 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIMRULE: Improving Tool-Using Language Agents via MDL-Guided Rule Learning
Jan 05, 2026Large language models (LLMs) often struggle to use tools reliably in domain-specific settings, where APIs may be idiosyncratic, under-documented, or tailored to private workflows. This highlights the need for effective adaptation to task-specific tools. We propose RIMRULE, a neuro-symbolic approach for LLM adaptation based on dynamic rule injection. Compact, interpretable rules are distilled from failure traces and injected into the prompt during inference to improve task performance. These rules are proposed by the LLM itself and consolidated using a Minimum Description Length (MDL) objective that favors generality and conciseness. Each rule is stored in both natural language and a structured symbolic form, supporting efficient retrieval at inference time. Experiments on tool-use benchmarks show that this approach improves accuracy on both seen and unseen tools without modifying LLM weights. It outperforms prompting-based adaptation methods and complements finetuning. Moreover, rules learned from one LLM can be reused to improve others, including long reasoning LLMs, highlighting the portability of symbolic knowledge across architectures.
The Behavior Gap: Evaluating Zero-shot LLM Agents in Complex Task-Oriented Dialogs
Jun 13, 2025Large Language Model (LLM)-based agents have significantly impacted Task-Oriented Dialog Systems (TODS) but continue to face notable performance challenges, especially in zero-shot scenarios. While prior work has noted this performance gap, the behavioral factors driving the performance gap remain under-explored. This study proposes a comprehensive evaluation framework to quantify the behavior gap between AI agents and human experts, focusing on discrepancies in dialog acts, tool usage, and knowledge utilization. Our findings reveal that this behavior gap is a critical factor negatively impacting the performance of LLM agents. Notably, as task complexity increases, the behavior gap widens (correlation: 0.963), leading to a degradation of agent performance on complex task-oriented dialogs. For the most complex task in our study, even the GPT-4o-based agent exhibits low alignment with human behavior, with low F1 scores for dialog acts (0.464), excessive and often misaligned tool usage with a F1 score of 0.139, and ineffective usage of external knowledge. Reducing such behavior gaps leads to significant performance improvement (24.3% on average). This study highlights the importance of comprehensive behavioral evaluations and improved alignment strategies to enhance the effectiveness of LLM-based TODS in handling complex tasks.
SCE: Scalable Consistency Ensembles Make Blackbox Large Language Model Generation More Reliable
Mar 13, 2025Large language models (LLMs) have demonstrated remarkable performance, yet their diverse strengths and weaknesses prevent any single LLM from achieving dominance across all tasks. Ensembling multiple LLMs is a promising approach to generate reliable responses but conventional ensembling frameworks suffer from high computational overheads. This work introduces Scalable Consistency Ensemble (SCE), an efficient framework for ensembling LLMs by prompting consistent outputs. The SCE framework systematically evaluates and integrates outputs to produce a cohesive result through two core components: SCE-CHECK, a mechanism that gauges the consistency between response pairs via semantic equivalence; and SCE-FUSION, which adeptly merges the highest-ranked consistent responses from SCE-CHECK, to optimize collective strengths and mitigating potential weaknesses. To improve the scalability with multiple inference queries, we further propose ``{You Only Prompt Once}'' (YOPO), a novel technique that reduces the inference complexity of pairwise comparison from quadratic to constant time. We perform extensive empirical evaluations on diverse benchmark datasets to demonstrate \methodName's effectiveness. Notably, the \saccheckcomponent outperforms conventional baselines with enhanced performance and a significant reduction in computational overhead.
Gradient-guided Attention Map Editing: Towards Efficient Contextual Hallucination Mitigation
Mar 11, 2025In tasks like summarization and open-book question answering (QA), Large Language Models (LLMs) often encounter "contextual hallucination", where they produce irrelevant or incorrect responses despite having access to accurate source information. This typically occurs because these models tend to prioritize self-generated content over the input context, causing them to disregard pertinent details. To address this challenge, we introduce a novel method called "Guided Attention Map Editing" (GAME), which dynamically adjusts attention maps to improve contextual relevance. During inference, GAME employs a trained classifier to identify attention maps prone to inducing hallucinations and executes targeted interventions. These interventions, guided by gradient-informed "edit directions'', strategically redistribute attention weights across various heads to effectively reduce hallucination. Comprehensive evaluations on challenging summarization and open-book QA tasks show that GAME consistently reduces hallucinations across a variety of open-source models. Specifically, GAME reduces hallucinations by 10% in the XSum summarization task while achieving a 7X speed-up in computational efficiency compared to the state-of-the-art baselines.
