 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTS-Bench: Benchmarking Graph Coarsening Trade-offs for GNNs in Clock Tree Synthesis
Feb 22, 2026Graph Neural Networks (GNNs) are increasingly explored for physical design analysis in Electronic Design Automation, particularly for modeling Clock Tree Synthesis behavior such as clock skew and buffering complexity. However, practical deployment remains limited due to the prohibitive memory and runtime cost of operating on raw gate-level netlists. Graph coarsening is commonly used to improve scalability, yet its impact on CTS-critical learning objectives is not well characterized. This paper introduces CTS-Bench, a benchmark suite for systematically evaluating the trade-offs between graph coarsening, prediction accuracy, and computational efficiency in GNN-based CTS analysis. CTS-Bench consists of 4,860 converged physical design solutions spanning five architectures and provides paired raw gate-level and clustered graph representations derived from post-placement designs. Using clock skew prediction as a representative CTS task, we demonstrate a clear accuracy-efficiency trade-off. While graph coarsening reduces GPU memory usage by up to 17.2x and accelerates training by up to 3x, it also removes structural information essential for modeling clock distribution, frequently resulting in negative $R^2$ scores under zero-shot evaluation. Our findings indicate that generic graph clustering techniques can fundamentally compromise CTS learning objectives, even when global physical metrics remain unchanged. CTS-Bench enables principled evaluation of CTS-aware graph coarsening strategies, supports benchmarking of GNN architectures and accelerators under realistic physical design constraints, and provides a foundation for developing learning-assisted CTS analysis and optimization techniques.
EdgeProfiler: A Fast Profiling Framework for Lightweight LLMs on Edge Using Analytical Model
Jun 06, 2025This paper introduces EdgeProfiler, a fast profiling framework designed for evaluating lightweight Large Language Models (LLMs) on edge systems. While LLMs offer remarkable capabilities in natural language understanding and generation, their high computational, memory, and power requirements often confine them to cloud environments. EdgeProfiler addresses these challenges by providing a systematic methodology for assessing LLM performance in resource-constrained edge settings. The framework profiles compact LLMs, including TinyLLaMA, Gemma3.1B, Llama3.2-1B, and DeepSeek-r1-1.5B, using aggressive quantization techniques and strict memory constraints. Analytical modeling is used to estimate latency, FLOPs, and energy consumption. The profiling reveals that 4-bit quantization reduces model memory usage by approximately 60-70%, while maintaining accuracy within 2-5% of full-precision baselines. Inference speeds are observed to improve by 2-3x compared to FP16 baselines across various edge devices. Power modeling estimates a 35-50% reduction in energy consumption for INT4 configurations, enabling practical deployment on hardware such as Raspberry Pi 4/5 and Jetson Orin Nano Super. Our findings emphasize the importance of efficient profiling tailored to lightweight LLMs in edge environments, balancing accuracy, energy efficiency, and computational feasibility.
Data Augmentation for Image Classification using Generative AI
Aug 31, 2024Scaling laws dictate that the performance of AI models is proportional to the amount of available data. Data augmentation is a promising solution to expanding the dataset size. Traditional approaches focused on augmentation using rotation, translation, and resizing. Recent approaches use generative AI models to improve dataset diversity. However, the generative methods struggle with issues such as subject corruption and the introduction of irrelevant artifacts. In this paper, we propose the Automated Generative Data Augmentation (AGA). The framework combines the utility of large language models (LLMs), diffusion models, and segmentation models to augment data. AGA preserves foreground authenticity while ensuring background diversity. Specific contributions include: i) segment and superclass based object extraction, ii) prompt diversity with combinatorial complexity using prompt decomposition, and iii) affine subject manipulation. We evaluate AGA against state-of-the-art (SOTA) techniques on three representative datasets, ImageNet, CUB, and iWildCam. The experimental evaluation demonstrates an accuracy improvement of 15.6% and 23.5% for in and out-of-distribution data compared to baseline models, respectively. There is also a 64.3% improvement in SIC score compared to the baselines.
AutoHLS: Learning to Accelerate Design Space Exploration for HLS Designs
Mar 15, 2024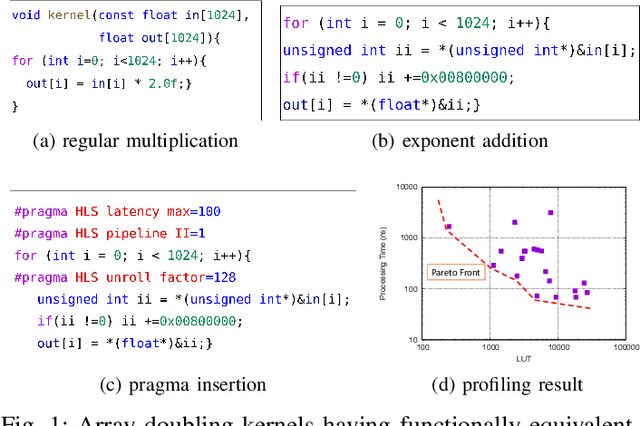



