 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug to Place: Indoor Multimedia Geolocation from Electrical Sockets for Digital Investigation
Dec 18, 2025



Computer vision is a rapidly evolving field, giving rise to powerful new tools and techniques in digital forensic investigation, and shows great promise for novel digital forensic applications. One such application, indoor multimedia geolocation, has the potential to become a crucial aid for law enforcement in the fight against human trafficking, child exploitation, and other serious crimes. While outdoor multimedia geolocation has been widely explored, its indoor counterpart remains underdeveloped due to challenges such as similar room layouts, frequent renovations, visual ambiguity, indoor lighting variability, unreliable GPS signals, and limited datasets in sensitive domains. This paper introduces a pipeline that uses electric sockets as consistent indoor markers for geolocation, since plug socket types are standardised by country or region. The three-stage deep learning pipeline detects plug sockets (YOLOv11, mAP@0.5 = 0.843), classifies them into one of 12 plug socket types (Xception, accuracy = 0.912), and maps the detected socket types to countries (accuracy = 0.96 at >90% threshold confidence). To address data scarcity, two dedicated datasets were created: socket detection dataset of 2,328 annotated images expanded to 4,072 through augmentation, and a classification dataset of 3,187 images across 12 plug socket classes. The pipeline was evaluated on the Hotels-50K dataset, focusing on the TraffickCam subset of crowd-sourced hotel images, which capture real-world conditions such as poor lighting and amateur angles. This dataset provides a more realistic evaluation than using professional, well-lit, often wide-angle images from travel websites. This framework demonstrates a practical step toward real-world digital forensic applications. The code, trained models, and the data for this paper are available open source.
VAAS: Vision-Attention Anomaly Scoring for Image Manipulation Detection in Digital Forensics
Dec 17, 2025



Recent advances in AI-driven image generation have introduced new challenges for verifying the authenticity of digital evidence in forensic investigations. Modern generative models can produce visually consistent forgeries that evade traditional detectors based on pixel or compression artefacts. Most existing approaches also lack an explicit measure of anomaly intensity, which limits their ability to quantify the severity of manipulation. This paper introduces Vision-Attention Anomaly Scoring (VAAS), a novel dual-module framework that integrates global attention-based anomaly estimation using Vision Transformers (ViT) with patch-level self-consistency scoring derived from SegFormer embeddings. The hybrid formulation provides a continuous and interpretable anomaly score that reflects both the location and degree of manipulation. Evaluations on the DF2023 and CASIA v2.0 datasets demonstrate that VAAS achieves competitive F1 and IoU performance, while enhancing visual explainability through attention-guided anomaly maps. The framework bridges quantitative detection with human-understandable reasoning, supporting transparent and reliable image integrity assessment. The source code for all experiments and corresponding materials for reproducing the results are available open source.
SoK: Exploring the Potential of Large Language Models for Improving Digital Forensic Investigation Efficiency
Feb 29, 2024The growing number of cases requiring digital forensic analysis raises concerns about law enforcement's ability to conduct investigations promptly. Consequently, this systemisation of knowledge paper delves into the potential and effectiveness of integrating Large Language Models (LLMs) into digital forensic investigation to address these challenges. A thorough literature review is undertaken, encompassing existing digital forensic models, tools, LLMs, deep learning techniques, and the utilisation of LLMs in investigations. The review identifies current challenges within existing digital forensic processes and explores both the obstacles and possibilities of incorporating LLMs. In conclusion, the study asserts that the adoption of LLMs in digital forensics, with appropriate constraints, holds the potential to enhance investigation efficiency, improve traceability, and alleviate technical and judicial barriers faced by law enforcement entities.
