 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking the Matrix: Nullspace Steering for Controlled Model Subversion
Apr 11, 2026Large language models remain vulnerable to jailbreak attacks -- inputs designed to bypass safety mechanisms and elicit harmful responses -- despite advances in alignment and instruction tuning. We propose Head-Masked Nullspace Steering (HMNS), a circuit-level intervention that (i) identifies attention heads most causally responsible for a model's default behavior, (ii) suppresses their write paths via targeted column masking, and (iii) injects a perturbation constrained to the orthogonal complement of the muted subspace. HMNS operates in a closed-loop detection-intervention cycle, re-identifying causal heads and reapplying interventions across multiple decoding attempts. Across multiple jailbreak benchmarks, strong safety defenses, and widely used language models, HMNS attains state-of-the-art attack success rates with fewer queries than prior methods. Ablations confirm that nullspace-constrained injection, residual norm scaling, and iterative re-identification are key to its effectiveness. To our knowledge, this is the first jailbreak method to leverage geometry-aware, interpretability-informed interventions, highlighting a new paradigm for controlled model steering and adversarial safety circumvention.
Grammar-Forced Translation of Natural Language to Temporal Logic using LLMs
Dec 18, 2025



Translating natural language (NL) into a formal language such as temporal logic (TL) is integral for human communication with robots and autonomous systems. State-of-the-art approaches decompose the task into a lifting of atomic propositions (APs) phase and a translation phase. However, existing methods struggle with accurate lifting, the existence of co-references, and learning from limited data. In this paper, we propose a framework for NL to TL translation called Grammar Forced Translation (GraFT). The framework is based on the observation that previous work solves both the lifting and translation steps by letting a language model iteratively predict tokens from its full vocabulary. In contrast, GraFT reduces the complexity of both tasks by restricting the set of valid output tokens from the full vocabulary to only a handful in each step. The solution space reduction is obtained by exploiting the unique properties of each problem. We also provide a theoretical justification for why the solution space reduction leads to more efficient learning. We evaluate the effectiveness of GraFT using the CW, GLTL, and Navi benchmarks. Compared with state-of-the-art translation approaches, it can be observed that GraFT the end-to-end translation accuracy by 5.49% and out-of-domain translation accuracy by 14.06% on average.
Verifiable Natural Language to Linear Temporal Logic Translation: A Benchmark Dataset and Evaluation Suite
Jul 01, 2025



Empirical evaluation of state-of-the-art natural-language (NL) to temporal-logic (TL) translation systems reveals near-perfect performance on existing benchmarks. However, current studies measure only the accuracy of the translation of NL logic into formal TL, ignoring a system's capacity to ground atomic propositions into new scenarios or environments. This is a critical feature, necessary for the verification of resulting formulas in a concrete state space. Consequently, most NL-to-TL translation frameworks propose their own bespoke dataset in which the correct grounding is known a-priori, inflating performance metrics and neglecting the need for extensible, domain-general systems. In this paper, we introduce the Verifiable Linear Temporal Logic Benchmark ( VLTL-Bench), a unifying benchmark that measures verification and verifiability of automated NL-to-LTL translation. The dataset consists of three unique state spaces and thousands of diverse natural language specifications and corresponding formal specifications in temporal logic. Moreover, the benchmark contains sample traces to validate the temporal logic expressions. While the benchmark directly supports end-to-end evaluation, we observe that many frameworks decompose the process into i) lifting, ii) grounding, iii) translation, and iv) verification. The benchmark provides ground truths after each of these steps to enable researches to improve and evaluate different substeps of the overall problem. To encourage methodologically sound advances in verifiable NL-to-LTL translation approaches, we release VLTL-Bench here: https://www.kaggle.com/datasets/dubascudes/vltl bench.
