 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedundancy-Free View Alignment for Multimodal Human Activity Recognition with Arbitrarily Missing Views
Feb 09, 2026Multimodal multiview learning seeks to integrate information from diverse sources to enhance task performance. Existing approaches often struggle with flexible view configurations, including arbitrary view combinations, numbers of views, and heterogeneous modalities. Focusing on the context of human activity recognition, we propose RALIS, a model that combines multiview contrastive learning with a mixture-of-experts module to support arbitrary view availability during both training and inference. Instead of trying to reconstruct missing views, an adjusted center contrastive loss is used for self-supervised representation learning and view alignment, mitigating the impact of missing views on multiview fusion. This loss formulation allows for the integration of view weights to account for view quality. Additionally, it reduces computational complexity from $O(V^2)$ to $O(V)$, where $V$ is the number of views. To address residual discrepancies not captured by contrastive learning, we employ a mixture-of-experts module with a specialized load balancing strategy, tasked with adapting to arbitrary view combinations. We highlight the geometric relationship among components in our model and how they combine well in the latent space. RALIS is validated on four datasets encompassing inertial and human pose modalities, with the number of views ranging from three to nine, demonstrating its performance and flexibility.
Think Twice before Adaptation: Improving Adaptability of DeepFake Detection via Online Test-Time Adaptation
May 24, 2025Deepfake (DF) detectors face significant challenges when deployed in real-world environments, particularly when encountering test samples deviated from training data through either postprocessing manipulations or distribution shifts. We demonstrate postprocessing techniques can completely obscure generation artifacts presented in DF samples, leading to performance degradation of DF detectors. To address these challenges, we propose Think Twice before Adaptation (\texttt{T$^2$A}), a novel online test-time adaptation method that enhances the adaptability of detectors during inference without requiring access to source training data or labels. Our key idea is to enable the model to explore alternative options through an Uncertainty-aware Negative Learning objective rather than solely relying on its initial predictions as commonly seen in entropy minimization (EM)-based approaches. We also introduce an Uncertain Sample Prioritization strategy and Gradients Masking technique to improve the adaptation by focusing on important samples and model parameters. Our theoretical analysis demonstrates that the proposed negative learning objective exhibits complementary behavior to EM, facilitating better adaptation capability. Empirically, our method achieves state-of-the-art results compared to existing test-time adaptation (TTA) approaches and significantly enhances the resilience and generalization of DF detectors during inference. Code is available \href{https://github.com/HongHanh2104/T2A-Think-Twice-Before-Adaptation}{here}.
Passive Deepfake Detection Across Multi-modalities: A Comprehensive Survey
Nov 26, 2024In recent years, deepfakes (DFs) have been utilized for malicious purposes, such as individual impersonation, misinformation spreading, and artists' style imitation, raising questions about ethical and security concerns. However, existing surveys have focused on accuracy performance of passive DF detection approaches for single modalities, such as image, video or audio. This comprehensive survey explores passive approaches across multiple modalities, including image, video, audio, and multi-modal domains, and extend our discussion beyond detection accuracy, including generalization, robustness, attribution, and interpretability. Additionally, we discuss threat models for passive approaches, including potential adversarial strategies and different levels of adversary knowledge and capabilities. We also highlights current challenges in DF detection, including the lack of generalization across different generative models, the need for comprehensive trustworthiness evaluation, and the limitations of existing multi-modal approaches. Finally, we propose future research directions that address these unexplored and emerging issues in the field of passive DF detection, such as adaptive learning, dynamic benchmark, holistic trustworthiness evaluation, and multi-modal detectors for talking-face video generation.
