 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reverse Engineering: Investigating and Benchmarking Large Language Models for Vulnerability Analysis in Decompiled Binaries
Nov 07, 2024Security experts reverse engineer (decompile) binary code to identify critical security vulnerabilities. The limited access to source code in vital systems - such as firmware, drivers, and proprietary software used in Critical Infrastructures (CI) - makes this analysis even more crucial on the binary level. Even with available source code, a semantic gap persists after compilation between the source and the binary code executed by the processor. This gap may hinder the detection of vulnerabilities in source code. That being said, current research on Large Language Models (LLMs) overlooks the significance of decompiled binaries in this area by focusing solely on source code. In this work, we are the first to empirically uncover the substantial semantic limitations of state-of-the-art LLMs when it comes to analyzing vulnerabilities in decompiled binaries, largely due to the absence of relevant datasets. To bridge the gap, we introduce DeBinVul, a novel decompiled binary code vulnerability dataset. Our dataset is multi-architecture and multi-optimization, focusing on C/C++ due to their wide usage in CI and association with numerous vulnerabilities. Specifically, we curate 150,872 samples of vulnerable and non-vulnerable decompiled binary code for the task of (i) identifying; (ii) classifying; (iii) describing vulnerabilities; and (iv) recovering function names in the domain of decompiled binaries. Subsequently, we fine-tune state-of-the-art LLMs using DeBinVul and report on a performance increase of 19%, 24%, and 21% in the capabilities of CodeLlama, Llama3, and CodeGen2 respectively, in detecting binary code vulnerabilities. Additionally, using DeBinVul, we report a high performance of 80-90% on the vulnerability classification task. Furthermore, we report improved performance in function name recovery and vulnerability description tasks.
AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing
Sep 16, 2024Recent advancements in automatic code generation using large language models (LLMs) have brought us closer to fully automated secure software development. However, existing approaches often rely on a single agent for code generation, which struggles to produce secure, vulnerability-free code. Traditional program synthesis with LLMs has primarily focused on functional correctness, often neglecting critical dynamic security implications that happen during runtime. To address these challenges, we propose AutoSafeCoder, a multi-agent framework that leverages LLM-driven agents for code generation, vulnerability analysis, and security enhancement through continuous collaboration. The framework consists of three agents: a Coding Agent responsible for code generation, a Static Analyzer Agent identifying vulnerabilities, and a Fuzzing Agent performing dynamic testing using a mutation-based fuzzing approach to detect runtime errors. Our contribution focuses on ensuring the safety of multi-agent code generation by integrating dynamic and static testing in an iterative process during code generation by LLM that improves security. Experiments using the SecurityEval dataset demonstrate a 13% reduction in code vulnerabilities compared to baseline LLMs, with no compromise in functionality.
Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs
Sep 01, 2024



With the recent unprecedented advancements in Artificial Intelligence (AI) computing, progress in Large Language Models (LLMs) is accelerating rapidly, presenting challenges in establishing clear guidelines, particularly in the field of security. That being said, we thoroughly identify and describe three main technical challenges in the security and software engineering literature that spans the entire LLM workflow, namely; \textbf{\textit{(i)}} Data Collection and Labeling; \textbf{\textit{(ii)}} System Design and Learning; and \textbf{\textit{(iii)}} Performance Evaluation. Building upon these challenges, this paper introduces \texttt{SecRepair}, an instruction-based LLM system designed to reliably \textit{identify}, \textit{describe}, and automatically \textit{repair} vulnerable source code. Our system is accompanied by a list of actionable guides on \textbf{\textit{(i)}} Data Preparation and Augmentation Techniques; \textbf{\textit{(ii)}} Selecting and Adapting state-of-the-art LLM Models; \textbf{\textit{(iii)}} Evaluation Procedures. \texttt{SecRepair} uses a reinforcement learning-based fine-tuning with a semantic reward that caters to the functionality and security aspects of the generated code. Our empirical analysis shows that \texttt{SecRepair} achieves a \textit{12}\% improvement in security code repair compared to other LLMs when trained using reinforcement learning. Furthermore, we demonstrate the capabilities of \texttt{SecRepair} in generating reliable, functional, and compilable security code repairs against real-world test cases using automated evaluation metrics.
Unintentional Security Flaws in Code: Automated Defense via Root Cause Analysis
Aug 30, 2024



