 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Based Raman Spectral Processing Technique for Exosome Classification
Apr 21, 2025Exosomes are small vesicles crucial for cell signaling and disease biomarkers. Due to their complexity, an "omics" approach is preferable to individual biomarkers. While Raman spectroscopy is effective for exosome analysis, it requires high sample concentrations and has limited sensitivity to lipids and proteins. Surface-enhanced Raman spectroscopy helps overcome these challenges. In this study, we leverage Neo4j graph databases to organize 3,045 Raman spectra of exosomes, enhancing data generalization. To further refine spectral analysis, we introduce a novel spectral filtering process that integrates the PageRank Filter with optimal Dimensionality Reduction. This method improves feature selection, resulting in superior classification performance. Specifically, the Extra Trees model, using our spectral processing approach, achieves 0.76 and 0.857 accuracy in classifying hyperglycemic, hypoglycemic, and normal exosome samples based on Raman spectra and surface, respectively, with group 10-fold cross-validation. Our results show that graph-based spectral filtering combined with optimal dimensionality reduction significantly improves classification accuracy by reducing noise while preserving key biomarker signals. This novel framework enhances Raman-based exosome analysis, expanding its potential for biomedical applications, disease diagnostics, and biomarker discovery.
Brain Tumor Segmentation in MRI Images with 3D U-Net and Contextual Transformer
Jul 11, 2024This research presents an enhanced approach for precise segmentation of brain tumor masses in magnetic resonance imaging (MRI) using an advanced 3D-UNet model combined with a Context Transformer (CoT). By architectural expansion CoT, the proposed model extends its architecture to a 3D format, integrates it smoothly with the base model to utilize the complex contextual information found in MRI scans, emphasizing how elements rely on each other across an extended spatial range. The proposed model synchronizes tumor mass characteristics from CoT, mutually reinforcing feature extraction, facilitating the precise capture of detailed tumor mass structures, including location, size, and boundaries. Several experimental results present the outstanding segmentation performance of the proposed method in comparison to current state-of-the-art approaches, achieving Dice score of 82.0%, 81.5%, 89.0% for Enhancing Tumor, Tumor Core and Whole Tumor, respectively, on BraTS2019.
Automating Attendance Management in Human Resources: A Design Science Approach Using Computer Vision and Facial Recognition
May 21, 2024Haar Cascade is a cost-effective and user-friendly machine learning-based algorithm for detecting objects in images and videos. Unlike Deep Learning algorithms, which typically require significant resources and expensive computing costs, it uses simple image processing techniques like edge detection and Haar features that are easy to comprehend and implement. By combining Haar Cascade with OpenCV2 on an embedded computer like the NVIDIA Jetson Nano, this system can accurately detect and match faces in a database for attendance tracking. This system aims to achieve several specific objectives that set it apart from existing solutions. It leverages Haar Cascade, enriched with carefully selected Haar features, such as Haar-like wavelets, and employs advanced edge detection techniques. These techniques enable precise face detection and matching in both images and videos, contributing to high accuracy and robust performance. By doing so, it minimizes manual intervention and reduces errors, thereby strengthening accountability. Additionally, the integration of OpenCV2 and the NVIDIA Jetson Nano optimizes processing efficiency, making it suitable for resource-constrained environments. This system caters to a diverse range of educational institutions, including schools, colleges, vocational training centers, and various workplace settings such as small businesses, offices, and factories. ... The system's affordability and efficiency democratize attendance management technology, making it accessible to a broader audience. Consequently, it has the potential to transform attendance tracking and management practices, ultimately leading to heightened productivity and accountability. In conclusion, this system represents a groundbreaking approach to attendance tracking and management...