D-CAPTCHA++: A Study of Resilience of Deepfake CAPTCHA under Transferable Imperceptible Adversarial Attack
Sep 11, 2024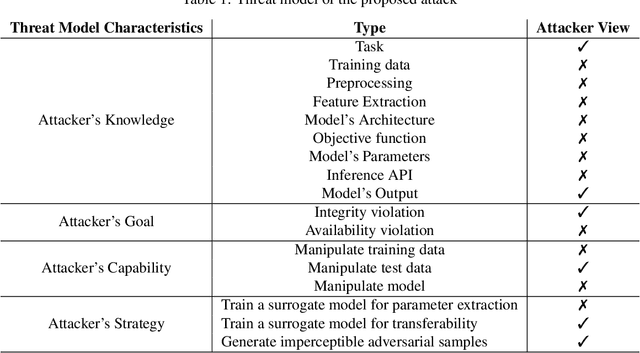
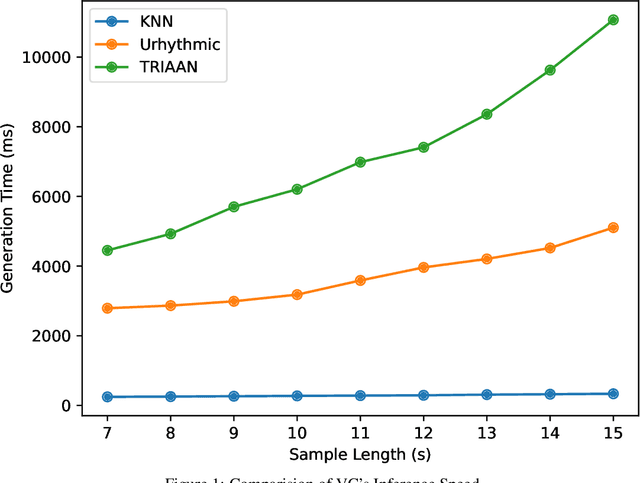
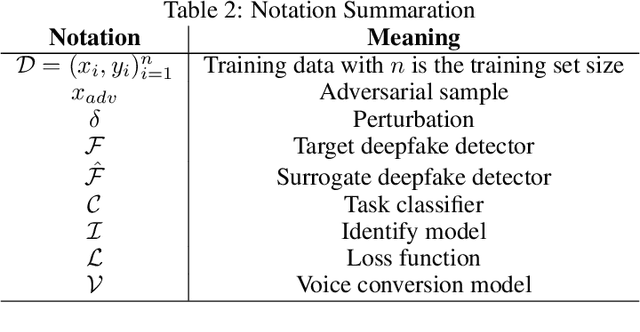
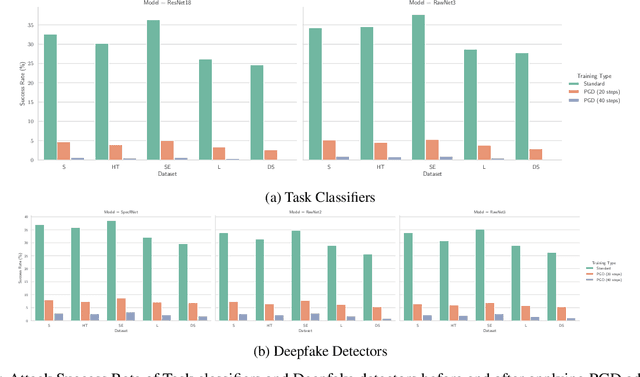
The advancements in generative AI have enabled the improvement of audio synthesis models, including text-to-speech and voice conversion. This raises concerns about its potential misuse in social manipulation and political interference, as synthetic speech has become indistinguishable from natural human speech. Several speech-generation programs are utilized for malicious purposes, especially impersonating individuals through phone calls. Therefore, detecting fake audio is crucial to maintain social security and safeguard the integrity of information. Recent research has proposed a D-CAPTCHA system based on the challenge-response protocol to differentiate fake phone calls from real ones. In this work, we study the resilience of this system and introduce a more robust version, D-CAPTCHA++, to defend against fake calls. Specifically, we first expose the vulnerability of the D-CAPTCHA system under transferable imperceptible adversarial attack. Secondly, we mitigate such vulnerability by improving the robustness of the system by using adversarial training in D-CAPTCHA deepfake detectors and task classifiers.
