 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Evidence is Sparse: Weakly Supervised Early Failure Alerting in Dialogs and LLM-Agent Trajectories
Jun 03, 2026Early failure alerting requires deciding, while a dialog or agent trajectory is still unfolding, whether to flag it as likely to fail. This is challenging because supervision is typically available only as a trajectory-level success/failure label while alerts must be raised from partial interactions. Prior early-classification methods often bridge this gap by assigning the terminal label to every prefix, treating every turn as failure evidence. We hypothesize that this prefix-label assumption is poorly matched to multi-turn language interactions, where evidence of eventual failure is sparse and often delayed. In this paper, we introduce a two-stage approach that learns from this sparse evidence structure and uses the resulting risk estimates for controllable early alerting. Specifically, our attention-based failure predictor learns sparse turn-level failure evidence from trajectory labels and uses it to estimate failure risk from partial histories. We then pair this predictor with $α$-STOP, a single preference-conditioned stopping policy that selects an accuracy-earliness operating point at inference time rather than training a separate trigger for each preference. Across five benchmarks spanning customer support, task-oriented dialog, persuasion, tool use, and planning, we first show that high-relevance failure evidence occupies only 4.7-11.3% of turns and first appears after 59.0-83.6\% of trajectories on average. We further show that the attention-based predictor improves Pareto-frontier quality (hypervolume) by 1-10\% over naive prefix supervision, and that the full system improves frontier quality by 3-42\% over state-of-the-art trigger policies while reducing training cost per operating point by 1-3 orders of magnitude.
It's Not Always Sycophancy: Measuring LLM Conformity as a Function of Epistemic Uncertainty
May 26, 2026Large language models (LLMs) are known to abandon their initial stance to conform to user pushback. While prior research largely attributes this behavior to sycophancy learned during reinforcement learning from human feedback, we hypothesize that conformity is also driven by a model's epistemic uncertainty at inference time. In this paper, we introduce MUSE, a two-stage evaluation framework to disentangle the mechanisms driving LLM conformity. Specifically, MUSE maps a model's epistemic uncertainty in responding to a query against its likelihood to yield to user pushback in a subsequent turn. We demonstrate that the mechanisms driving conformity extend beyond sycophancy alone. Specifically, we characterize two distinct factors that jointly drive conformity: sycophantic conformity, where a model aligns with user pushback even with absolute certainty in its initial response, and uncertainty-driven conformity, where a model's likelihood for conformity increases alongside its uncertainty. Furthermore, we conduct ablation studies to demonstrate that both sycophantic conformity and uncertainty-driven conformity grow with 1) the LLM's perceived expertise of the user and 2) the plausibility of the user's suggestions. More broadly, MUSE informs more targeted intervention strategies by distinguishing alignment-induced sycophancy and training-corpora-driven uncertainty.
Stop Listening to Me! How Multi-turn Conversations Can Degrade Diagnostic Reasoning
Mar 12, 2026Patients and clinicians are increasingly using chatbots powered by large language models (LLMs) for healthcare inquiries. While state-of-the-art LLMs exhibit high performance on static diagnostic reasoning benchmarks, their efficacy across multi-turn conversations, which better reflect real-world usage, has been understudied. In this paper, we evaluate 17 LLMs across three clinical datasets to investigate how partitioning the decision-space into multiple simpler turns of conversation influences their diagnostic reasoning. Specifically, we develop a "stick-or-switch" evaluation framework to measure model conviction (i.e., defending a correct diagnosis or safe abstention against incorrect suggestions) and flexibility (i.e., recognizing a correct suggestion when it is introduced) across conversations. Our experiments reveal the conversation tax, where multi-turn interactions consistently degrade performance when compared to single-shot baselines. Notably, models frequently abandon initial correct diagnoses and safe abstentions to align with incorrect user suggestions. Additionally, several models exhibit blind switching, failing to distinguish between signal and incorrect suggestions.
