 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in QA Agents
Feb 26, 2025The deployment of Large Language Models (LLMs) in customer support is constrained by hallucination-generating false information-and the high cost of proprietary models. To address these challenges, we propose a retrieval-augmented question-answering (QA) pipeline and explore how to balance human input and automation. Using a dataset of questions about a Samsung Smart TV user manual, we demonstrate that synthetic data generated by LLMs outperforms crowdsourced data in reducing hallucination in finetuned models. We also compare self-training (fine-tuning models on their own outputs) and knowledge distillation (fine-tuning on stronger models' outputs, e.g., GPT-4o), and find that self-training achieves comparable hallucination reduction. We conjecture that this surprising finding can be attributed to increased exposure bias issues in the knowledge distillation case and support this conjecture with post hoc analysis. We also improve robustness to unanswerable questions and retrieval failures with contextualized "I don't know" responses. These findings show that scalable, cost-efficient QA systems can be built using synthetic data and self-training with open-source models, reducing reliance on proprietary tools or costly human annotations.
Smoothed Embeddings for Robust Language Models
Jan 27, 2025



Improving the safety and reliability of large language models (LLMs) is a crucial aspect of realizing trustworthy AI systems. Although alignment methods aim to suppress harmful content generation, LLMs are often still vulnerable to jailbreaking attacks that employ adversarial inputs that subvert alignment and induce harmful outputs. We propose the Randomized Embedding Smoothing and Token Aggregation (RESTA) defense, which adds random noise to the embedding vectors and performs aggregation during the generation of each output token, with the aim of better preserving semantic information. Our experiments demonstrate that our approach achieves superior robustness versus utility tradeoffs compared to the baseline defenses.
Exploring User-level Gradient Inversion with a Diffusion Prior
Sep 11, 2024



We explore user-level gradient inversion as a new attack surface in distributed learning. We first investigate existing attacks on their ability to make inferences about private information beyond training data reconstruction. Motivated by the low reconstruction quality of existing methods, we propose a novel gradient inversion attack that applies a denoising diffusion model as a strong image prior in order to enhance recovery in the large batch setting. Unlike traditional attacks, which aim to reconstruct individual samples and suffer at large batch and image sizes, our approach instead aims to recover a representative image that captures the sensitive shared semantic information corresponding to the underlying user. Our experiments with face images demonstrate the ability of our methods to recover realistic facial images along with private user attributes.
Analyzing Inference Privacy Risks Through Gradients in Machine Learning
Aug 29, 2024



In distributed learning settings, models are iteratively updated with shared gradients computed from potentially sensitive user data. While previous work has studied various privacy risks of sharing gradients, our paper aims to provide a systematic approach to analyze private information leakage from gradients. We present a unified game-based framework that encompasses a broad range of attacks including attribute, property, distributional, and user disclosures. We investigate how different uncertainties of the adversary affect their inferential power via extensive experiments on five datasets across various data modalities. Our results demonstrate the inefficacy of solely relying on data aggregation to achieve privacy against inference attacks in distributed learning. We further evaluate five types of defenses, namely, gradient pruning, signed gradient descent, adversarial perturbations, variational information bottleneck, and differential privacy, under both static and adaptive adversary settings. We provide an information-theoretic view for analyzing the effectiveness of these defenses against inference from gradients. Finally, we introduce a method for auditing attribute inference privacy, improving the empirical estimation of worst-case privacy through crafting adversarial canary records.
Variational Randomized Smoothing for Sample-Wise Adversarial Robustness
Jul 16, 2024



Randomized smoothing is a defensive technique to achieve enhanced robustness against adversarial examples which are small input perturbations that degrade the performance of neural network models. Conventional randomized smoothing adds random noise with a fixed noise level for every input sample to smooth out adversarial perturbations. This paper proposes a new variational framework that uses a per-sample noise level suitable for each input by introducing a noise level selector. Our experimental results demonstrate enhancement of empirical robustness against adversarial attacks. We also provide and analyze the certified robustness for our sample-wise smoothing method.
Efficient Differentially Private Fine-Tuning of Diffusion Models
Jun 07, 2024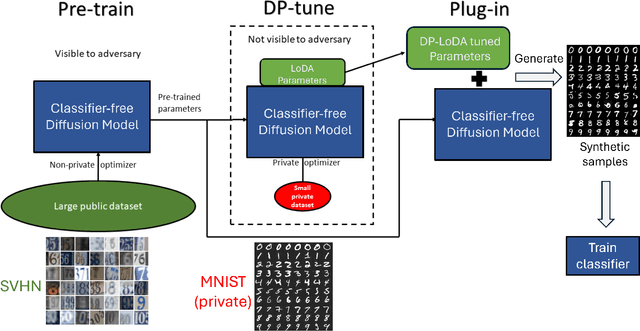
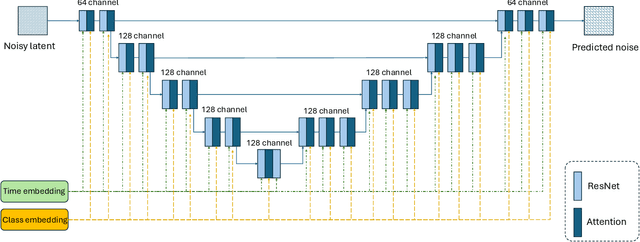
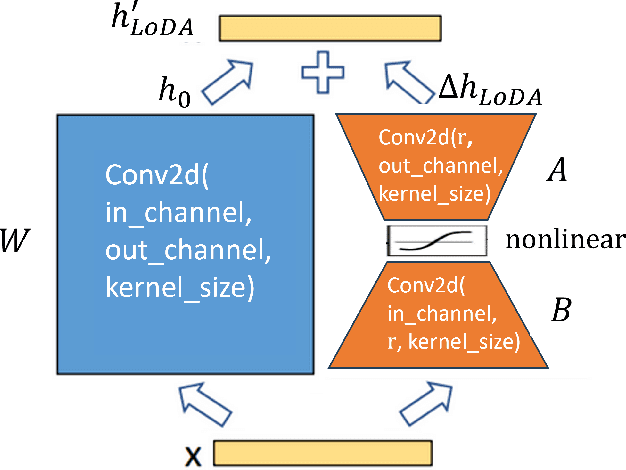