SoK: Behind the Accuracy of Complex Human Activity Recognition Using Deep Learning
Apr 25, 2024Human Activity Recognition (HAR) is a well-studied field with research dating back to the 1980s. Over time, HAR technologies have evolved significantly from manual feature extraction, rule-based algorithms, and simple machine learning models to powerful deep learning models, from one sensor type to a diverse array of sensing modalities. The scope has also expanded from recognising a limited set of activities to encompassing a larger variety of both simple and complex activities. However, there still exist many challenges that hinder advancement in complex activity recognition using modern deep learning methods. In this paper, we comprehensively systematise factors leading to inaccuracy in complex HAR, such as data variety and model capacity. Among many sensor types, we give more attention to wearable and camera due to their prevalence. Through this Systematisation of Knowledge (SoK) paper, readers can gain a solid understanding of the development history and existing challenges of HAR, different categorisations of activities, obstacles in deep learning-based complex HAR that impact accuracy, and potential research directions.
Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
Dec 01, 2023



Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user's motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.
Enhancing Illicit Activity Detection using XAI: A Multimodal Graph-LLM Framework
Oct 20, 2023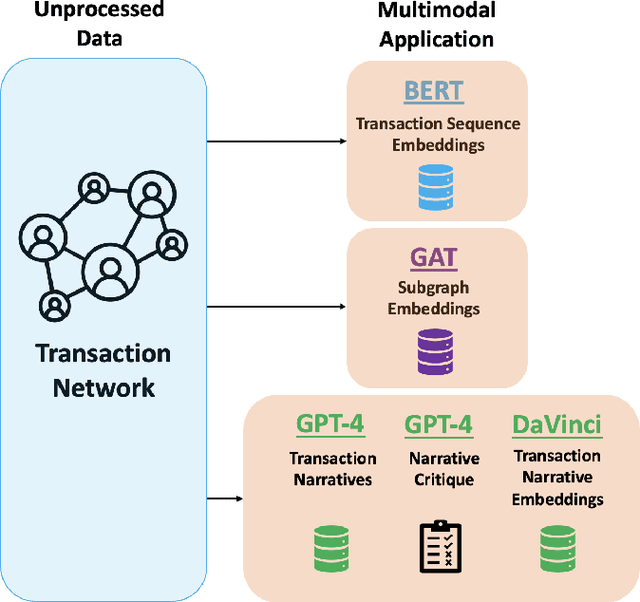

Financial cybercrime prevention is an increasing issue with many organisations and governments. As deep learning models have progressed to identify illicit activity on various financial and social networks, the explainability behind the model decisions has been lacklustre with the investigative analyst at the heart of any deep learning platform. In our paper, we present a state-of-the-art, novel multimodal proactive approach to addressing XAI in financial cybercrime detection. We leverage a triad of deep learning models designed to distill essential representations from transaction sequencing, subgraph connectivity, and narrative generation to significantly streamline the analyst's investigative process. Our narrative generation proposal leverages LLM to ingest transaction details and output contextual narrative for an analyst to understand a transaction and its metadata much further.
Crossed-IoT device portability of Electromagnetic Side Channel Analysis: Challenges and Dataset
Oct 04, 2023



IoT (Internet of Things) refers to the network of interconnected physical devices, vehicles, home appliances, and other items embedded with sensors, software, and connectivity, enabling them to collect and exchange data. IoT Forensics is collecting and analyzing digital evidence from IoT devices to investigate cybercrimes, security breaches, and other malicious activities that may have taken place on these connected devices. In particular, EM-SCA has become an essential tool for IoT forensics due to its ability to reveal confidential information about the internal workings of IoT devices without interfering these devices or wiretapping their networks. However, the accuracy and reliability of EM-SCA results can be limited by device variability, environmental factors, and data collection and processing methods. Besides, there is very few research on these limitations that affects significantly the accuracy of EM-SCA approaches for the crossed-IoT device portability as well as limited research on the possible solutions to address such challenge. Therefore, this empirical study examines the impact of device variability on the accuracy and reliability of EM-SCA approaches, in particular machine-learning (ML) based approaches for EM-SCA. We firstly presents the background, basic concepts and techniques used to evaluate the limitations of current EM-SCA approaches and datasets. Our study then addresses one of the most important limitation, which is caused by the multi-core architecture of the processors (SoC). We present an approach to collect the EM-SCA datasets and demonstrate the feasibility of using transfer learning to obtain more meaningful and reliable results from EM-SCA in IoT forensics of crossed-IoT devices. Our study moreover contributes a new dataset for using deep learning models in analysing Electromagnetic Side-Channel data with regards to the cross-device portability matter.
