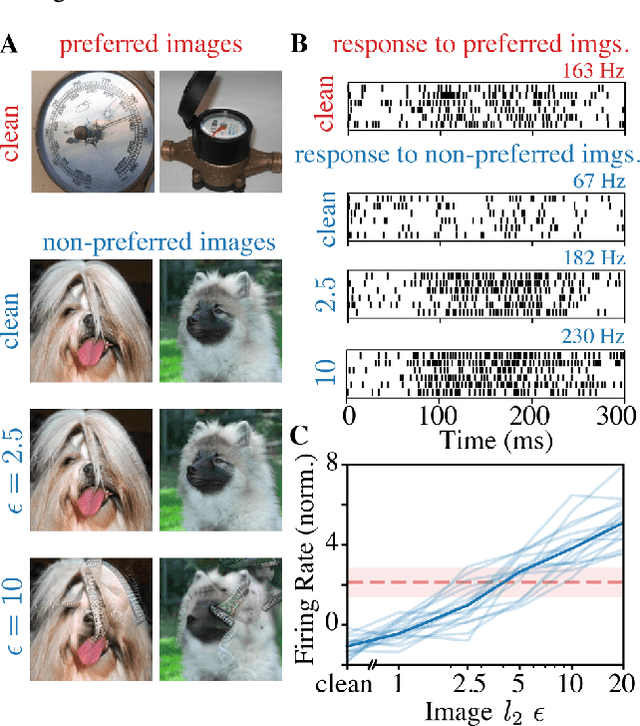
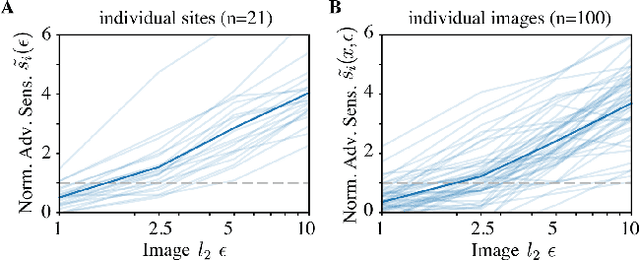
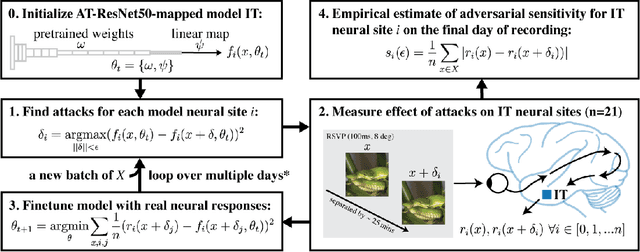
Visual systems of primates are the gold standard of robust perception. There is thus a general belief that mimicking the neural representations that underlie those systems will yield artificial visual systems that are adversarially robust. In this work, we develop a method for performing adversarial visual attacks directly on primate brain activity. We then leverage this method to demonstrate that the above-mentioned belief might not be well founded. Specifically, we report that the biological neurons that make up visual systems of primates exhibit susceptibility to adversarial perturbations that is comparable in magnitude to existing (robustly trained) artificial neural networks.