Computer Vision for Multimedia Geolocation in Human Trafficking Investigation: A Systematic Literature Review
Feb 23, 2024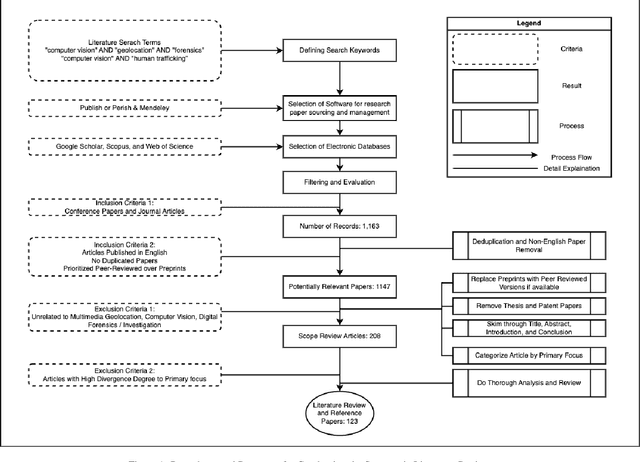
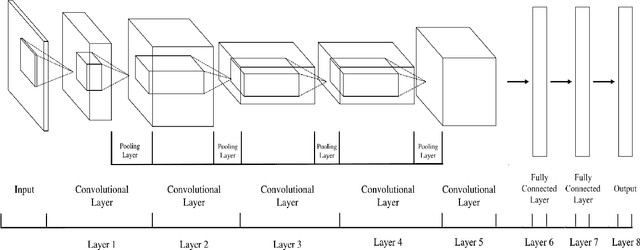

The task of multimedia geolocation is becoming an increasingly essential component of the digital forensics toolkit to effectively combat human trafficking, child sexual exploitation, and other illegal acts. Typically, metadata-based geolocation information is stripped when multimedia content is shared via instant messaging and social media. The intricacy of geolocating, geotagging, or finding geographical clues in this content is often overly burdensome for investigators. Recent research has shown that contemporary advancements in artificial intelligence, specifically computer vision and deep learning, show significant promise towards expediting the multimedia geolocation task. This systematic literature review thoroughly examines the state-of-the-art leveraging computer vision techniques for multimedia geolocation and assesses their potential to expedite human trafficking investigation. This includes a comprehensive overview of the application of computer vision-based approaches to multimedia geolocation, identifies their applicability in combating human trafficking, and highlights the potential implications of enhanced multimedia geolocation for prosecuting human trafficking. 123 articles inform this systematic literature review. The findings suggest numerous potential paths for future impactful research on the subject.
ChatGPT for Digital Forensic Investigation: The Good, The Bad, and The Unknown
Jul 10, 2023The disruptive application of ChatGPT (GPT-3.5, GPT-4) to a variety of domains has become a topic of much discussion in the scientific community and society at large. Large Language Models (LLMs), e.g., BERT, Bard, Generative Pre-trained Transformers (GPTs), LLaMA, etc., have the ability to take instructions, or prompts, from users and generate answers and solutions based on very large volumes of text-based training data. This paper assesses the impact and potential impact of ChatGPT on the field of digital forensics, specifically looking at its latest pre-trained LLM, GPT-4. A series of experiments are conducted to assess its capability across several digital forensic use cases including artefact understanding, evidence searching, code generation, anomaly detection, incident response, and education. Across these topics, its strengths and risks are outlined and a number of general conclusions are drawn. Overall this paper concludes that while there are some potential low-risk applications of ChatGPT within digital forensics, many are either unsuitable at present, since the evidence would need to be uploaded to the service, or they require sufficient knowledge of the topic being asked of the tool to identify incorrect assumptions, inaccuracies, and mistakes. However, to an appropriately knowledgeable user, it could act as a useful supporting tool in some circumstances.
Automated Artefact Relevancy Determination from Artefact Metadata and Associated Timeline Events
Dec 02, 2020

Case-hindering, multi-year digital forensic evidence backlogs have become commonplace in law enforcement agencies throughout the world. This is due to an ever-growing number of cases requiring digital forensic investigation coupled with the growing volume of data to be processed per case. Leveraging previously processed digital forensic cases and their component artefact relevancy classifications can facilitate an opportunity for training automated artificial intelligence based evidence processing systems. These can significantly aid investigators in the discovery and prioritisation of evidence. This paper presents one approach for file artefact relevancy determination building on the growing trend towards a centralised, Digital Forensics as a Service (DFaaS) paradigm. This approach enables the use of previously encountered pertinent files to classify newly discovered files in an investigation. Trained models can aid in the detection of these files during the acquisition stage, i.e., during their upload to a DFaaS system. The technique generates a relevancy score for file similarity using each artefact's filesystem metadata and associated timeline events. The approach presented is validated against three experimental usage scenarios.