The recent developments of Diffusion Models (DMs) enable generation of astonishingly high-quality synthetic samples. Recent work showed that the synthetic samples generated by the diffusion model, which is pre-trained on public data and fully fine-tuned with differential privacy on private data, can train a downstream classifier, while achieving a good privacy-utility tradeoff. However, fully fine-tuning such large diffusion models with DP-SGD can be very resource-demanding in terms of memory usage and computation. In this work, we investigate Parameter-Efficient Fine-Tuning (PEFT) of diffusion models using Low-Dimensional Adaptation (LoDA) with Differential Privacy. We evaluate the proposed method with the MNIST and CIFAR-10 datasets and demonstrate that such efficient fine-tuning can also generate useful synthetic samples for training downstream classifiers, with guaranteed privacy protection of fine-tuning data. Our source code will be made available on GitHub.
AutoHLS: Learning to Accelerate Design Space Exploration for HLS Designs
Mar 15, 2024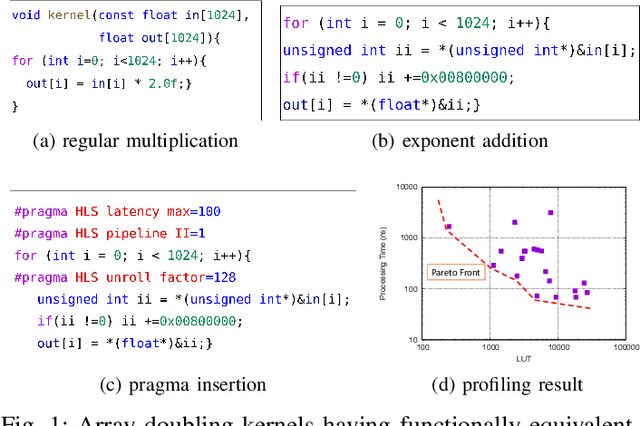



High-level synthesis (HLS) is a design flow that leverages modern language features and flexibility, such as complex data structures, inheritance, templates, etc., to prototype hardware designs rapidly. However, exploring various design space parameters can take much time and effort for hardware engineers to meet specific design specifications. This paper proposes a novel framework called AutoHLS, which integrates a deep neural network (DNN) with Bayesian optimization (BO) to accelerate HLS hardware design optimization. Our tool focuses on HLS pragma exploration and operation transformation. It utilizes integrated DNNs to predict synthesizability within a given FPGA resource budget. We also investigate the potential of emerging quantum neural networks (QNNs) instead of classical DNNs for the AutoHLS pipeline. Our experimental results demonstrate up to a 70-fold speedup in exploration time.
Why Does Differential Privacy with Large Epsilon Defend Against Practical Membership Inference Attacks?
Feb 14, 2024