High-level synthesis (HLS) is a design flow that leverages modern language features and flexibility, such as complex data structures, inheritance, templates, etc., to prototype hardware designs rapidly. However, exploring various design space parameters can take much time and effort for hardware engineers to meet specific design specifications. This paper proposes a novel framework called AutoHLS, which integrates a deep neural network (DNN) with Bayesian optimization (BO) to accelerate HLS hardware design optimization. Our tool focuses on HLS pragma exploration and operation transformation. It utilizes integrated DNNs to predict synthesizability within a given FPGA resource budget. We also investigate the potential of emerging quantum neural networks (QNNs) instead of classical DNNs for the AutoHLS pipeline. Our experimental results demonstrate up to a 70-fold speedup in exploration time.
Mining SoC Message Flows with Attention Model
Sep 12, 2022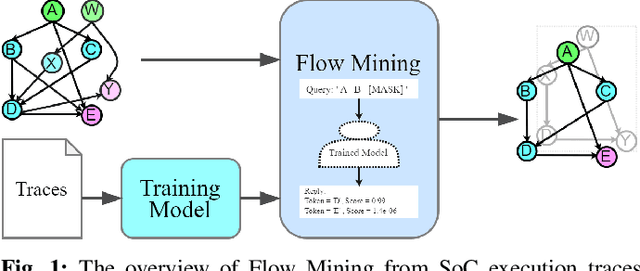

High-quality system-level message flow specifications are necessary for comprehensive validation of system-on-chip (SoC) designs. However, manual development and maintenance of such specifications are daunting tasks. We propose a disruptive method that utilizes deep sequence modeling with the attention mechanism to infer accurate flow specifications from SoC communication traces. The proposed method can overcome the inherent complexity of SoC traces induced by the concurrent executions of SoC designs that existing mining tools often find extremely challenging. We conduct experiments on five highly concurrent traces and find that the proposed approach outperforms several existing state-of-the-art trace mining tools.
Deep Bidirectional Transformers for SoC Flow Specification Mining
Mar 09, 2022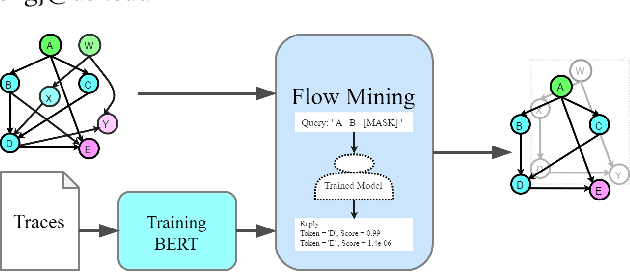