Assessing the Influencing Factors on the Accuracy of Underage Facial Age Estimation
Dec 02, 2020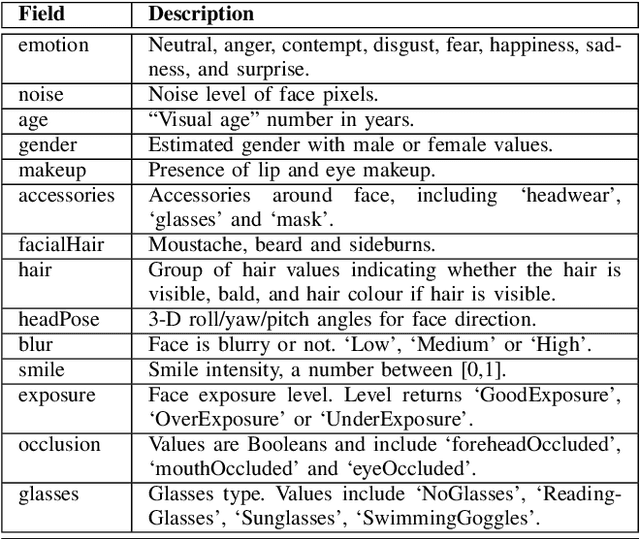
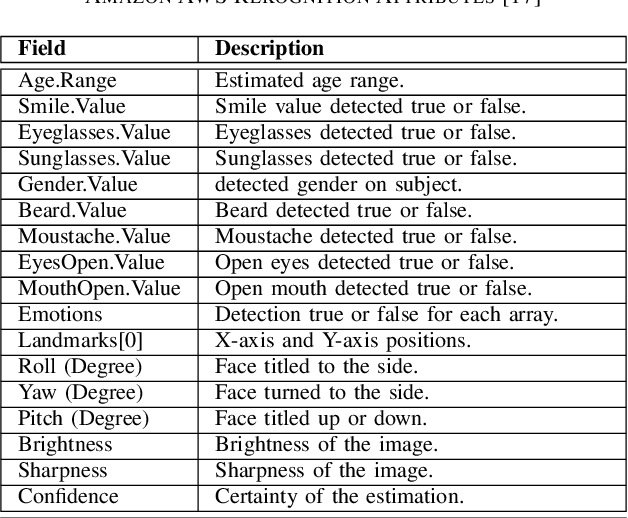
Swift response to the detection of endangered minors is an ongoing concern for law enforcement. Many child-focused investigations hinge on digital evidence discovery and analysis. Automated age estimation techniques are needed to aid in these investigations to expedite this evidence discovery process, and decrease investigator exposure to traumatic material. Automated techniques also show promise in decreasing the overflowing backlog of evidence obtained from increasing numbers of devices and online services. A lack of sufficient training data combined with natural human variance has been long hindering accurate automated age estimation -- especially for underage subjects. This paper presented a comprehensive evaluation of the performance of two cloud age estimation services (Amazon Web Service's Rekognition service and Microsoft Azure's Face API) against a dataset of over 21,800 underage subjects. The objective of this work is to evaluate the influence that certain human biometric factors, facial expressions, and image quality (i.e. blur, noise, exposure and resolution) have on the outcome of automated age estimation services. A thorough evaluation allows us to identify the most influential factors to be overcome in future age estimation systems.
SoK: Exploring the State of the Art and the Future Potential of Artificial Intelligence in Digital Forensic Investigation
Dec 02, 2020Multi-year digital forensic backlogs have become commonplace in law enforcement agencies throughout the globe. Digital forensic investigators are overloaded with the volume of cases requiring their expertise compounded by the volume of data to be processed. Artificial intelligence is often seen as the solution to many big data problems. This paper summarises existing artificial intelligence based tools and approaches in digital forensics. Automated evidence processing leveraging artificial intelligence based techniques shows great promise in expediting the digital forensic analysis process while increasing case processing capacities. For each application of artificial intelligence highlighted, a number of current challenges and future potential impact is discussed.
Improving Borderline Adulthood Facial Age Estimation through Ensemble Learning
Jul 02, 2019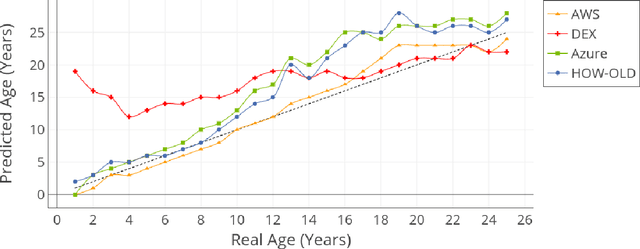
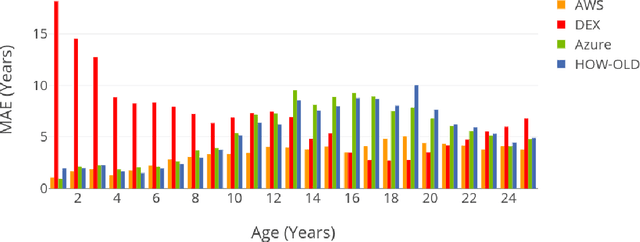
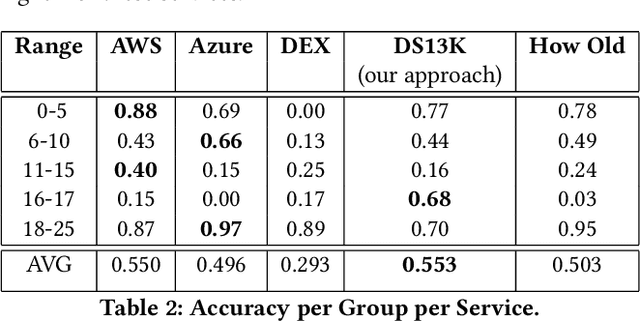

Achieving high performance for facial age estimation with subjects in the borderline between adulthood and non-adulthood has always been a challenge. Several studies have used different approaches from the age of a baby to an elder adult and different datasets have been employed to measure the mean absolute error (MAE) ranging between 1.47 to 8 years. The weakness of the algorithms specifically in the borderline has been a motivation for this paper. In our approach, we have developed an ensemble technique that improves the accuracy of underage estimation in conjunction with our deep learning model (DS13K) that has been fine-tuned on the Deep Expectation (DEX) model. We have achieved an accuracy of 68% for the age group 16 to 17 years old, which is 4 times better than the DEX accuracy for such age range. We also present an evaluation of existing cloud-based and offline facial age prediction services, such as Amazon Rekognition, Microsoft Azure Cognitive Services, How-Old.net and DEX.
