 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-weighted Direct Preference Optimization with Attention
May 21, 2026Direct Preference Optimization (DPO) aligns Large Language Models with human preferences without the need for a separate reward model. However, DPO treats all tokens in responses equally, neglecting the differing importance of individual tokens. Existing token-level PO methods compute the token weights using either token-position-based heuristic functions or probability estimates given by a separately trained model, which lacks robustness and incurs extra training cost. In contrast, we propose Token-weighted DPO (TwDPO) -- a novel training objective grounded on token-weighted RL -- and AttentionPO -- an instantiation of TwDPO that uses attention from the LLM itself to estimate token weights. AttentionPO prompts the LLM to serve as a pairwise judge and check where the model attends when comparing the responses. This design makes AttentionPO content-aware, adjusting weights based on response content, and efficient, incurring only two extra forward passes per example. Experiment results show that AttentionPO significantly improves performance on AlpacaEval, MT-Bench, and ArenaHard, surpassing existing Preference Optimization methods.
Hand-in-the-Loop: Improving Dexterous VLA via Seamless Interventional Correction
May 14, 2026Vision-Language-Action (VLA) models are prone to compounding errors in dexterous manipulation, where high-dimensional action spaces and contact-rich dynamics amplify small policy deviations over long horizons. While Interactive Imitation Learning (IIL) can refine policies through human takeover data, applying it to high-degree-of-freedom (DoF) robotic hands remains challenging due to a command mismatch between human teleoperation and policy execution at the takeover moment, which causes abrupt robot-hand configuration changes, or "gesture jumps". We present Hand-in-the-Loop (HandITL), a seamless human-in-the-loop intervention method that blends human corrective intent with autonomous policy execution to avoid gesture jumps during bimanual dexterous manipulation. Compared with direct teleoperation takeover, HandITL reduces takeover jitter by 99.8% and preserves robust post-takeover manipulation, reducing grasp failures by 87.5% and mean completion time by 19.1%. We validate HandITL on tasks requiring bimanual coordination, tool use, and fine-grained long-horizon manipulation. When used to collect intervention data for policy refinement, HandITL yields policies that outperform those trained with standard teleoperation data by 19% on average across three long-horizon dexterous tasks.
WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
Feb 09, 2026While world models have emerged as a cornerstone of embodied intelligence by enabling agents to reason about environmental dynamics through action-conditioned prediction, their evaluation remains fragmented. Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks. In this work, we introduce WorldArena, a unified benchmark designed to systematically evaluate embodied world models across both perceptual and functional dimensions. WorldArena assesses models through three dimensions: video perception quality, measured with 16 metrics across six sub-dimensions; embodied task functionality, which evaluates world models as data engines, policy evaluators, and action planners integrating with subjective human evaluation. Furthermore, we propose EWMScore, a holistic metric integrating multi-dimensional performance into a single interpretable index. Through extensive experiments on 14 representative models, we reveal a significant perception-functionality gap, showing that high visual quality does not necessarily translate into strong embodied task capability. WorldArena benchmark with the public leaderboard is released at https://worldarena.ai, providing a framework for tracking progress toward truly functional world models in embodied AI.
From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantification in Large Language Models
Jan 22, 2026While Large Language Models (LLMs) show remarkable capabilities, their unreliability remains a critical barrier to deployment in high-stakes domains. This survey charts a functional evolution in addressing this challenge: the evolution of uncertainty from a passive diagnostic metric to an active control signal guiding real-time model behavior. We demonstrate how uncertainty is leveraged as an active control signal across three frontiers: in \textbf{advanced reasoning} to optimize computation and trigger self-correction; in \textbf{autonomous agents} to govern metacognitive decisions about tool use and information seeking; and in \textbf{reinforcement learning} to mitigate reward hacking and enable self-improvement via intrinsic rewards. By grounding these advancements in emerging theoretical frameworks like Bayesian methods and Conformal Prediction, we provide a unified perspective on this transformative trend. This survey provides a comprehensive overview, critical analysis, and practical design patterns, arguing that mastering the new trend of uncertainty is essential for building the next generation of scalable, reliable, and trustworthy AI.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025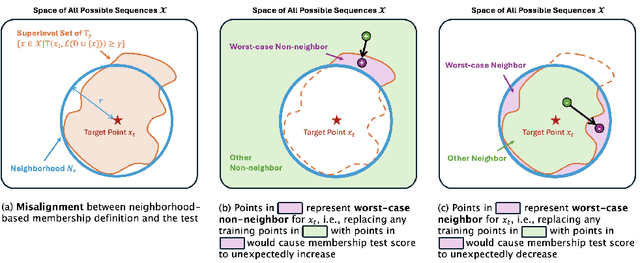

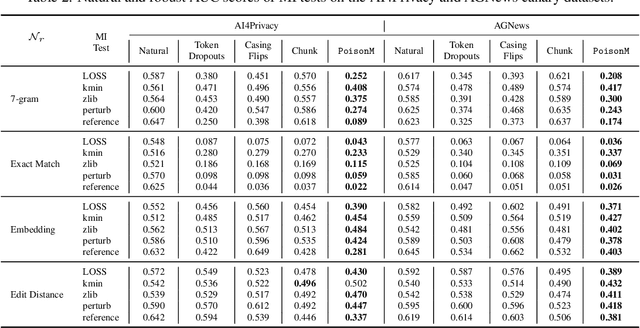
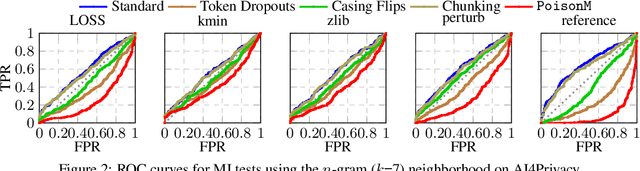
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
Can Large Language Models Help Multimodal Language Analysis? MMLA: A Comprehensive Benchmark