Learning to Search Effective Example Sequences for In-Context Learning
Mar 11, 2025Large language models (LLMs) demonstrate impressive few-shot learning capabilities, but their performance varies widely based on the sequence of in-context examples. Key factors influencing this include the sequence's length, composition, and arrangement, as well as its relation to the specific query. Existing methods often tackle these factors in isolation, overlooking their interdependencies. Moreover, the extensive search space for selecting optimal sequences complicates the development of a holistic approach. In this work, we introduce Beam Search-based Example Sequence Constructor (BESC), a novel method for learning to construct optimal example sequences. BESC addresses all key factors involved in sequence selection by considering them jointly during inference, while incrementally building the sequence. This design enables the use of beam search to significantly reduce the complexity of the search space. Experiments across various datasets and language models show notable improvements in performance.
Automatic Prompt Optimization via Heuristic Search: A Survey
Feb 26, 2025Recent advances in Large Language Models have led to remarkable achievements across a variety of Natural Language Processing tasks, making prompt engineering increasingly central to guiding model outputs. While manual methods can be effective, they typically rely on intuition and do not automatically refine prompts over time. In contrast, automatic prompt optimization employing heuristic-based search algorithms can systematically explore and improve prompts with minimal human oversight. This survey proposes a comprehensive taxonomy of these methods, categorizing them by where optimization occurs, what is optimized, what criteria drive the optimization, which operators generate new prompts, and which iterative search algorithms are applied. We further highlight specialized datasets and tools that support and accelerate automated prompt refinement. We conclude by discussing key open challenges pointing toward future opportunities for more robust and versatile LLM applications.
Synthetic Knowledge Ingestion: Towards Knowledge Refinement and Injection for Enhancing Large Language Models
Oct 12, 2024



Large language models (LLMs) are proficient in capturing factual knowledge across various domains. However, refining their capabilities on previously seen knowledge or integrating new knowledge from external sources remains a significant challenge. In this work, we propose a novel synthetic knowledge ingestion method called Ski, which leverages fine-grained synthesis, interleaved generation, and assemble augmentation strategies to construct high-quality data representations from raw knowledge sources. We then integrate Ski and its variations with three knowledge injection techniques: Retrieval Augmented Generation (RAG), Supervised Fine-tuning (SFT), and Continual Pre-training (CPT) to inject and refine knowledge in language models. Extensive empirical experiments are conducted on various question-answering tasks spanning finance, biomedicine, and open-generation domains to demonstrate that Ski significantly outperforms baseline methods by facilitating effective knowledge injection. We believe that our work is an important step towards enhancing the factual accuracy of LLM outputs by refining knowledge representation and injection capabilities.