Structural Textile Pattern Recognition and Processing Based on Hypergraphs
Mar 21, 2021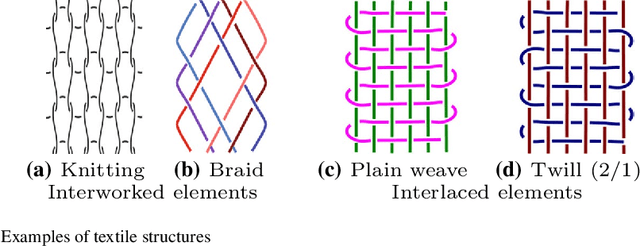
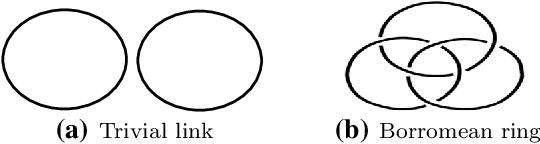


The humanities, like many other areas of society, are currently undergoing major changes in the wake of digital transformation. However, in order to make collection of digitised material in this area easily accessible, we often still lack adequate search functionality. For instance, digital archives for textiles offer keyword search, which is fairly well understood, and arrange their content following a certain taxonomy, but search functionality at the level of thread structure is still missing. To facilitate the clustering and search, we introduce an approach for recognising similar weaving patterns based on their structures for textile archives. We first represent textile structures using hypergraphs and extract multisets of k-neighbourhoods describing weaving patterns from these graphs. Then, the resulting multisets are clustered using various distance measures and various clustering algorithms (K-Means for simplicity and hierarchical agglomerative algorithms for precision). We evaluate the different variants of our approach experimentally, showing that this can be implemented efficiently (meaning it has linear complexity), and demonstrate its quality to query and cluster datasets containing large textile samples. As, to the est of our knowledge, this is the first practical approach for explicitly modelling complex and irregular weaving patterns usable for retrieval, we aim at establishing a solid baseline.
* 38 pages, 23 figures
Crop Knowledge Discovery Based on Agricultural Big Data Integration
Mar 11, 2020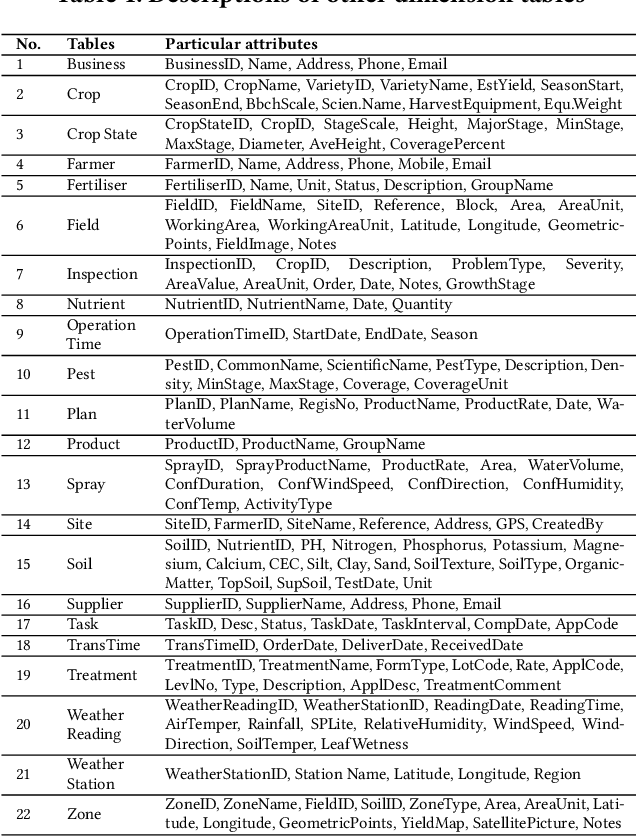
