 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriMind: Agentic LLM for Automated Verilog Generation with a Novel Evaluation Metric
Mar 15, 2025



Designing Verilog modules requires meticulous attention to correctness, efficiency, and adherence to design specifications. However, manually writing Verilog code remains a complex and time-consuming task that demands both expert knowledge and iterative refinement. Leveraging recent advancements in large language models (LLMs) and their structured text generation capabilities, we propose VeriMind, an agentic LLM framework for Verilog code generation that significantly automates and optimizes the synthesis process. Unlike traditional LLM-based code generators, VeriMind employs a structured reasoning approach: given a user-provided prompt describing design requirements, the system first formulates a detailed train of thought before the final Verilog code is generated. This multi-step methodology enhances interpretability, accuracy, and adaptability in hardware design. In addition, we introduce a novel evaluation metric-pass@ARC-which combines the conventional pass@k measure with Average Refinement Cycles (ARC) to capture both success rate and the efficiency of iterative refinement. Experimental results on diverse hardware design tasks demonstrated that our approach achieved up to $8.3\%$ improvement on pass@k metric and $8.1\%$ on pass@ARC metric. These findings underscore the transformative potential of agentic LLMs in automated hardware design, RTL development, and digital system synthesis.
PyraNet: A Multi-Layered Hierarchical Dataset for Verilog
Dec 09, 2024



Recently, there has been a growing interest in leveraging Large Language Models for Verilog code generation. However, the current quality of the generated Verilog code remains suboptimal. This is largely due to the absence of well-defined, well-organized datasets with high-quality samples, as well as a lack of innovative fine-tuning methods and models specifically trained on Verilog. In this paper, we introduce a novel open-source dataset and a corresponding fine-tuning technique, which utilizes a multi-layered structure that we refer to as PyraNet. Our experiments demonstrate that employing the proposed dataset and fine-tuning approach leads to a more accurate fine-tuned model, producing syntactically and functionally correct Verilog code. The evaluation results show improvements by up-to $32.6\%$ in comparison to the CodeLlama-7B baseline model and up-to $16.7\%$ in comparison to the state-of-the-art models using VerilogEval evaluation platform.
Forward and Reverse Converters for the Moduli-Set $\{2^{2q+1},2^q+2^{q-1}\pm1\}$
Nov 19, 2024



Modulo-$(2^q + 2^{q-1} \pm 1)$ adders have recently been implemented using the regular parallel prefix (RPP) architecture, matching the speed of the widely used modulo-$(2^q \pm 1)$ RPP adders. Consequently, we introduce a new moduli set $\tau^+ = \{2^{2q+1}, 2^q + 2^{q-1} \pm 1\}$, with over $(2^{q+2}) \times$ dynamic range and adder speeds comparable to the conventional $\tau = \{2^q, 2^q \pm 1\}$ set. However, to fully leverage $\tau^+$ in residue number system applications, a complete set of circuitries is necessary. This work focuses on the design and implementation of the forward and reverse converters for $\tau^+$. These converters consist of four and seven levels of carry-save addition units, culminating in a final modulo-$(2^q + 2^{q-1} \pm 1)$ and modulo-$(2^{2q+1} + 2^{2q-2} - 1)$ adder, respectively. Through analytical evaluations and circuit simulations, we demonstrate that the overall performance of a sequence of operations including residue generation -- including residue generation, $k$ additions, and reverse conversion -- using $\tau^+$ surpasses that of $\tau$ when $k$ exceeds a certain practical threshold.
A Multi-Expert Large Language Model Architecture for Verilog Code Generation
Apr 11, 2024Recently, there has been a surging interest in using large language models (LLMs) for Verilog code generation. However, the existing approaches are limited in terms of the quality of the generated Verilog code. To address such limitations, this paper introduces an innovative multi-expert LLM architecture for Verilog code generation (MEV-LLM). Our architecture uniquely integrates multiple LLMs, each specifically fine-tuned with a dataset that is categorized with respect to a distinct level of design complexity. It allows more targeted learning, directly addressing the nuances of generating Verilog code for each category. Empirical evidence from experiments highlights notable improvements in terms of the percentage of generated Verilog outputs that are syntactically and functionally correct. These findings underscore the efficacy of our approach, promising a forward leap in the field of automated hardware design through machine learning.
Mining SoC Message Flows with Attention Model
Sep 12, 2022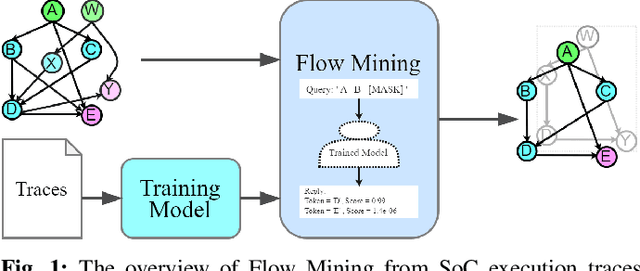

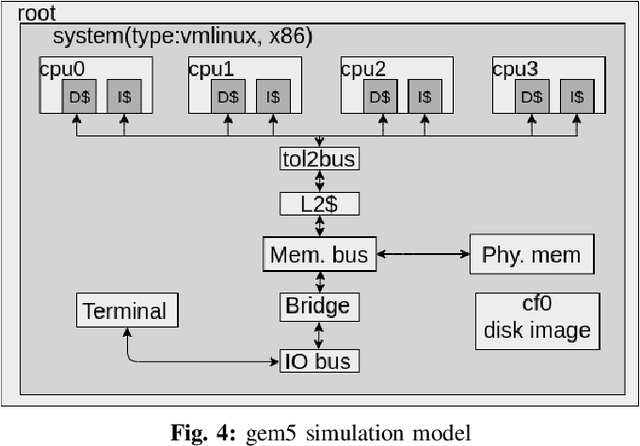
High-quality system-level message flow specifications are necessary for comprehensive validation of system-on-chip (SoC) designs. However, manual development and maintenance of such specifications are daunting tasks. We propose a disruptive method that utilizes deep sequence modeling with the attention mechanism to infer accurate flow specifications from SoC communication traces. The proposed method can overcome the inherent complexity of SoC traces induced by the concurrent executions of SoC designs that existing mining tools often find extremely challenging. We conduct experiments on five highly concurrent traces and find that the proposed approach outperforms several existing state-of-the-art trace mining tools.