Neural Population Geometry Reveals the Role of Stochasticity in Robust Perception
Nov 12, 2021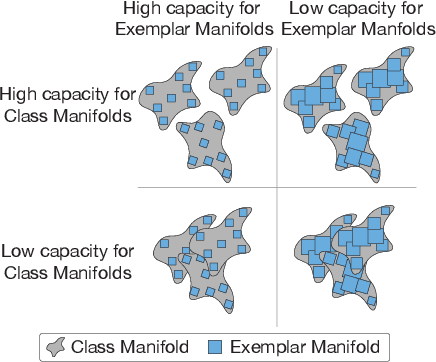
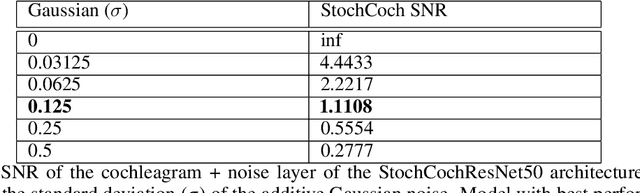
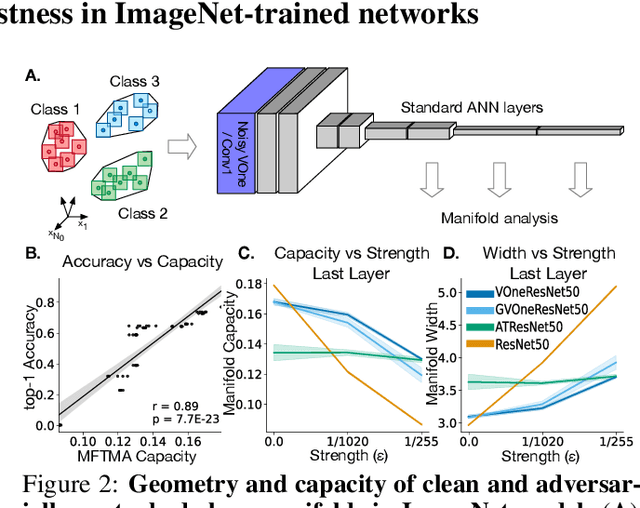

Adversarial examples are often cited by neuroscientists and machine learning researchers as an example of how computational models diverge from biological sensory systems. Recent work has proposed adding biologically-inspired components to visual neural networks as a way to improve their adversarial robustness. One surprisingly effective component for reducing adversarial vulnerability is response stochasticity, like that exhibited by biological neurons. Here, using recently developed geometrical techniques from computational neuroscience, we investigate how adversarial perturbations influence the internal representations of standard, adversarially trained, and biologically-inspired stochastic networks. We find distinct geometric signatures for each type of network, revealing different mechanisms for achieving robust representations. Next, we generalize these results to the auditory domain, showing that neural stochasticity also makes auditory models more robust to adversarial perturbations. Geometric analysis of the stochastic networks reveals overlap between representations of clean and adversarially perturbed stimuli, and quantitatively demonstrates that competing geometric effects of stochasticity mediate a tradeoff between adversarial and clean performance. Our results shed light on the strategies of robust perception utilized by adversarially trained and stochastic networks, and help explain how stochasticity may be beneficial to machine and biological computation.
Combining Different V1 Brain Model Variants to Improve Robustness to Image Corruptions in CNNs
Oct 20, 2021
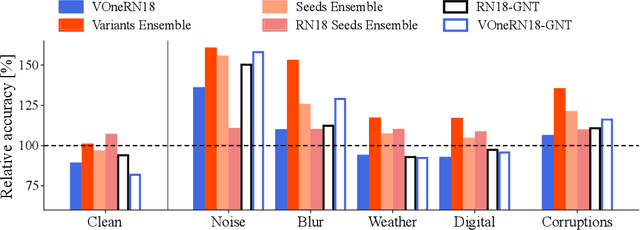


While some convolutional neural networks (CNNs) have surpassed human visual abilities in object classification, they often struggle to recognize objects in images corrupted with different types of common noise patterns, highlighting a major limitation of this family of models. Recently, it has been shown that simulating a primary visual cortex (V1) at the front of CNNs leads to small improvements in robustness to these image perturbations. In this study, we start with the observation that different variants of the V1 model show gains for specific corruption types. We then build a new model using an ensembling technique, which combines multiple individual models with different V1 front-end variants. The model ensemble leverages the strengths of each individual model, leading to significant improvements in robustness across all corruption categories and outperforming the base model by 38% on average. Finally, we show that using distillation, it is possible to partially compress the knowledge in the ensemble model into a single model with a V1 front-end. While the ensembling and distillation techniques used here are hardly biologically-plausible, the results presented here demonstrate that by combining the specific strengths of different neuronal circuits in V1 it is possible to improve the robustness of CNNs for a wide range of perturbations.