Apr 24, 2025Multimodal language analysis is a rapidly evolving field that leverages multiple modalities to enhance the understanding of high-level semantics underlying human conversational utterances. Despite its significance, little research has investigated the capability of multimodal large language models (MLLMs) to comprehend cognitive-level semantics. In this paper, we introduce MMLA, a comprehensive benchmark specifically designed to address this gap. MMLA comprises over 61K multimodal utterances drawn from both staged and real-world scenarios, covering six core dimensions of multimodal semantics: intent, emotion, dialogue act, sentiment, speaking style, and communication behavior. We evaluate eight mainstream branches of LLMs and MLLMs using three methods: zero-shot inference, supervised fine-tuning, and instruction tuning. Extensive experiments reveal that even fine-tuned models achieve only about 60%~70% accuracy, underscoring the limitations of current MLLMs in understanding complex human language. We believe that MMLA will serve as a solid foundation for exploring the potential of large language models in multimodal language analysis and provide valuable resources to advance this field. The datasets and code are open-sourced at https://github.com/thuiar/MMLA.
SCE: Scalable Consistency Ensembles Make Blackbox Large Language Model Generation More Reliable
Mar 13, 2025Large language models (LLMs) have demonstrated remarkable performance, yet their diverse strengths and weaknesses prevent any single LLM from achieving dominance across all tasks. Ensembling multiple LLMs is a promising approach to generate reliable responses but conventional ensembling frameworks suffer from high computational overheads. This work introduces Scalable Consistency Ensemble (SCE), an efficient framework for ensembling LLMs by prompting consistent outputs. The SCE framework systematically evaluates and integrates outputs to produce a cohesive result through two core components: SCE-CHECK, a mechanism that gauges the consistency between response pairs via semantic equivalence; and SCE-FUSION, which adeptly merges the highest-ranked consistent responses from SCE-CHECK, to optimize collective strengths and mitigating potential weaknesses. To improve the scalability with multiple inference queries, we further propose ``{You Only Prompt Once}'' (YOPO), a novel technique that reduces the inference complexity of pairwise comparison from quadratic to constant time. We perform extensive empirical evaluations on diverse benchmark datasets to demonstrate \methodName's effectiveness. Notably, the \saccheckcomponent outperforms conventional baselines with enhanced performance and a significant reduction in computational overhead.
Towards Statistical Factuality Guarantee for Large Vision-Language Models
Feb 27, 2025Advancements in Large Vision-Language Models (LVLMs) have demonstrated promising performance in a variety of vision-language tasks involving image-conditioned free-form text generation. However, growing concerns about hallucinations in LVLMs, where the generated text is inconsistent with the visual context, are becoming a major impediment to deploying these models in applications that demand guaranteed reliability. In this paper, we introduce a framework to address this challenge, ConfLVLM, which is grounded on conformal prediction to achieve finite-sample distribution-free statistical guarantees on the factuality of LVLM output. This framework treats an LVLM as a hypothesis generator, where each generated text detail (or claim) is considered an individual hypothesis. It then applies a statistical hypothesis testing procedure to verify each claim using efficient heuristic uncertainty measures to filter out unreliable claims before returning any responses to users. We conduct extensive experiments covering three representative application domains, including general scene understanding, medical radiology report generation, and document understanding. Remarkably, ConfLVLM reduces the error rate of claims generated by LLaVa-1.5 for scene descriptions from 87.8\% to 10.0\% by filtering out erroneous claims with a 95.3\% true positive rate. Our results further demonstrate that ConfLVLM is highly flexible, and can be applied to any black-box LVLMs paired with any uncertainty measure for any image-conditioned free-form text generation task while providing a rigorous guarantee on controlling the risk of hallucination.
Automatic Prompt Optimization via Heuristic Search: A Survey
Feb 26, 2025



Recent advances in Large Language Models have led to remarkable achievements across a variety of Natural Language Processing tasks, making prompt engineering increasingly central to guiding model outputs. While manual methods can be effective, they typically rely on intuition and do not automatically refine prompts over time. In contrast, automatic prompt optimization employing heuristic-based search algorithms can systematically explore and improve prompts with minimal human oversight. This survey proposes a comprehensive taxonomy of these methods, categorizing them by where optimization occurs, what is optimized, what criteria drive the optimization, which operators generate new prompts, and which iterative search algorithms are applied. We further highlight specialized datasets and tools that support and accelerate automated prompt refinement. We conclude by discussing key open challenges pointing toward future opportunities for more robust and versatile LLM applications.