 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Network Security Management in Water Systems using FM-based Attack Attribution
Mar 03, 2025


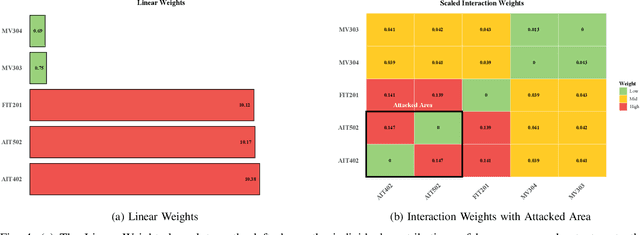
Water systems are vital components of modern infrastructure, yet they are increasingly susceptible to sophisticated cyber attacks with potentially dire consequences on public health and safety. While state-of-the-art machine learning techniques effectively detect anomalies, contemporary model-agnostic attack attribution methods using LIME, SHAP, and LEMNA are deemed impractical for large-scale, interdependent water systems. This is due to the intricate interconnectivity and dynamic interactions that define these complex environments. Such methods primarily emphasize individual feature importance while falling short of addressing the crucial sensor-actuator interactions in water systems, which limits their effectiveness in identifying root cause attacks. To this end, we propose a novel model-agnostic Factorization Machines (FM)-based approach that capitalizes on water system sensor-actuator interactions to provide granular explanations and attributions for cyber attacks. For instance, an anomaly in an actuator pump activity can be attributed to a top root cause attack candidates, a list of water pressure sensors, which is derived from the underlying linear and quadratic effects captured by our approach. We validate our method using two real-world water system specific datasets, SWaT and WADI, demonstrating its superior performance over traditional attribution methods. In multi-feature cyber attack scenarios involving intricate sensor-actuator interactions, our FM-based attack attribution method effectively ranks attack root causes, achieving approximately 20% average improvement over SHAP and LEMNA.
Enhancing Reverse Engineering: Investigating and Benchmarking Large Language Models for Vulnerability Analysis in Decompiled Binaries
Nov 07, 2024Security experts reverse engineer (decompile) binary code to identify critical security vulnerabilities. The limited access to source code in vital systems - such as firmware, drivers, and proprietary software used in Critical Infrastructures (CI) - makes this analysis even more crucial on the binary level. Even with available source code, a semantic gap persists after compilation between the source and the binary code executed by the processor. This gap may hinder the detection of vulnerabilities in source code. That being said, current research on Large Language Models (LLMs) overlooks the significance of decompiled binaries in this area by focusing solely on source code. In this work, we are the first to empirically uncover the substantial semantic limitations of state-of-the-art LLMs when it comes to analyzing vulnerabilities in decompiled binaries, largely due to the absence of relevant datasets. To bridge the gap, we introduce DeBinVul, a novel decompiled binary code vulnerability dataset. Our dataset is multi-architecture and multi-optimization, focusing on C/C++ due to their wide usage in CI and association with numerous vulnerabilities. Specifically, we curate 150,872 samples of vulnerable and non-vulnerable decompiled binary code for the task of (i) identifying; (ii) classifying; (iii) describing vulnerabilities; and (iv) recovering function names in the domain of decompiled binaries. Subsequently, we fine-tune state-of-the-art LLMs using DeBinVul and report on a performance increase of 19%, 24%, and 21% in the capabilities of CodeLlama, Llama3, and CodeGen2 respectively, in detecting binary code vulnerabilities. Additionally, using DeBinVul, we report a high performance of 80-90% on the vulnerability classification task. Furthermore, we report improved performance in function name recovery and vulnerability description tasks.
Enhancing Source Code Security with LLMs: Demystifying The Challenges and Generating Reliable Repairs
Sep 01, 2024



With the recent unprecedented advancements in Artificial Intelligence (AI) computing, progress in Large Language Models (LLMs) is accelerating rapidly, presenting challenges in establishing clear guidelines, particularly in the field of security. That being said, we thoroughly identify and describe three main technical challenges in the security and software engineering literature that spans the entire LLM workflow, namely; \textbf{\textit{(i)}} Data Collection and Labeling; \textbf{\textit{(ii)}} System Design and Learning; and \textbf{\textit{(iii)}} Performance Evaluation. Building upon these challenges, this paper introduces \texttt{SecRepair}, an instruction-based LLM system designed to reliably \textit{identify}, \textit{describe}, and automatically \textit{repair} vulnerable source code. Our system is accompanied by a list of actionable guides on \textbf{\textit{(i)}} Data Preparation and Augmentation Techniques; \textbf{\textit{(ii)}} Selecting and Adapting state-of-the-art LLM Models; \textbf{\textit{(iii)}} Evaluation Procedures. \texttt{SecRepair} uses a reinforcement learning-based fine-tuning with a semantic reward that caters to the functionality and security aspects of the generated code. Our empirical analysis shows that \texttt{SecRepair} achieves a \textit{12}\% improvement in security code repair compared to other LLMs when trained using reinforcement learning. Furthermore, we demonstrate the capabilities of \texttt{SecRepair} in generating reliable, functional, and compilable security code repairs against real-world test cases using automated evaluation metrics.
LLM-Powered Code Vulnerability Repair with Reinforcement Learning and Semantic Reward
Jan 07, 2024