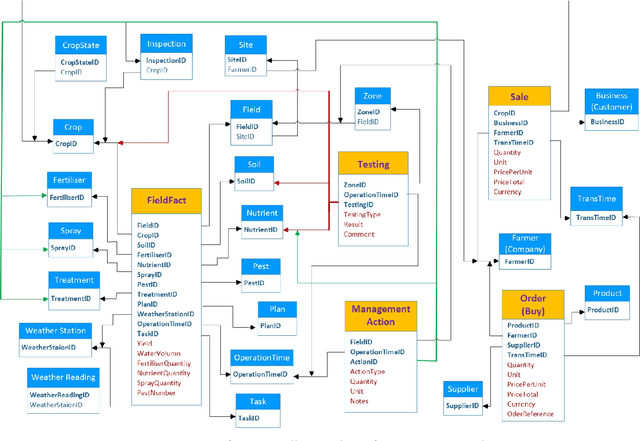
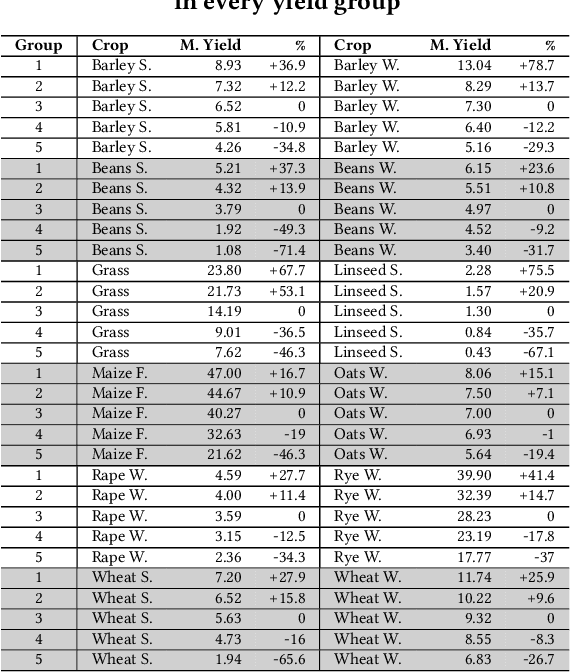
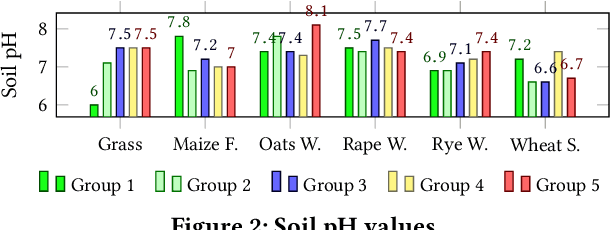
Nowadays, the agricultural data can be generated through various sources, such as: Internet of Thing (IoT), sensors, satellites, weather stations, robots, farm equipment, agricultural laboratories, farmers, government agencies and agribusinesses. The analysis of this big data enables farmers, companies and agronomists to extract high business and scientific knowledge, improving their operational processes and product quality. However, before analysing this data, different data sources need to be normalised, homogenised and integrated into a unified data representation. In this paper, we propose an agricultural data integration method using a constellation schema which is designed to be flexible enough to incorporate other datasets and big data models. We also apply some methods to extract knowledge with the view to improve crop yield; these include finding suitable quantities of soil properties, herbicides and insecticides for both increasing crop yield and protecting the environment.
* 5 pages
Designing and Implementing Data Warehouse for Agricultural Big Data
May 29, 2019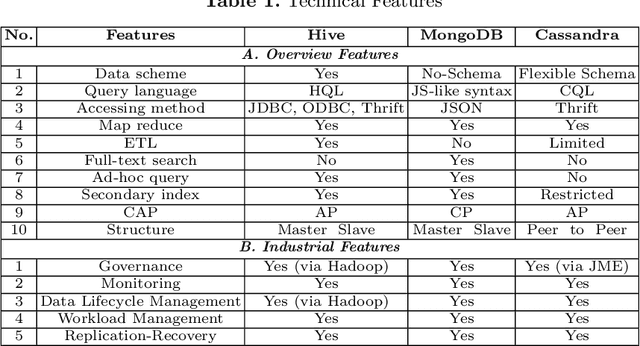
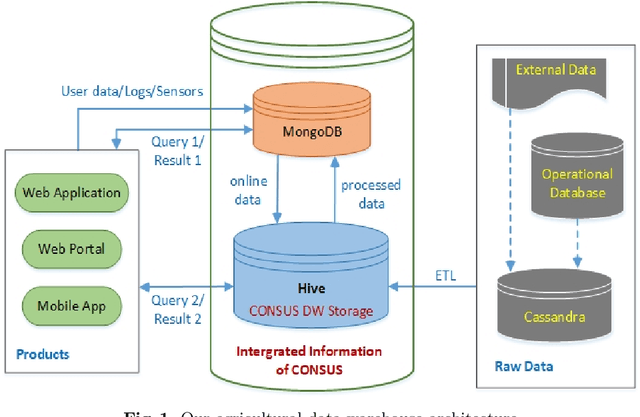
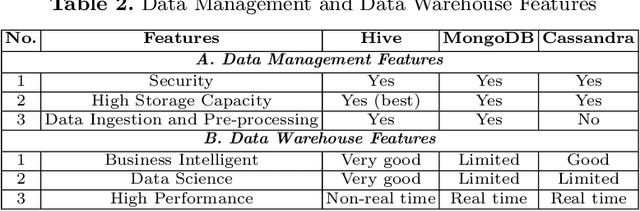
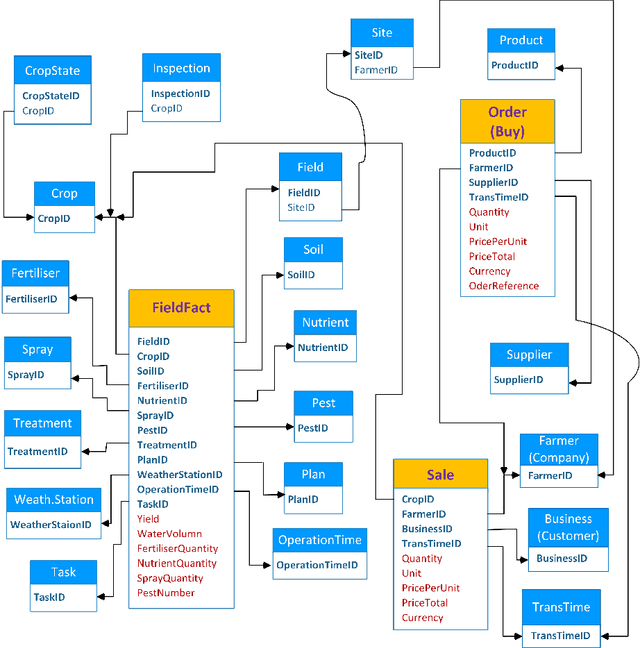
In recent years, precision agriculture that uses modern information and communication technologies is becoming very popular. Raw and semi-processed agricultural data are usually collected through various sources, such as: Internet of Thing (IoT), sensors, satellites, weather stations, robots, farm equipment, farmers and agribusinesses, etc. Besides, agricultural datasets are very