High-quality system-level message flow specifications can lead to comprehensive validation of system-on-chip (SoC) designs. We propose a disruptive method that utilizes an attention mechanism to produce accurate flow specifications from SoC IP communication traces. The proposed method can overcome the inherent complexity of SoC traces induced by the concurrency and parallelism of multicore designs that existing flow specification mining tools often find extremely challenging. Experiments on highly interleaved traces show promising flow reconstruction compared to several tools dedicated to the flow specification mining problem.
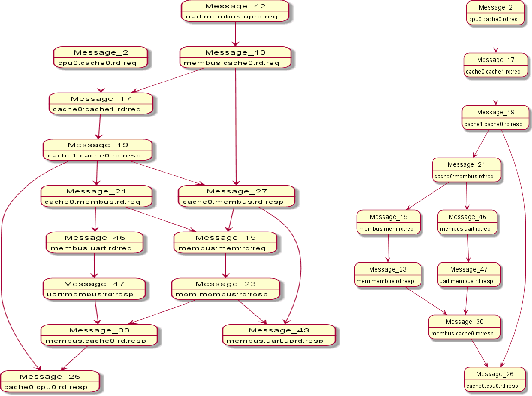
Model Synthesis for Communication Traces of System-on-Chip Designs
Feb 13, 2021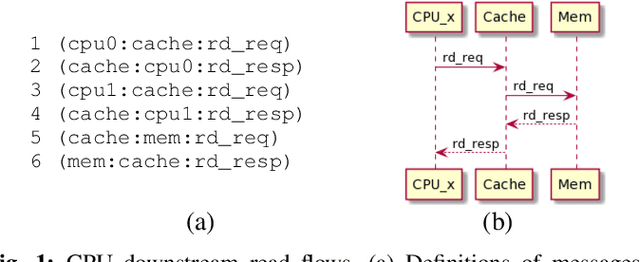

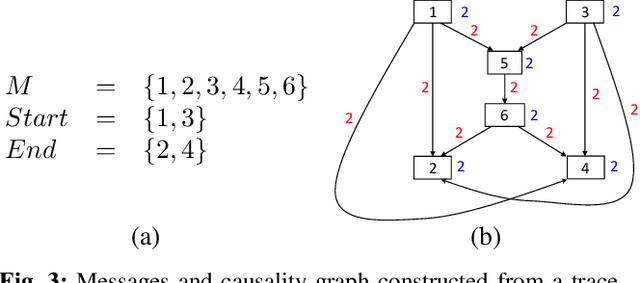

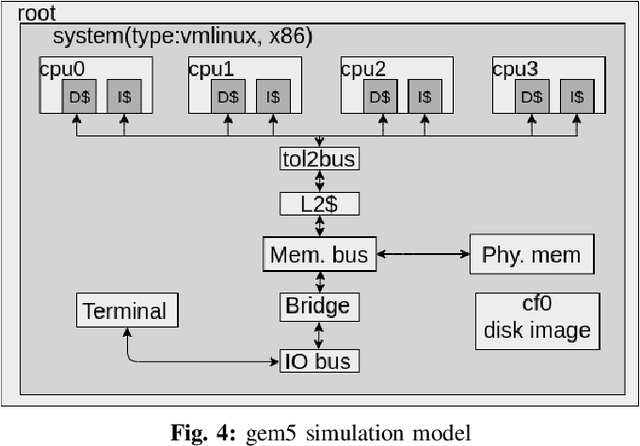
Concise and abstract models of system-level behaviors are invaluable in design analysis, testing, and validation. In this paper, we consider the problem of inferring models from communication traces of system-on-chip~(SoC) designs. The traces capture communications among different blocks of a SoC design in terms of messages exchanged. The extracted models characterize the system-level communication protocols governing how blocks exchange messages, and coordinate with each other to realize various system functions. In this paper, the above problem is formulated as a constraint satisfaction problem, which is then fed to a SMT solver. The solutions returned by the SMT solver are used to extract the models that accept the input traces. In the experiments, we demonstrate the proposed approach with traces collected from a transaction-level simulation model of a multicore SoC design and traces of a more detailed multicore SoC design developed in GEM5 environment.