For small privacy parameter $\epsilon$, $\epsilon$-differential privacy (DP) provides a strong worst-case guarantee that no membership inference attack (MIA) can succeed at determining whether a person's data was used to train a machine learning model. The guarantee of DP is worst-case because: a) it holds even if the attacker already knows the records of all but one person in the data set; and b) it holds uniformly over all data sets. In practical applications, such a worst-case guarantee may be overkill: practical attackers may lack exact knowledge of (nearly all of) the private data, and our data set might be easier to defend, in some sense, than the worst-case data set. Such considerations have motivated the industrial deployment of DP models with large privacy parameter (e.g. $\epsilon \geq 7$), and it has been observed empirically that DP with large $\epsilon$ can successfully defend against state-of-the-art MIAs. Existing DP theory cannot explain these empirical findings: e.g., the theoretical privacy guarantees of $\epsilon \geq 7$ are essentially vacuous. In this paper, we aim to close this gap between theory and practice and understand why a large DP parameter can prevent practical MIAs. To tackle this problem, we propose a new privacy notion called practical membership privacy (PMP). PMP models a practical attacker's uncertainty about the contents of the private data. The PMP parameter has a natural interpretation in terms of the success rate of a practical MIA on a given data set. We quantitatively analyze the PMP parameter of two fundamental DP mechanisms: the exponential mechanism and Gaussian mechanism. Our analysis reveals that a large DP parameter often translates into a much smaller PMP parameter, which guarantees strong privacy against practical MIAs. Using our findings, we offer principled guidance for practitioners in choosing the DP parameter.
Stabilizing Subject Transfer in EEG Classification with Divergence Estimation
Oct 12, 2023Classification models for electroencephalogram (EEG) data show a large decrease in performance when evaluated on unseen test sub jects. We reduce this performance decrease using new regularization techniques during model training. We propose several graphical models to describe an EEG classification task. From each model, we identify statistical relationships that should hold true in an idealized training scenario (with infinite data and a globally-optimal model) but that may not hold in practice. We design regularization penalties to enforce these relationships in two stages. First, we identify suitable proxy quantities (divergences such as Mutual Information and Wasserstein-1) that can be used to measure statistical independence and dependence relationships. Second, we provide algorithms to efficiently estimate these quantities during training using secondary neural network models. We conduct extensive computational experiments using a large benchmark EEG dataset, comparing our proposed techniques with a baseline method that uses an adversarial classifier. We find our proposed methods significantly increase balanced accuracy on test subjects and decrease overfitting. The proposed methods exhibit a larger benefit over a greater range of hyperparameters than the baseline method, with only a small computational cost at training time. These benefits are largest when used for a fixed training period, though there is still a significant benefit for a subset of hyperparameters when our techniques are used in conjunction with early stopping regularization.
Learning to Learn Quantum Turbo Detection
May 17, 2022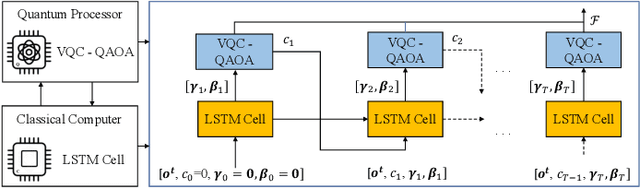
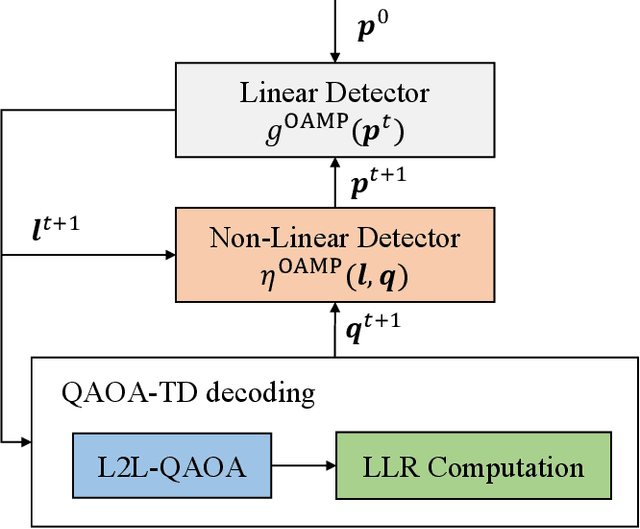
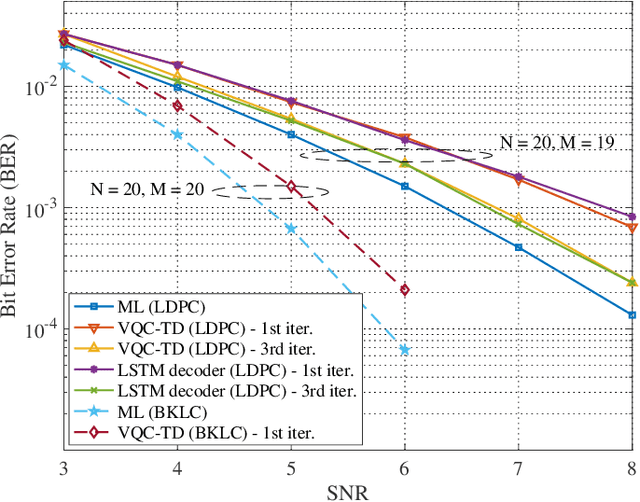
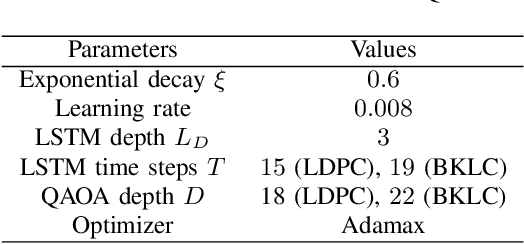
This paper investigates a turbo receiver employing a variational quantum circuit (VQC). The VQC is configured with an ansatz of the quantum approximate optimization algorithm (QAOA). We propose a 'learning to learn' (L2L) framework to optimize the turbo VQC decoder such that high fidelity soft-decision output is generated. Besides demonstrating the proposed algorithm's computational complexity, we show that the L2L VQC turbo decoder can achieve an excellent performance close to the optimal maximum-likelihood performance in a multiple-input multiple-output system.