large, complex, unstructured, heterogeneous, non-standardized, and inconsistent. Hence, the agricultural data mining is considered as Big Data application in terms of volume, variety, velocity and veracity. It is a key foundation to establishing a crop intelligence platform, which will enable resource efficient agronomy decision making and recommendations. In this paper, we designed and implemented a continental level agricultural data warehouse by combining Hive, MongoDB and Cassandra. Our data warehouse capabilities: (1) flexible schema; (2) data integration from real agricultural multi datasets; (3) data science and business intelligent support; (4) high performance; (5) high storage; (6) security; (7) governance and monitoring; (8) replication and recovery; (9) consistency, availability and partition tolerant; (10) distributed and cloud deployment. We also evaluate the performance of our data warehouse.
* Business intelligent, data warehouse, constellation schema, Big Data, precision agriculture
A Similarity Measure for Weaving Patterns in Textiles
Oct 10, 2018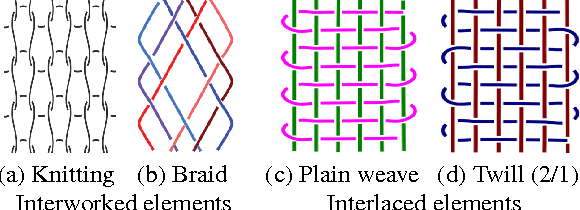

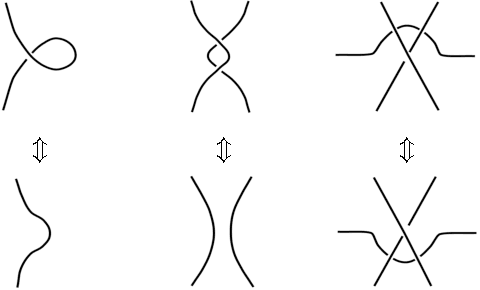
We propose a novel approach for measuring the similarity between weaving patterns that can provide similarity-based search functionality for textile archives. We represent textile structures using hypergraphs and extract multisets of k-neighborhoods from these graphs. The resulting multisets are then compared using Jaccard coefficients, Hamming distances, and cosine measures. We evaluate the different variants of our similarity measure experimentally, showing that it can be implemented efficiently and illustrating its quality using it to cluster and query a data set containing more than a thousand textile samples.