Circuit Partitioning Using Large Language Models for Quantum Compilation and Simulations
May 12, 2025We are in the midst of the noisy intermediate-scale quantum (NISQ) era, where quantum computers are limited by noisy gates, some of which are more error-prone than others and can render the final computation incomprehensible. Quantum circuit compilation algorithms attempt to minimize these noisy gates when mapping quantum algorithms onto quantum hardware but face computational challenges that restrict their application to circuits with no more than 5-6 qubits, necessitating the need to partition large circuits before the application of noisy quantum gate minimization algorithms. The existing generation of these algorithms is heuristic in nature and does not account for downstream gate minimization tasks. Large language models (LLMs) have the potential to change this and help improve quantum circuit partitions. This paper investigates the use of LLMs, such as Llama and Mistral, for partitioning quantum circuits by capitalizing on their abilities to understand and generate code, including QASM. Specifically, we teach LLMs to partition circuits using the quick partition approach of the Berkeley Quantum Synthesis Toolkit. Through experimental evaluations, we show that careful fine-tuning of open source LLMs enables us to obtain an accuracy of 53.4% for the partition task while over-the-shelf LLMs are unable to correctly partition circuits, using standard 1-shot and few-shot training approaches.
Jailbreaking Large Language Models with Symbolic Mathematics
Sep 17, 2024



Recent advancements in AI safety have led to increased efforts in training and red-teaming large language models (LLMs) to mitigate unsafe content generation. However, these safety mechanisms may not be comprehensive, leaving potential vulnerabilities unexplored. This paper introduces MathPrompt, a novel jailbreaking technique that exploits LLMs' advanced capabilities in symbolic mathematics to bypass their safety mechanisms. By encoding harmful natural language prompts into mathematical problems, we demonstrate a critical vulnerability in current AI safety measures. Our experiments across 13 state-of-the-art LLMs reveal an average attack success rate of 73.6\%, highlighting the inability of existing safety training mechanisms to generalize to mathematically encoded inputs. Analysis of embedding vectors shows a substantial semantic shift between original and encoded prompts, helping explain the attack's success. This work emphasizes the importance of a holistic approach to AI safety, calling for expanded red-teaming efforts to develop robust safeguards across all potential input types and their associated risks.
AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing
Sep 16, 2024Recent advancements in automatic code generation using large language models (LLMs) have brought us closer to fully automated secure software development. However, existing approaches often rely on a single agent for code generation, which struggles to produce secure, vulnerability-free code. Traditional program synthesis with LLMs has primarily focused on functional correctness, often neglecting critical dynamic security implications that happen during runtime. To address these challenges, we propose AutoSafeCoder, a multi-agent framework that leverages LLM-driven agents for code generation, vulnerability analysis, and security enhancement through continuous collaboration. The framework consists of three agents: a Coding Agent responsible for code generation, a Static Analyzer Agent identifying vulnerabilities, and a Fuzzing Agent performing dynamic testing using a mutation-based fuzzing approach to detect runtime errors. Our contribution focuses on ensuring the safety of multi-agent code generation by integrating dynamic and static testing in an iterative process during code generation by LLM that improves security. Experiments using the SecurityEval dataset demonstrate a 13% reduction in code vulnerabilities compared to baseline LLMs, with no compromise in functionality.
Data Augmentation for Image Classification using Generative AI
Aug 31, 2024Scaling laws dictate that the performance of AI models is proportional to the amount of available data. Data augmentation is a promising solution to expanding the dataset size. Traditional approaches focused on augmentation using rotation, translation, and resizing. Recent approaches use generative AI models to improve dataset diversity. However, the generative methods struggle with issues such as subject corruption and the introduction of irrelevant artifacts. In this paper, we propose the Automated Generative Data Augmentation (AGA). The framework combines the utility of large language models (LLMs), diffusion models, and segmentation models to augment data. AGA preserves foreground authenticity while ensuring background diversity. Specific contributions include: i) segment and superclass based object extraction, ii) prompt diversity with combinatorial complexity using prompt decomposition, and iii) affine subject manipulation. We evaluate AGA against state-of-the-art (SOTA) techniques on three representative datasets, ImageNet, CUB, and iWildCam. The experimental evaluation demonstrates an accuracy improvement of 15.6% and 23.5% for in and out-of-distribution data compared to baseline models, respectively. There is also a 64.3% improvement in SIC score compared to the baselines.