Learning When to Sample: Confidence-Aware Self-Consistency for Efficient LLM Chain-of-Thought Reasoning
Mar 09, 2026Large language models (LLMs) achieve strong reasoning performance through chain-of-thought (CoT) reasoning, yet often generate unnecessarily long reasoning paths that incur high inference cost. Recent self-consistency-based approaches further improve accuracy but require sampling and aggregating multiple reasoning trajectories, leading to substantial additional computational overhead. This paper introduces a confidence-aware decision framework that analyzes a single completed reasoning trajectory to adaptively select between single-path and multi-path reasoning. The framework is trained using sentence-level numeric and linguistic features extracted from intermediate reasoning states in the MedQA dataset and generalizes effectively to MathQA, MedMCQA, and MMLU without additional fine-tuning. Experimental results show that the proposed method maintains accuracy comparable to multi-path baselines while using up to 80\% fewer tokens. These findings demonstrate that reasoning trajectories contain rich signals for uncertainty estimation, enabling a simple, transferable mechanism to balance accuracy and efficiency in LLM reasoning.
RIMRULE: Improving Tool-Using Language Agents via MDL-Guided Rule Learning
Jan 05, 2026Large language models (LLMs) often struggle to use tools reliably in domain-specific settings, where APIs may be idiosyncratic, under-documented, or tailored to private workflows. This highlights the need for effective adaptation to task-specific tools. We propose RIMRULE, a neuro-symbolic approach for LLM adaptation based on dynamic rule injection. Compact, interpretable rules are distilled from failure traces and injected into the prompt during inference to improve task performance. These rules are proposed by the LLM itself and consolidated using a Minimum Description Length (MDL) objective that favors generality and conciseness. Each rule is stored in both natural language and a structured symbolic form, supporting efficient retrieval at inference time. Experiments on tool-use benchmarks show that this approach improves accuracy on both seen and unseen tools without modifying LLM weights. It outperforms prompting-based adaptation methods and complements finetuning. Moreover, rules learned from one LLM can be reused to improve others, including long reasoning LLMs, highlighting the portability of symbolic knowledge across architectures.
The Behavior Gap: Evaluating Zero-shot LLM Agents in Complex Task-Oriented Dialogs
Jun 13, 2025Large Language Model (LLM)-based agents have significantly impacted Task-Oriented Dialog Systems (TODS) but continue to face notable performance challenges, especially in zero-shot scenarios. While prior work has noted this performance gap, the behavioral factors driving the performance gap remain under-explored. This study proposes a comprehensive evaluation framework to quantify the behavior gap between AI agents and human experts, focusing on discrepancies in dialog acts, tool usage, and knowledge utilization. Our findings reveal that this behavior gap is a critical factor negatively impacting the performance of LLM agents. Notably, as task complexity increases, the behavior gap widens (correlation: 0.963), leading to a degradation of agent performance on complex task-oriented dialogs. For the most complex task in our study, even the GPT-4o-based agent exhibits low alignment with human behavior, with low F1 scores for dialog acts (0.464), excessive and often misaligned tool usage with a F1 score of 0.139, and ineffective usage of external knowledge. Reducing such behavior gaps leads to significant performance improvement (24.3% on average). This study highlights the importance of comprehensive behavioral evaluations and improved alignment strategies to enhance the effectiveness of LLM-based TODS in handling complex tasks.