Survival of the Safest: Towards Secure Prompt Optimization through Interleaved Multi-Objective Evolution
Oct 12, 2024Large language models (LLMs) have demonstrated remarkable capabilities; however, the optimization of their prompts has historically prioritized performance metrics at the expense of crucial safety and security considerations. To overcome this shortcoming, we introduce "Survival of the Safest" (SoS), an innovative multi-objective prompt optimization framework that enhances both performance and security in LLMs simultaneously. SoS utilizes an interleaved multi-objective evolution strategy, integrating semantic, feedback, and crossover mutations to effectively traverse the prompt landscape. Differing from the computationally demanding Pareto front methods, SoS provides a scalable solution that expedites optimization in complex, high-dimensional discrete search spaces while keeping computational demands low. Our approach accommodates flexible weighting of objectives and generates a pool of optimized candidates, empowering users to select prompts that optimally meet their specific performance and security needs. Experimental evaluations across diverse benchmark datasets affirm SoS's efficacy in delivering high performance and notably enhancing safety and security compared to single-objective methods. This advancement marks a significant stride towards the deployment of LLM systems that are both high-performing and secure across varied industrial applications
Do You Know What You Are Talking About? Characterizing Query-Knowledge Relevance For Reliable Retrieval Augmented Generation
Oct 10, 2024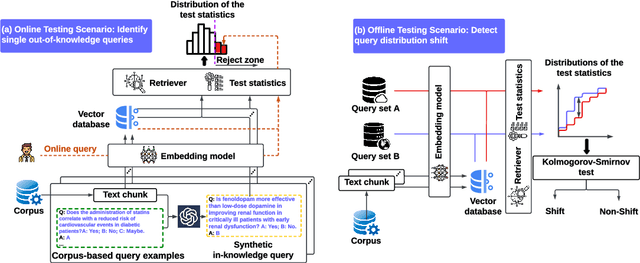
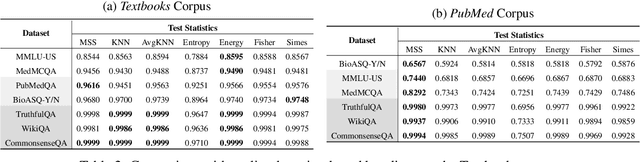
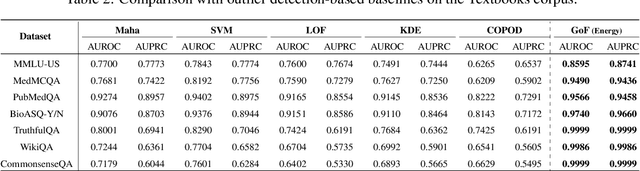
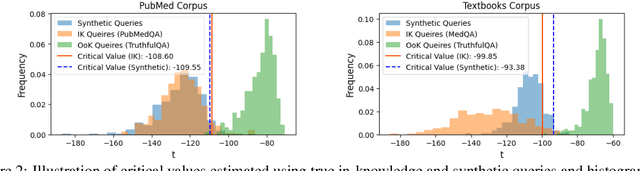
Language models (LMs) are known to suffer from hallucinations and misinformation. Retrieval augmented generation (RAG) that retrieves verifiable information from an external knowledge corpus to complement the parametric knowledge in LMs provides a tangible solution to these problems. However, the generation quality of RAG is highly dependent on the relevance between a user's query and the retrieved documents. Inaccurate responses may be generated when the query is outside of the scope of knowledge represented in the external knowledge corpus or if the information in the corpus is out-of-date. In this work, we establish a statistical framework that assesses how well a query can be answered by an RAG system by capturing the relevance of knowledge. We introduce an online testing procedure that employs goodness-of-fit (GoF) tests to inspect the relevance of each user query to detect out-of-knowledge queries with low knowledge relevance. Additionally, we develop an offline testing framework that examines a collection of user queries, aiming to detect significant shifts in the query distribution which indicates the knowledge corpus is no longer sufficiently capable of supporting the interests of the users. We demonstrate the capabilities of these strategies through a systematic evaluation on eight question-answering (QA) datasets, the results of which indicate that the new testing framework is an efficient solution to enhance the reliability of existing RAG systems.
SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models
Mar 04, 2024In recent years, large language models (LLMs) have become increasingly prevalent, offering remarkable text generation capabilities. However, a pressing challenge is their tendency to make confidently wrong predictions, highlighting the critical need for uncertainty quantification (UQ) in LLMs. While previous works have mainly focused on addressing aleatoric uncertainty, the full spectrum of uncertainties, including epistemic, remains inadequately explored. Motivated by this gap, we introduce a novel UQ method, sampling with perturbation for UQ (SPUQ), designed to tackle both aleatoric and epistemic uncertainties. The method entails generating a set of perturbations for LLM inputs, sampling outputs for each perturbation, and incorporating an aggregation module that generalizes the sampling uncertainty approach for text generation tasks. Through extensive experiments on various datasets, we investigated different perturbation and aggregation techniques. Our findings show a substantial improvement in model uncertainty calibration, with a reduction in Expected Calibration Error (ECE) by 50\% on average. Our findings suggest that our proposed UQ method offers promising steps toward enhancing the reliability and trustworthiness of LLMs.