Development and Validation of Fully Automatic Deep Learning-Based Algorithms for Immunohistochemistry Reporting of Invasive Breast Ductal Carcinoma
Jun 16, 2024



Immunohistochemistry (IHC) analysis is a well-accepted and widely used method for molecular subtyping, a procedure for prognosis and targeted therapy of breast carcinoma, the most common type of tumor affecting women. There are four molecular biomarkers namely progesterone receptor (PR), estrogen receptor (ER), antigen Ki67, and human epidermal growth factor receptor 2 (HER2) whose assessment is needed under IHC procedure to decide prognosis as well as predictors of response to therapy. However, IHC scoring is based on subjective microscopic examination of tumor morphology and suffers from poor reproducibility, high subjectivity, and often incorrect scoring in low-score cases. In this paper, we present, a deep learning-based semi-supervised trained, fully automatic, decision support system (DSS) for IHC scoring of invasive ductal carcinoma. Our system automatically detects the tumor region removing artifacts and scores based on Allred standard. The system is developed using 3 million pathologist-annotated image patches from 300 slides, fifty thousand in-house cell annotations, and forty thousand pixels marking of HER2 membrane. We have conducted multicentric trials at four centers with three different types of digital scanners in terms of percentage agreement with doctors. And achieved agreements of 95, 92, 88 and 82 percent for Ki67, HER2, ER, and PR stain categories, respectively. In addition to overall accuracy, we found that there is 5 percent of cases where pathologist have changed their score in favor of algorithm score while reviewing with detailed algorithmic analysis. Our approach could improve the accuracy of IHC scoring and subsequent therapy decisions, particularly where specialist expertise is unavailable. Our system is highly modular. The proposed algorithm modules can be used to develop DSS for other cancer types.
Multi-Stain Multi-Level Convolutional Network for Multi-Tissue Breast Cancer Image Segmentation
Jun 09, 2024



Digital pathology and microscopy image analysis are widely employed in the segmentation of digitally scanned IHC slides, primarily to identify cancer and pinpoint regions of interest (ROI) indicative of tumor presence. However, current ROI segmentation models are either stain-specific or suffer from the issues of stain and scanner variance due to different staining protocols or modalities across multiple labs. Also, tissues like Ductal Carcinoma in Situ (DCIS), acini, etc. are often classified as Tumors due to their structural similarities and color compositions. In this paper, we proposed a novel convolutional neural network (CNN) based Multi-class Tissue Segmentation model for histopathology whole-slide Breast slides which classify tumors and segments other tissue regions such as Ducts, acini, DCIS, Squamous epithelium, Blood Vessels, Necrosis, etc. as a separate class. Our unique pixel-aligned non-linear merge across spatial resolutions empowers models with both local and global fields of view for accurate detection of various classes. Our proposed model is also able to separate bad regions such as folds, artifacts, blurry regions, bubbles, etc. from tissue regions using multi-level context from different resolutions of WSI. Multi-phase iterative training with context-aware augmentation and increasing noise was used to efficiently train a multi-stain generic model with partial and noisy annotations from 513 slides. Our training pipeline used 12 million patches generated using context-aware augmentations which made our model stain and scanner invariant across data sources. To extrapolate stain and scanner invariance, our model was evaluated on 23000 patches which were for a completely new stain (Hematoxylin and Eosin) from a completely new scanner (Motic) from a different lab. The mean IOU was 0.72 which is on par with model performance on other data sources and scanners.