Methodology for the Automated Metadata-Based Classification of Incriminating Digital Forensic Artefacts
Jul 02, 2019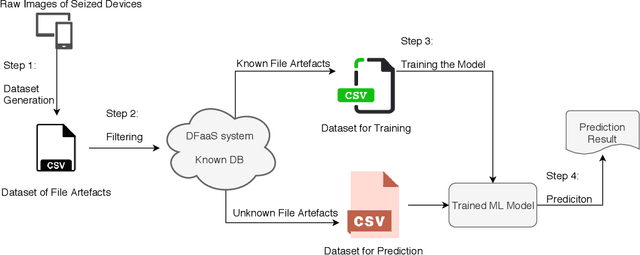
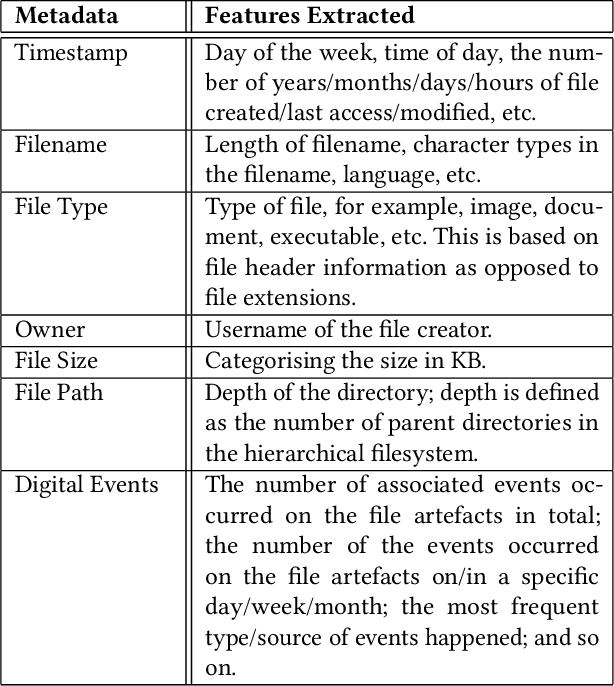
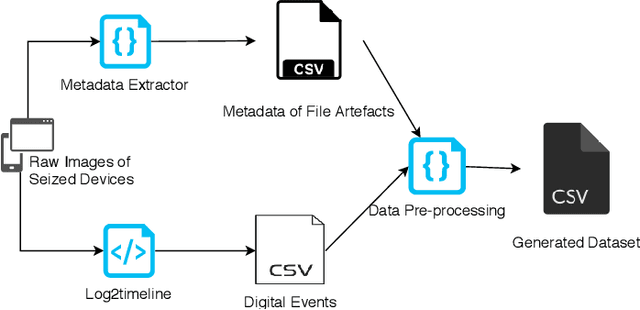

The ever increasing volume of data in digital forensic investigation is one of the most discussed challenges in the field. Usually, most of the file artefacts on seized devices are not pertinent to the investigation. Manually retrieving suspicious files relevant to the investigation is akin to finding a needle in a haystack. In this paper, a methodology for the automatic prioritisation of suspicious file artefacts (i.e., file artefacts that are pertinent to the investigation) is proposed to reduce the manual analysis effort required. This methodology is designed to work in a human-in-the-loop fashion. In other words, it predicts/recommends that an artefact is likely to be suspicious rather than giving the final analysis result. A supervised machine learning approach is employed, which leverages the recorded results of previously processed cases. The process of features extraction, dataset generation, training and evaluation are presented in this paper. In addition, a toolkit for data extraction from disk images is outlined, which enables this method to be integrated with the conventional investigation process and work in an automated fashion.