 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reverse Engineering: Investigating and Benchmarking Large Language Models for Vulnerability Analysis in Decompiled Binaries
Nov 07, 2024Security experts reverse engineer (decompile) binary code to identify critical security vulnerabilities. The limited access to source code in vital systems - such as firmware, drivers, and proprietary software used in Critical Infrastructures (CI) - makes this analysis even more crucial on the binary level. Even with available source code, a semantic gap persists after compilation between the source and the binary code executed by the processor. This gap may hinder the detection of vulnerabilities in source code. That being said, current research on Large Language Models (LLMs) overlooks the significance of decompiled binaries in this area by focusing solely on source code. In this work, we are the first to empirically uncover the substantial semantic limitations of state-of-the-art LLMs when it comes to analyzing vulnerabilities in decompiled binaries, largely due to the absence of relevant datasets. To bridge the gap, we introduce DeBinVul, a novel decompiled binary code vulnerability dataset. Our dataset is multi-architecture and multi-optimization, focusing on C/C++ due to their wide usage in CI and association with numerous vulnerabilities. Specifically, we curate 150,872 samples of vulnerable and non-vulnerable decompiled binary code for the task of (i) identifying; (ii) classifying; (iii) describing vulnerabilities; and (iv) recovering function names in the domain of decompiled binaries. Subsequently, we fine-tune state-of-the-art LLMs using DeBinVul and report on a performance increase of 19%, 24%, and 21% in the capabilities of CodeLlama, Llama3, and CodeGen2 respectively, in detecting binary code vulnerabilities. Additionally, using DeBinVul, we report a high performance of 80-90% on the vulnerability classification task. Furthermore, we report improved performance in function name recovery and vulnerability description tasks.
Unintentional Security Flaws in Code: Automated Defense via Root Cause Analysis
Aug 30, 2024



Software security remains a critical concern, particularly as junior developers, often lacking comprehensive knowledge of security practices, contribute to codebases. While there are tools to help developers proactively write secure code, their actual effectiveness in helping developers fix their vulnerable code remains largely unmeasured. Moreover, these approaches typically focus on classifying and localizing vulnerabilities without highlighting the specific code segments that are the root cause of the issues, a crucial aspect for developers seeking to fix their vulnerable code. To address these challenges, we conducted a comprehensive study evaluating the efficacy of existing methods in helping junior developers secure their code. Our findings across five types of security vulnerabilities revealed that current tools enabled developers to secure only 36.2\% of vulnerable code. Questionnaire results from these participants further indicated that not knowing the code that was the root cause of the vulnerability was one of their primary challenges in repairing the vulnerable code. Informed by these insights, we developed an automated vulnerability root cause (RC) toolkit called T5-RCGCN, that combines T5 language model embeddings with a graph convolutional network (GCN) for vulnerability classification and localization. Additionally, we integrated DeepLiftSHAP to identify the code segments that were the root cause of the vulnerability. We tested T5-RCGCN with 56 junior developers across three datasets, showing a 28.9\% improvement in code security compared to previous methods. Developers using the tool also gained a deeper understanding of vulnerability root causes, resulting in a 17.0\% improvement in their ability to secure code independently. These results demonstrate the tool's potential for both immediate security enhancement and long-term developer skill growth.
An Unbiased Transformer Source Code Learning with Semantic Vulnerability Graph
Apr 17, 2023

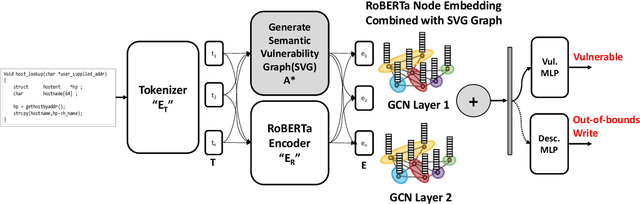

Over the years, open-source software systems have become prey to threat actors. Even as open-source communities act quickly to patch the breach, code vulnerability screening should be an integral part of agile software development from the beginning. Unfortunately, current vulnerability screening techniques are ineffective at identifying novel vulnerabilities or providing developers with code vulnerability and classification. Furthermore, the datasets used for vulnerability learning often exhibit distribution shifts from the real-world testing distribution due to novel attack strategies deployed by adversaries and as a result, the machine learning model's performance may be hindered or biased. To address these issues, we propose a joint interpolated multitasked unbiased vulnerability classifier comprising a transformer "RoBERTa" and graph convolution neural network (GCN). We present a training process utilizing a semantic vulnerability graph (SVG) representation from source code, created by integrating edges from a sequential flow, control flow, and data flow, as well as a novel flow dubbed Poacher Flow (PF). Poacher flow edges reduce the gap between dynamic and static program analysis and handle complex long-range dependencies. Moreover, our approach reduces biases of classifiers regarding unbalanced datasets by integrating Focal Loss objective function along with SVG. Remarkably, experimental results show that our classifier outperforms state-of-the-art results on vulnerability detection with fewer false negatives and false positives. After testing our model across multiple datasets, it shows an improvement of at least 2.41% and 18.75% in the best-case scenario. Evaluations using N-day program samples demonstrate that our proposed approach achieves a 93% accuracy and was able to detect 4, zero-day vulnerabilities from popular GitHub repositories.