Software security remains a critical concern, particularly as junior developers, often lacking comprehensive knowledge of security practices, contribute to codebases. While there are tools to help developers proactively write secure code, their actual effectiveness in helping developers fix their vulnerable code remains largely unmeasured. Moreover, these approaches typically focus on classifying and localizing vulnerabilities without highlighting the specific code segments that are the root cause of the issues, a crucial aspect for developers seeking to fix their vulnerable code. To address these challenges, we conducted a comprehensive study evaluating the efficacy of existing methods in helping junior developers secure their code. Our findings across five types of security vulnerabilities revealed that current tools enabled developers to secure only 36.2\% of vulnerable code. Questionnaire results from these participants further indicated that not knowing the code that was the root cause of the vulnerability was one of their primary challenges in repairing the vulnerable code. Informed by these insights, we developed an automated vulnerability root cause (RC) toolkit called T5-RCGCN, that combines T5 language model embeddings with a graph convolutional network (GCN) for vulnerability classification and localization. Additionally, we integrated DeepLiftSHAP to identify the code segments that were the root cause of the vulnerability. We tested T5-RCGCN with 56 junior developers across three datasets, showing a 28.9\% improvement in code security compared to previous methods. Developers using the tool also gained a deeper understanding of vulnerability root causes, resulting in a 17.0\% improvement in their ability to secure code independently. These results demonstrate the tool's potential for both immediate security enhancement and long-term developer skill growth.
Code Security Vulnerability Repair Using Reinforcement Learning with Large Language Models
Jan 30, 2024With the recent advancement of Large Language Models (LLMs), generating functionally correct code has become less complicated for a wide array of developers. While using LLMs has sped up the functional development process, it poses a heavy risk to code security. Code generation with proper security measures using LLM is a significantly more challenging task than functional code generation. Security measures may include adding a pair of lines of code with the original code, consisting of null pointer checking or prepared statements for SQL injection prevention. Currently, available code repair LLMs generate code repair by supervised fine-tuning, where the model looks at cross-entropy loss. However, the original and repaired codes are mostly similar in functionality and syntactically, except for a few (1-2) lines, which act as security measures. This imbalance between the lines needed for security measures and the functional code enforces the supervised fine-tuned model to prioritize generating functional code without adding proper security measures, which also benefits the model by resulting in minimal loss. Therefore, in this work, for security hardening and strengthening of generated code from LLMs, we propose a reinforcement learning-based method for program-specific repair with the combination of semantic and syntactic reward mechanisms that focus heavily on adding security and functional measures in the code, respectively.
LLM-Powered Code Vulnerability Repair with Reinforcement Learning and Semantic Reward
Jan 07, 2024



In software development, the predominant emphasis on functionality often supersedes security concerns, a trend gaining momentum with AI-driven automation tools like GitHub Copilot. These tools significantly improve developers' efficiency in functional code development. Nevertheless, it remains a notable concern that such tools are also responsible for creating insecure code, predominantly because of pre-training on publicly available repositories with vulnerable code. Moreover, developers are called the "weakest link in the chain" since they have very minimal knowledge of code security. Although existing solutions provide a reasonable solution to vulnerable code, they must adequately describe and educate the developers on code security to ensure that the security issues are not repeated. Therefore we introduce a multipurpose code vulnerability analysis system \texttt{SecRepair}, powered by a large language model, CodeGen2 assisting the developer in identifying and generating fixed code along with a complete description of the vulnerability with a code comment. Our innovative methodology uses a reinforcement learning paradigm to generate code comments augmented by a semantic reward mechanism. Inspired by how humans fix code issues, we propose an instruction-based dataset suitable for vulnerability analysis with LLMs. We further identify zero-day and N-day vulnerabilities in 6 Open Source IoT Operating Systems on GitHub. Our findings underscore that incorporating reinforcement learning coupled with semantic reward augments our model's performance, thereby fortifying its capacity to address code vulnerabilities with improved efficacy.
An Unbiased Transformer Source Code Learning with Semantic Vulnerability Graph
Apr 17, 2023

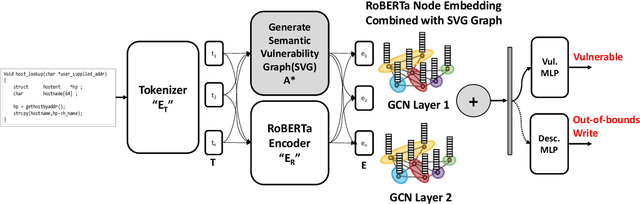

Over the years, open-source software systems have become prey to threat actors. Even as open-source communities act quickly to patch the breach, code vulnerability screening should be an integral part of agile software development from the beginning. Unfortunately, current vulnerability screening techniques are ineffective at identifying novel vulnerabilities or providing developers with code vulnerability and classification. Furthermore, the datasets used for vulnerability learning often exhibit distribution shifts from the real-world testing distribution due to novel attack strategies deployed by adversaries and as a result, the machine learning model's performance may be hindered or biased. To address these issues, we propose a joint interpolated multitasked unbiased vulnerability classifier comprising a transformer "RoBERTa" and graph convolution neural network (GCN). We present a training process utilizing a semantic vulnerability graph (SVG) representation from source code, created by integrating edges from a sequential flow, control flow, and data flow, as well as a novel flow dubbed Poacher Flow (PF). Poacher flow edges reduce the gap between dynamic and static program analysis and handle complex long-range dependencies. Moreover, our approach reduces biases of classifiers regarding unbalanced datasets by integrating Focal Loss objective function along with SVG. Remarkably, experimental results show that our classifier outperforms state-of-the-art results on vulnerability detection with fewer false negatives and false positives. After testing our model across multiple datasets, it shows an improvement of at least 2.41% and 18.75% in the best-case scenario. Evaluations using N-day program samples demonstrate that our proposed approach achieves a 93% accuracy and was able to detect 4, zero-day vulnerabilities from popular GitHub repositories.