In software development, the predominant emphasis on functionality often supersedes security concerns, a trend gaining momentum with AI-driven automation tools like GitHub Copilot. These tools significantly improve developers' efficiency in functional code development. Nevertheless, it remains a notable concern that such tools are also responsible for creating insecure code, predominantly because of pre-training on publicly available repositories with vulnerable code. Moreover, developers are called the "weakest link in the chain" since they have very minimal knowledge of code security. Although existing solutions provide a reasonable solution to vulnerable code, they must adequately describe and educate the developers on code security to ensure that the security issues are not repeated. Therefore we introduce a multipurpose code vulnerability analysis system \texttt{SecRepair}, powered by a large language model, CodeGen2 assisting the developer in identifying and generating fixed code along with a complete description of the vulnerability with a code comment. Our innovative methodology uses a reinforcement learning paradigm to generate code comments augmented by a semantic reward mechanism. Inspired by how humans fix code issues, we propose an instruction-based dataset suitable for vulnerability analysis with LLMs. We further identify zero-day and N-day vulnerabilities in 6 Open Source IoT Operating Systems on GitHub. Our findings underscore that incorporating reinforcement learning coupled with semantic reward augments our model's performance, thereby fortifying its capacity to address code vulnerabilities with improved efficacy.
An Unbiased Transformer Source Code Learning with Semantic Vulnerability Graph
Apr 17, 2023Over the years, open-source software systems have become prey to threat actors. Even as open-source communities act quickly to patch the breach, code vulnerability screening should be an integral part of agile software development from the beginning. Unfortunately, current vulnerability screening techniques are ineffective at identifying novel vulnerabilities or providing developers with code vulnerability and classification. Furthermore, the datasets used for vulnerability learning often exhibit distribution shifts from the real-world testing distribution due to novel attack strategies deployed by adversaries and as a result, the machine learning model's performance may be hindered or biased. To address these issues, we propose a joint interpolated multitasked unbiased vulnerability classifier comprising a transformer "RoBERTa" and graph convolution neural network (GCN). We present a training process utilizing a semantic vulnerability graph (SVG) representation from source code, created by integrating edges from a sequential flow, control flow, and data flow, as well as a novel flow dubbed Poacher Flow (PF). Poacher flow edges reduce the gap between dynamic and static program analysis and handle complex long-range dependencies. Moreover, our approach reduces biases of classifiers regarding unbalanced datasets by integrating Focal Loss objective function along with SVG. Remarkably, experimental results show that our classifier outperforms state-of-the-art results on vulnerability detection with fewer false negatives and false positives. After testing our model across multiple datasets, it shows an improvement of at least 2.41% and 18.75% in the best-case scenario. Evaluations using N-day program samples demonstrate that our proposed approach achieves a 93% accuracy and was able to detect 4, zero-day vulnerabilities from popular GitHub repositories.
Improving Borderline Adulthood Facial Age Estimation through Ensemble Learning
Jul 02, 2019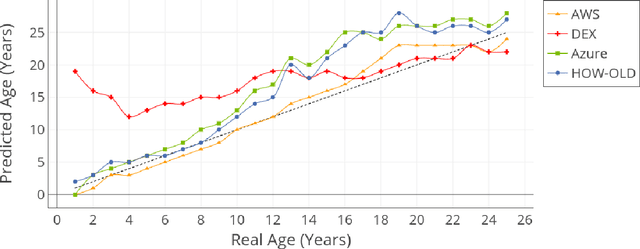
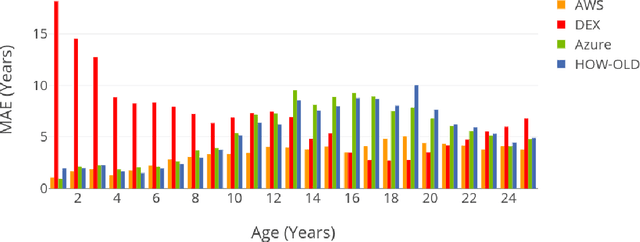
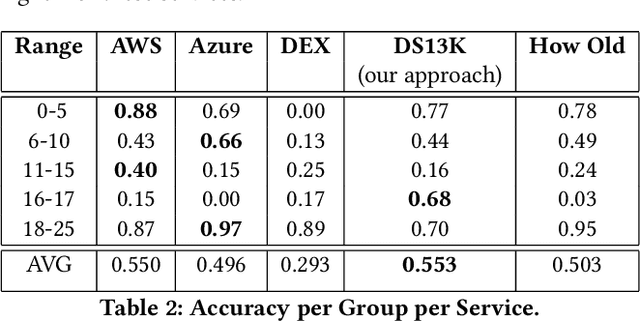

Achieving high performance for facial age estimation with subjects in the borderline between adulthood and non-adulthood has always been a challenge. Several studies have used different approaches from the age of a baby to an elder adult and different datasets have been employed to measure the mean absolute error (MAE) ranging between 1.47 to 8 years. The weakness of the algorithms specifically in the borderline has been a motivation for this paper. In our approach, we have developed an ensemble technique that improves the accuracy of underage estimation in conjunction with our deep learning model (DS13K) that has been fine-tuned on the Deep Expectation (DEX) model. We have achieved an accuracy of 68% for the age group 16 to 17 years old, which is 4 times better than the DEX accuracy for such age range. We also present an evaluation of existing cloud-based and offline facial age prediction services, such as Amazon Rekognition, Microsoft Azure Cognitive Services, How-Old.net and DEX.