OAK4XAI: Model towards Out-Of-Box eXplainable Artificial Intelligence for Digital Agriculture
Sep 29, 2022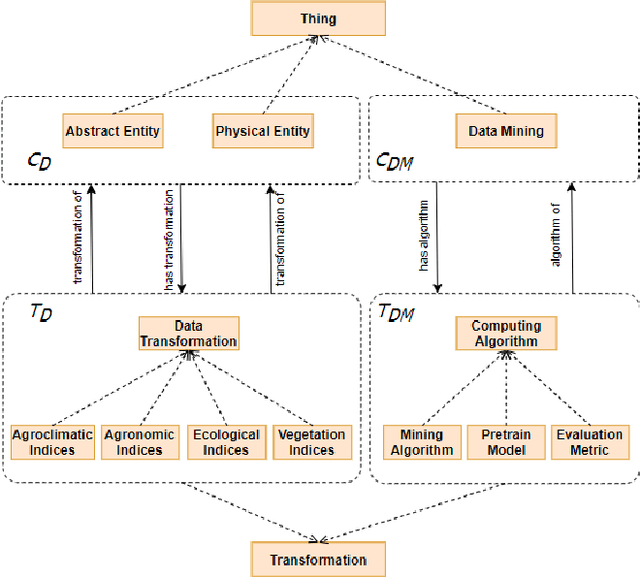

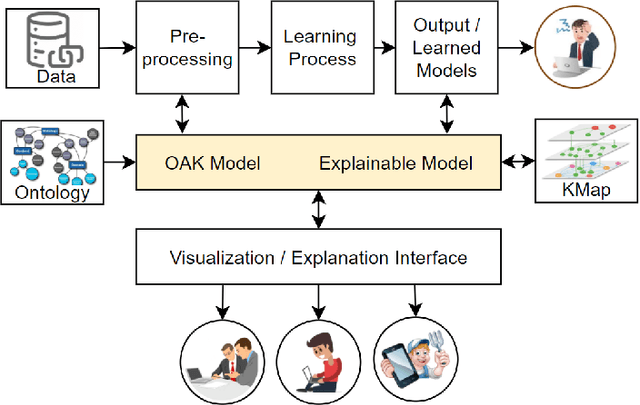
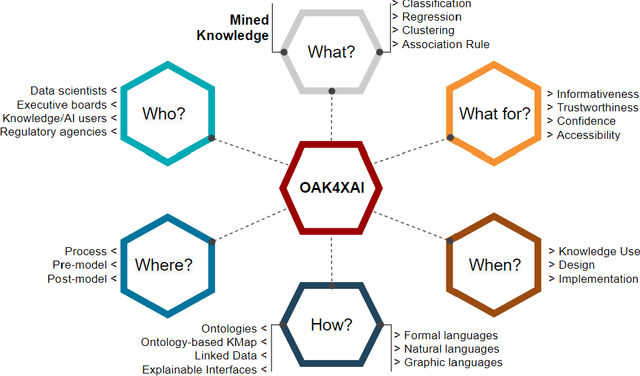
Recent machine learning approaches have been effective in Artificial Intelligence (AI) applications. They produce robust results with a high level of accuracy. However, most of these techniques do not provide human-understandable explanations for supporting their results and decisions. They usually act as black boxes, and it is not easy to understand how decisions have been made. Explainable Artificial Intelligence (XAI), which has received much interest recently, tries to provide human-understandable explanations for decision-making and trained AI models. For instance, in digital agriculture, related domains often present peculiar or input features with no link to background knowledge. The application of the data mining process on agricultural data leads to results (knowledge), which are difficult to explain. In this paper, we propose a knowledge map model and an ontology design as an XAI framework (OAK4XAI) to deal with this issue. The framework does not only consider the data analysis part of the process, but it takes into account the semantics aspect of the domain knowledge via an ontology and a knowledge map model, provided as modules of the framework. Many ongoing XAI studies aim to provide accurate and verbalizable accounts for how given feature values contribute to model decisions. The proposed approach, however, focuses on providing consistent information and definitions of concepts, algorithms, and values involved in the data mining models. We built an Agriculture Computing Ontology (AgriComO) to explain the knowledge mined in agriculture. AgriComO has a well-designed structure and includes a wide range of concepts and transformations suitable for agriculture and computing domains.