The Missing Invariance Principle Found -- the Reciprocal Twin of Invariant Risk Minimization
May 29, 2022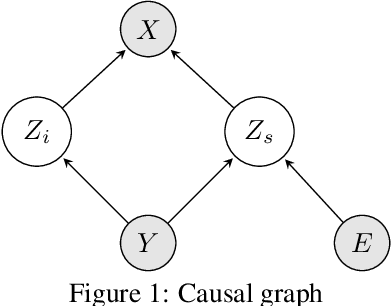
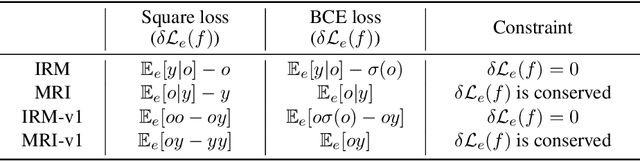
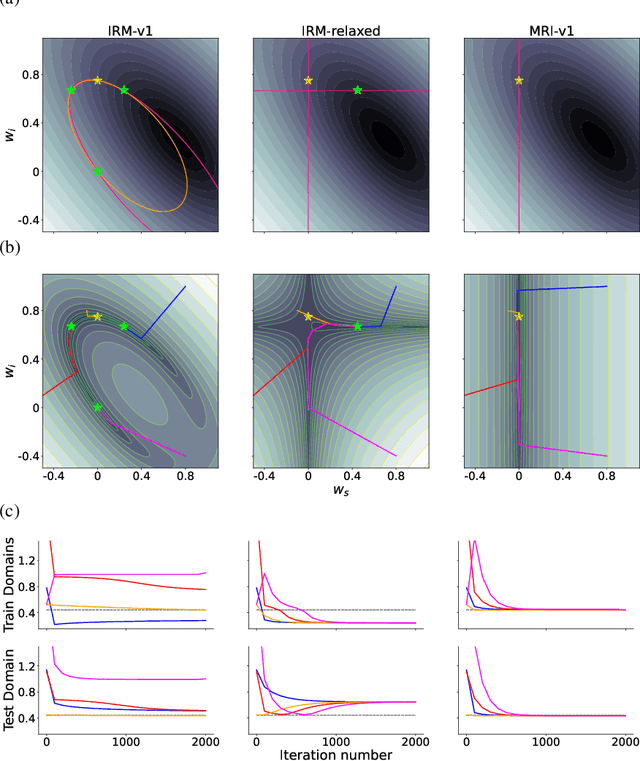

Machine learning models often generalize poorly to out-of-distribution (OOD) data as a result of relying on features that are spuriously correlated with the label during training. Recently, the technique of Invariant Risk Minimization (IRM) was proposed to learn predictors that only use invariant features by conserving the feature-conditioned class expectation $\mathbb{E}_e[y|f(x)]$ across environments. However, more recent studies have demonstrated that IRM can fail in various task settings. Here, we identify a fundamental flaw of IRM formulation that causes the failure. We then introduce a complementary notion of invariance, MRI, that is based on conserving the class-conditioned feature expectation $\mathbb{E}_e[f(x)|y]$ across environments, that corrects for the flaw in IRM. Further, we introduce a simplified, practical version of the MRI formulation called as MRI-v1. We note that this constraint is convex which confers it with an advantage over the practical version of IRM, IRM-v1, which imposes non-convex constraints. We prove that in a general linear problem setting, MRI-v1 can guarantee invariant predictors given sufficient environments. We also empirically demonstrate that MRI strongly out-performs IRM and consistently achieves near-optimal OOD generalization in image-based nonlinear problems.
Combining Different V1 Brain Model Variants to Improve Robustness to Image Corruptions in CNNs
Oct 20, 2021
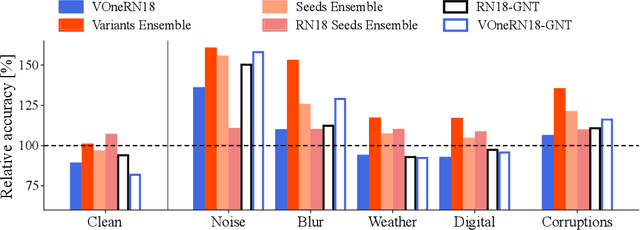


While some convolutional neural networks (CNNs) have surpassed human visual abilities in object classification, they often struggle to recognize objects in images corrupted with different types of common noise patterns, highlighting a major limitation of this family of models. Recently, it has been shown that simulating a primary visual cortex (V1) at the front of CNNs leads to small improvements in robustness to these image perturbations. In this study, we start with the observation that different variants of the V1 model show gains for specific corruption types. We then build a new model using an ensembling technique, which combines multiple individual models with different V1 front-end variants. The model ensemble leverages the strengths of each individual model, leading to significant improvements in robustness across all corruption categories and outperforming the base model by 38% on average. Finally, we show that using distillation, it is possible to partially compress the knowledge in the ensemble model into a single model with a V1 front-end. While the ensembling and distillation techniques used here are hardly biologically-plausible, the results presented here demonstrate that by combining the specific strengths of different neuronal circuits in V1 it is possible to improve the robustness of CNNs for a wide range of perturbations.