Towards a Game-theoretic Understanding of Explanation-based Membership Inference Attacks
Apr 10, 2024
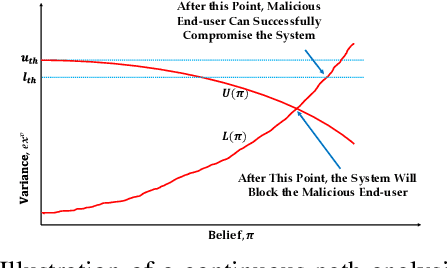
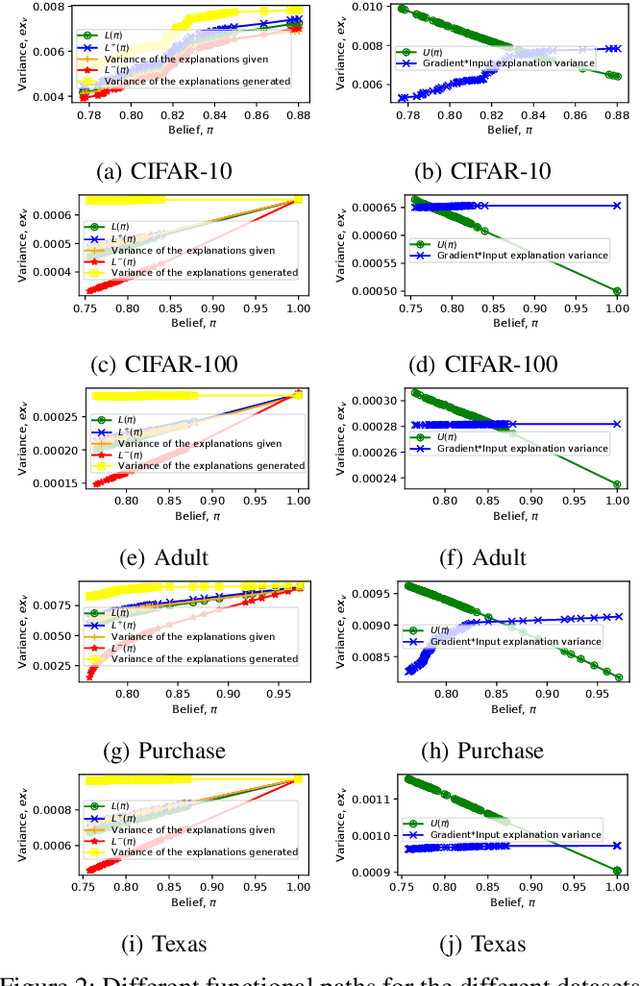
Model explanations improve the transparency of black-box machine learning (ML) models and their decisions; however, they can also be exploited to carry out privacy threats such as membership inference attacks (MIA). Existing works have only analyzed MIA in a single "what if" interaction scenario between an adversary and the target ML model; thus, it does not discern the factors impacting the capabilities of an adversary in launching MIA in repeated interaction settings. Additionally, these works rely on assumptions about the adversary's knowledge of the target model's structure and, thus, do not guarantee the optimality of the predefined threshold required to distinguish the members from non-members. In this paper, we delve into the domain of explanation-based threshold attacks, where the adversary endeavors to carry out MIA attacks by leveraging the variance of explanations through iterative interactions with the system comprising of the target ML model and its corresponding explanation method. We model such interactions by employing a continuous-time stochastic signaling game framework. In our framework, an adversary plays a stopping game, interacting with the system (having imperfect information about the type of an adversary, i.e., honest or malicious) to obtain explanation variance information and computing an optimal threshold to determine the membership of a datapoint accurately. First, we propose a sound mathematical formulation to prove that such an optimal threshold exists, which can be used to launch MIA. Then, we characterize the conditions under which a unique Markov perfect equilibrium (or steady state) exists in this dynamic system. By means of a comprehensive set of simulations of the proposed game model, we assess different factors that can impact the capability of an adversary to launch MIA in such repeated interaction settings.