Knowledge Representation in Digital Agriculture: A Step Towards Standardised Model
Jul 15, 2022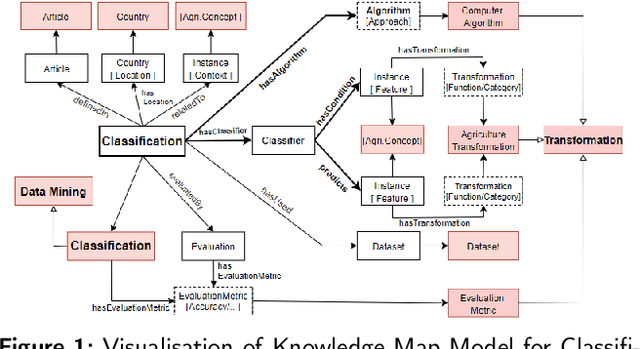
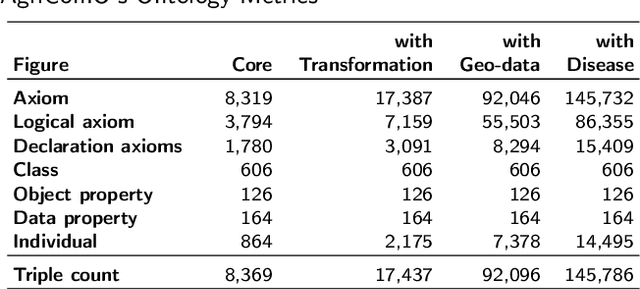
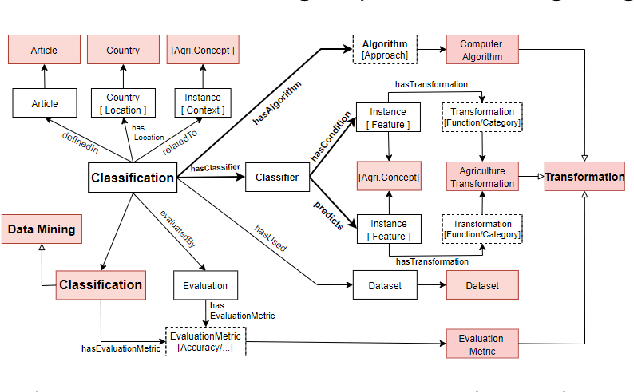

In recent years, data science has evolved significantly. Data analysis and mining processes become routines in all sectors of the economy where datasets are available. Vast data repositories have been collected, curated, stored, and used for extracting knowledge. And this is becoming commonplace. Subsequently, we extract a large amount of knowledge, either directly from the data or through experts in the given domain. The challenge now is how to exploit all this large amount of knowledge that is previously known for efficient decision-making processes. Until recently, much of the knowledge gained through a number of years of research is stored in static knowledge bases or ontologies, while more diverse and dynamic knowledge acquired from data mining studies is not centrally and consistently managed. In this research, we propose a novel model called ontology-based knowledge map to represent and store the results (knowledge) of data mining in crop farming to build, maintain, and enrich the process of knowledge discovery. The proposed model consists of six main sets: concepts, attributes, relations, transformations, instances, and states. This model is dynamic and facilitates the access, updates, and exploitation of the knowledge at any time. This paper also proposes an architecture for handling this knowledge-based model. The system architecture includes knowledge modelling, extraction, assessment, publishing, and exploitation. This system has been implemented and used in agriculture for crop management and monitoring. It is proven to be very effective and promising for its extension to other domains.