* 10 papes, will be published in SIGIR 2015
Discovering Latent Information By Spreading Activation Algorithm For Document Retrieval
Jul 29, 2018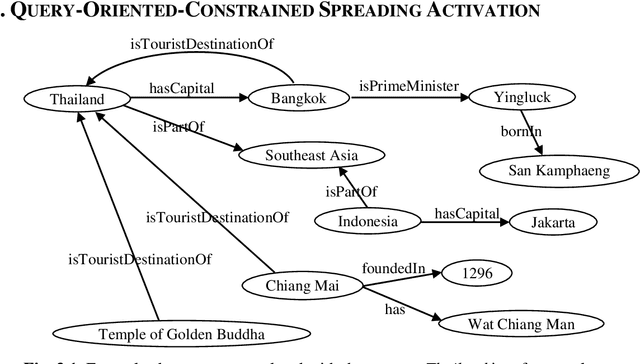
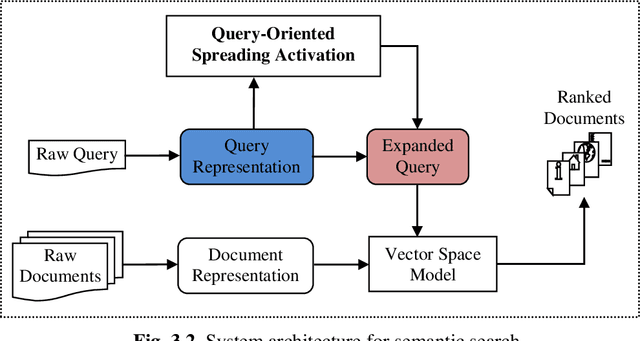
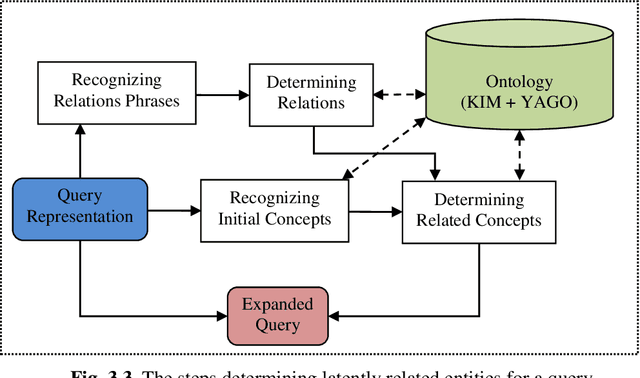
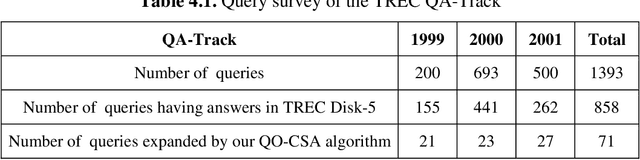
Syntactic search relies on keywords contained in a query to find suitable documents. So, documents that do not contain the keywords but contain information related to the query are not retrieved. Spreading activation is an algorithm for finding latent information in a query by exploiting relations between nodes in an associative network or semantic network. However, the classical spreading activation algorithm uses all relations of a node in the network that will add unsuitable information into the query. In this paper, we propose a novel approach for semantic text search, called query-oriented-constrained spreading activation that only uses relations relating to the content of the query to find really related information. Experiments on a benchmark dataset show that, in terms of the MAP measure, our search engine is 18.9% and 43.8% respectively better than the syntactic search and the search using the classical constrained spreading activation. KEYWORDS: Information Retrieval, Ontology, Semantic Search, Spreading Activation
A Generalized Vector Space Model for Ontology-Based Information Retrieval
Jul 20, 2018Named entities (NE) are objects that are referred to by names such as people, organizations and locations. Named entities and keywords are important to the meaning of a document. We propose a generalized vector space model that combines named entities and keywords. In the model, we take into account different ontological features of named entities, namely, aliases, classes and identifiers. Moreover, we use entity classes to represent the latent information of interrogative words in Wh-queries, which are ignored in traditional keyword-based searching. We have implemented and tested the proposed model on a TREC dataset, as presented and discussed in the paper.
Ontology-Based Query Expansion with Latently Related Named Entities for Semantic Text Search
Jul 15, 2018



Traditional information retrieval systems represent documents and queries by keyword sets. However, the content of a document or a query is mainly defined by both keywords and named entities occurring in it. Named entities have ontological features, namely, their aliases, classes, and identifiers, which are hidden from their textual appearance. Besides, the meaning of a query may imply latent named entities that are related to the apparent ones in the query. We propose an ontology-based generalized vector space model to semantic text search. It exploits ontological features of named entities and their latently related ones to reveal the semantics of documents and queries. We also propose a framework to combine different ontologies to take their complementary advantages for semantic annotation and searching. Experiments on a benchmark dataset show better search quality of our model to other ones.